2010 г.
MapReduce: внутри, снаружи или сбоку от параллельных СУБД?
Сергей Кузнецов
Назад Содержание Вперёд
3.2. Aster Data – MapReduce как основа нового механизма функций, определяемых пользователями
Как и у компании Greenplum с ее
MAD Skills, у компании Aster Data имеется свой слоган
Big Data, Fast Insight, который, по сути, означает то же самое – превращение массивно-параллельного хранилища данных в аналитическую платформу. И для этого тоже используется технология MapReduce, встроенная в СУБД. Однако, в отличие от Greenplum, эта технология применяется не для обеспечения альтернативного внешнего способа обработки данных, а для реализации нового механизма хорошо распараллеливаемых (по модели MapReduce), самоопределяемых и полиморфных табличных функций, определяемых пользователями и вызываемых из операторов выборки SQL
[30].
3.2.1. Предпосылки и преимущества использования механизма SQL/MapReduce
По мнению основных разработчиков СУБД
nCluster, декларативный язык SQL во многом ограничивает использование аналитических СУБД. С одной стороны, несмотря на постоянное наращивание аналитических возможностей этого языка, для многих аналитиков их оказывается недостаточно. С другой стороны, эти возможности постепенно становятся такими сложными и непонятными, что зачастую становится проще написать процедурный код, решающий частную аналитическую задачу. Наконец, оптимизаторы запросов SQL-ориентированных СУБД постоянно отстают от развития языка, и планы сложных аналитических запросов могут быть весьма далеки от оптимальных, что приводит к их недопустимо долгому выполнению, а иногда и аварийному завершению.
Эти проблемы частично решаются за счет поддержки в SQL-ориентированных СУБД механизма функций, определяемых пользователями (User-Defined Function, UDF). Такие функции позволяют пользователям решать внутри сервера баз данных свои прикладные задачи путем написания соответствующего процедурного кода. Однако традиционные механизмы UDF разрабатывались в расчете на "одноузловые" СУБД, и по умолчанию предполагается чисто последовательное выполнение UDF. Как упоминалось в этом разделе ранее, автоматическое распараллеливание последовательного кода в массивно-параллельной среде с разделением данных является сложной нерешенной проблемой.
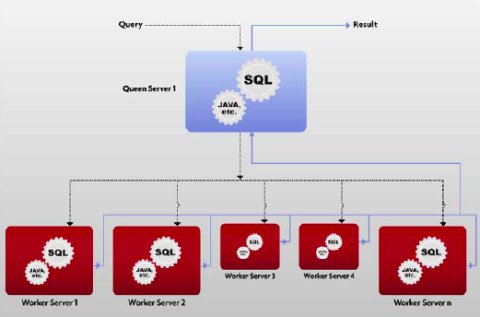
Рис. 2. Совместное выполнение SQL-запросов и SQL/MapReduce-функций в nCluster
В Aster Data для обеспечения механизма естественно распараллеливаемых UDF разработана инфраструктура SQL/MapReduce, поддерживаемая внутри SQL-ориентированной массивно-параллельной СУБД nCluster (см. рис. 2, позаимствованный из [47]). Организация среды SQL/MapReduce обеспечивает следующие возможности:
-
можно эффективно выполнять в "реляционном" стиле операции над таблицами с использованием SQL, а "нереляционные" задачи и оптимизации – возлагать на явно программируемые процедурные функции;
-
поскольку функции выполняются над согласованными данными из таблиц базы данных, обеспечивается согласованность вычислений;
-
оценочный (cost-based) оптимизатор может принимать решения о способе выполнения SQL-запросов, содержащих вызовы SQL/MapReduce-функций, на основе достоверной статистики данных;
-
пользователи nCluster могут формулировать SQL-запросы с использованием высокоуровневых средств анализа данных, воплощенных в SQL/MapReduce-функциях.
SQL/MapReduce-функции можно программировать как на традиционных языках программирования (Java, C#, C++), так и скриптовых языках (Python, Ruby). При этом, независимо от используемого языка программирования, эти функции являются самоописываемыми и полиморфными. Поскольку здесь идет речь о табличных функциях (т.е. функциях, входными параметрами и результатами которых являются таблицы), то это означает, что одна и та же функция может принимать на вход таблицы с разными схемами (функция настраивается на конкретную схему входной таблицы на этапе формирования плана запроса, содержащего ее вызов) и выдавать таблицы также с разными схемами (функция сама сообщает планировщику запроса схему своего результата на этапе формирования плана запроса). Это свойство SQL/MapReduce-функций упрощает процедуру их регистрации в системе (в частности, не требуется выполнение специального оператора SQL CREATE FUNCTION, в котором описывались бы схемы входной и выходной таблиц) и способствует повторному использованию кода.
Синтаксические особенности определения SQL/MapReduce-функций и их семантика делают эти программные объекты естественным образом параллелизуемыми по данным: во время выполнения для каждой функции образуются ее экземпляры, параллельно выполняемые в узлах, которые содержат требуемые данные. Вызовы функций подобны подзапросам SQL, что обеспечивает возможность композиции функций, при которой при вызове функции вместо спецификации входной таблицы можно задавать вызов другой функции. Наконец, внешняя эквивалентность вызова SQL/MapReduce-функции подзапросу позволяет применять при формировании плана SQL-запроса с вызовами таких функций обычную оценочную оптимизацию на основе статистики, а также динамически изменять порядок выполнения функций и вычисления настоящих SQL-подзапросов.
В следующем пункте без излишних деталей обсуждаются синтаксические конструкции, семантика и особенности реализации, обеспечивающие отмеченные свойства SQL/MapReduce-функций (более подробное описание см. в [30]).
3.2.2. Синтаксис, семантика и особенности реализации SQL/MapReduce
Обсудим, как вызываются SQL/MapReduce-функции, как они определяются, и как обрабатываются SQL-запросы с вызовами таких функций.
Синтаксис вызова SQL/MapReduce-функции
Вызов SQL/MapReduce-функции может присутствовать только в качестве элемента списка ссылок на таблицы раздела FROM SQL-запроса. Синтаксис вызова показан на рис. 3.
SELECT ...
FROM function_name(
ON table-or-query
[PARTITION BY expr, ...]
[ORDER BY expr, ...]
[clausename(arg, ...) ...]
)
...
Рис. 3. Синтаксис вызова SQL/MapReduce-функции
В разделе ON, который является единственным обязательным разделом вызова, указывается любой допустимый SQL/MapReduce-запрос (SQL-запрос, вызов SQL/MapReduce-функции или просто имя таблицы). Во время формирования плана запроса, содержащего вызов SQL/MapReduce-функции, схемой входной таблицы этого вызова считается схема результата запроса, указанного в разделе ON.
Раздел PARTITION BY указывается только в вызовах SQL/MapReduce-функций над разделами (аналоге функции Reduce исходной модели MapReduce, см. ниже). В этом случае в разделе PARTITION BY указывается список выражений, на основе значений которых производится разделение таблицы, специфицированной в разделе ON. При наличии раздела PARTITION BY в вызове может содержаться и раздел ORDER BY, указывающий на потребность в сортировке входных данных до реального вызова функции. Наконец, вслед за разделом ORDER BY можно указать произвольное число дополнительных разделов со специальными аргументами. Имена этих разделов и значения аргументов передаются в SQL/MapReduce-функцию при ее инициализации.
Модель выполнения SQL/MapReduce-функций
В среде SQL/MapReduce используется модель выполнения функций, являющаяся обобщением модели MapReduce. Функция SQL/MapReduce может быть либо функцией над строками (row function), либо функцией над разделами (partition function). Функции первого типа является аналогами функций Map классической модели MapReduce, а функции второго типа – аналогами функций Reduce. Поскольку, как отмечалось ранее, в разделе ON вызова SQL/MapReduce-функции может содержаться вызов другой SQL/MapReduce-функции, в среде SQL/MapReduce допускается любое число и любой порядок вызовов функций Map и Reduce, а не только жесткая последовательность Map-Reduce, допускаемая классической моделью.
При выполнении функции над строками каждая строка входной таблицы обрабатывается ровно одним экземпляром этой функции. С точки зрения семантики каждая строка обрабатывается независимо, поэтому входная таблица может разделяться по экземплярам функции произвольным образом, что обеспечивает возможности параллелизма и масштабирования. Для каждой строки входной таблицы функция над строками может не производить ни одной строки, а может произвести несколько строк.
При выполнении функции над разделами каждая группа строк, образованная на основе спецификации раздела PARTITION BY вызова функции, обрабатывается ровно одним экземпляром этой функции, и этот экземпляр получает все группу целиком. Если в вызове функции содержится раздел ORDER BY, то экземпляры функции получают разделы в уже упорядоченном виде. С точки зрения семантики каждая строка обрабатывается независимо, что обеспечивает возможности параллелизма на уровне разделов. Для каждого входного раздела функция над строками может не производить ни одной строки, а может произвести несколько строк.
Реализация SQL/MapReduce-функций
Как отмечалось в предыдущем пункте, для реализации SQL/MapReduce-функций можно использовать разные языки, но все они являются объектно-ориентированными. Каждая SQL/MapReduce-функция реализуется в виде отдельного класса, и при выработке плана выполнения SQL-запроса, содержащего вызовы таких функций, для каждого вызова образуется объект соответствующего класса с обращением к его методу-конструктору (инициализатору функции). Это обеспечивает настройку функции и получение требуемого описания ее результирующей таблицы.
Более точно, взаимодействие оптимизатора запросов с инициализатором функции производится через специальный объект, называемый контрактом времени выполнения (Runtime Contract). Анализируя вызов функции, оптимизатор выявляет имена и типы данных столбцов входной таблицы, а также имена и значения разделов дополнительных параметров и соответствующим образом заполняет некоторые поля объекта-контракта, который затем передается инициализатору функции. Инициализатор завершает подготовку контракта путем заполнения его дополнительных полей, содержащих, в частности, информацию о схеме результирующей таблицы, и обращается к методу complete объекта-контракта. На основе готового контракта продолжается выработка плана выполнения запроса, и этот контракт соблюдается при последующем выполнении SQL/MapReduce-функции всеми ее экземплярами.
Наиболее важными методами интерфейсов классов для функций над строками и разделами являются методы OperateOnSomeRows и OperateOnPartition. При обращении к этим методам (реальном выполнении соответствующей функции) в качестве аргументов передаются итератор над строками, для обработки которых вызывается функция, и объект emitter, с помощью вызовов которого возвращаются результирующие строки.
Чтобы можно было начать использовать некоторую SQL/MapReduce-функцию, ее нужно инсталлировать. Для этого используется общий механизм инсталляции файлов, реализованный в nCluster. Этот механизм реплицирует файл во всех рабочих узлах системы. Далее проверяется, что этот файл содержит SQL/MapReduce-функцию, а также выясняются ее статические свойства: является ли она функцией на строками или же над разделами, содержит ли она вызовы комбинатора и т.д.
Таким образом в этих двух системах обеспечивается возможность развитого анализа данных поблизости от самих данных. Разработчики серверных аналитических приложений несколько ограничиваются моделью MapReduce (в большей степени в Greenplum Database, в меньшей – в nCluster), но зато пользовательский процедурный код хорошо распараллеливается по данным в массивно-параллельной среде.
Назад Содержание Вперёд




 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС