HadoopDB: архитектурный гибрид технологий MapReduce и СУБД для аналитических рабочих нагрузок
Азза Абузейд, Камил Байда-Павликовски, Дэниэль Абади, Ави Зильбершац, Александр Разин
Перевод: Сергей Кузнецов
5. HadoopDB
В этом разделе мы описываем разработку HadoopDB. Целью этого проекта является достижение всех свойств, описанных в разд. 3.Основная идея HadoopDB состоит в связывании нескольких одноузловых систем баз данных с использованием Hadoop в качестве координатора задач и сетевого коммуникационного слоя. Запросы распараллеливаются по узлам с использованием среды MapReduce; однако как можно больший объем работы по выполнению запроса "проталкивается" в одноузловые системы баз данных. В HadoopDB отказоустойчивость и возможность функционирования в неоднородных средах достигаются путем использования реализации планирования и отслеживания заданий в Hadoop, а производительность, свойственная параллельным системам баз данных, обеспечивается за счет максимального применения при обработке запросов одноузловых СУБД.
5.1. История реализации Hadoop
Основой HadoopDB является среда Hadoop. Hadoop состоит из двух уровней: (i) уровня хранения данных, или распределенная файловая система Hadoop (Hadoop Distributed File System, HDFS) и (ii) уровень обработки данных, или среда MapReduce (MapReduce Framework).HDFS – это блочная файловая система, управляемая центральным узлом NameNode. Файлы разбиваются на блоки фиксированного размера и распределяются по нескольким узлам DataNode кластера. В NameNode поддерживаются метаданные о размере и местоположении блоков и их реплик.
MapReduce Framework основывается на простой архитектуре "главный-подчиненный" (master-slave). Главным является единственный узел JobTracker, а подчиненными, или рабочими узлами – узлы TaskTracker. В узле JobTracker выполняется планирование времени выполнения заданий MapReduce и поддерживается информация о загрузке каждого узла TaskTracker и доступных ресурсах. Каждое задание разбивается на задачи Map (их число зависит от числа блоков данных, которые требуется обработать) и задачи Reduce. JobTracker назначает задачи узлам TaskTracker исходя из требований локальности данных и балансировки нагрузки. Требование локальности удовлетворяется за счет назначения узлам TaskTracker тех задач Map, которые обрабатывают данные, являющиеся локальными для соответствующего узла. Балансировка нагрузки производится за счет того, что всем доступным узлам TaskTracker назначаются задачи. Узлы TaskTracker регулярно посылают в узел JobTracker контрольные сообщения с информацией о своем состоянии.
Интерфейс между уровнями хранения и обработки поддерживается библиотекой InputFormat. Реализации InputFormat разбирают текстовые/бинарные файлы (или подключаются к произвольному источнику данных) и преобразуют данные в пары "ключ-значение", которые могут обрабатываться задачами Map. В Hadoop обеспечивается несколько реализаций InputFormat, одна из которых позволяет всем задачам одного задания, обрабатываемого в данном кластере, обращаться к одной JDBC-совместимой базе данных.
5.2. Компоненты HadoopDB
HadoopDB расширяет Hadoop Framework (см. рис. 1) следующими четырьмя компонентами.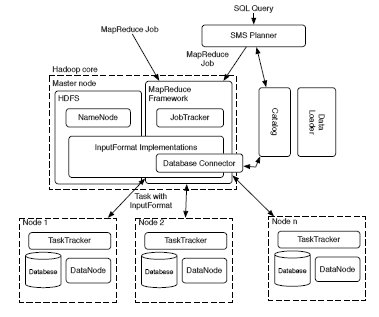
Рис. 1. Архитектура HadoopDB
5.2.1. Data Connector
Data Connector – это интерфейс между независимыми системами баз данных, располагаемыми в узлах кластера, и компонентами TaskTracker. Он расширяет класс InputFormat из Hadoop и является частью библиотеки реализаций InputFormat. От каждого задания MapReduce в коннектор поступают SQL-запрос и параметры подключения, такие как указание на требуемый драйвер JDBC, размер структуры выборки запроса и другие параметры настройки запроса. Коннектор подключается к базе данных, выполняет SQL-запрос и возвращает результат в виде пар "ключ-значение". Теоретически коннектор мог бы подключаться к любой JDBC-совместимой системе баз данных, располагаемой в кластере. Однако для разных баз данных требуются разные оптимизации запросов на выборку данных. Мы реализовали коннекторы для MySQL и PostgreSQL. В будущем мы планируем интегрировать другие СУБД, включая поколоночные системы с открытыми исходными текстами MonetDB и InfoBright. За счет расширения InputFormat из Hadoop мы обеспечиваем органичную интеграцию с MapReduce Framework. Для этой среды базы данных являются источниками данных, аналогичными блокам данных HDFS.5.2.2. Каталог
В каталоге поддерживается метаинформация о базах данных: (i) параметры соединения, такие как месторасположение базы данных, класс драйвера и учетные данные, (ii) метаданные, такие как наборы данных, содержащиеся в кластере, местоположение реплик и свойства разделения данных.В текущей реализации HadoopDB эта метаинформация сохраняется в формате XML в HDFS. К этому файлу обращаются JobTracker и TaskTracker для выборки информации, требуемой для планирования задач и обработки данных, которые требуются для запроса. В будущем мы планируем образовать для поддержки каталога отдельную службу, которая будет работать подобно NameNode в Hadoop.
5.2.3. Загрузчик данных (Data Loader)
Data Loader отвечает за (i) глобальное переразделение данных по заданному ключу при их загрузке, (ii) разбиение данных, хранимых в одном узле, на несколько более мелких разделов, или чанков (chank) и (iii) массовую загрузку данных в одноузловые базы данных с использованием чанков.Data Loader состоит из двух основных компонентов: Global Hasher и Local Hasher. Global Hasher выполняет специальное задание MapReduce в Hadoop, которое читает файлы данных, хранимые в HDFS, и переразделяет их на столько частей, сколько имеется узлов в кластере. Работа перазделения не вызывает накладные расходы сортировки типичных работ MapReduce.
Затем Local Hasher в каждом узле копирует соответствующий раздел из HDFS в локальную файловую систему узла, разделяя его на более мелкие чанки на основе заданного в системе максимального размера чанка.
В Global Hasher и Local Hasher используются разные хэш-функции, чтобы у чанков были примерно одинаковые размеры. Эти хэш-функции также отличаются от функции хэш-разделения, используемой в Hadoop по умолчанию, что обеспечивает лучшую балансировку нагрузки при выполнении заданий MapReduce над данными.
От SQL к MapReduce и планировщику SQL (SMS)
В HadoopDB аналитикам данных предоставляется внешний интерфейс, позволяющий выполнять SQL-запросы.Планировщик SMS является расширением Hive [11]. Hive преобразует HiveQL (вариант SQL) в задания MapReduce, которые подключаются к таблицам, хранимым в виде файлов HDFS. Задания MapReduce являются ориентированными ациклическими графами (directed acyclic graph, DAG) реляционных операций (таких как фильтрация, выборка (проекция), соединение, агрегирование), которые действуют как итераторы: каждая операция после обработки очередного кортежа данных направляет свой результат в следующую операцию. Поскольку каждая таблица хранится в виде отдельного файла HDFS, в Hive не предполагается совместное размещение таблиц в узлах. Поэтому операции над несколькими таблицами обычно, главным образом, выполняются на фазе Reduce задания MapReduce. Это предположение не совсем справедливо для Hadoop, поскольку некоторые таблицы размещаются в узлах совместно, и, если они разделяются по одному и тому же атрибуту, операцию соединения можно целиком вытолкнуть на уровень базы данных.
Чтобы можно было понять, каким образом Hive расширяется до SMS, и какие между ними имеются различия, сначала мы опишем, как в Hive создается выполняемое задание MapReduce для простого запроса с группировкой и агрегацией. Затем мы покажем, как мы изменяем план запроса для HadoopDB, выталкивая большую часть логики запроса на уровень базы данных. Рассмотрим следующий запрос:
SELECT YEAR(saleDate), SUM(revenue) FROM sales GROUP BY YEAR(saleDate);В Hive этот запрос обрабатывается в следующей последовательности фаз:
- Синтаксический анализатор преобразует запрос в абстрактное синтаксическое дерево.
-
Семантический анализатор подключается к внутреннему каталогу Hive MetaStore для выборки схемы таблицы
sales. Он также заполняет метаинформацией различные структуры данных (такие как классы Deserializer и InputFormat), требуемые для сканирования таблицы и извлечения необходимых полей. - Затем генератор логических планов создает DAG реляционных операций – план запроса.
- Оптимизатор перестраивает план запроса, образуя более оптимизированный план. Например, он проталкивает операции фильтрации ближе к операциям сканирования таблиц. Основной функцией оптимизатора является разбиение плана на фазы Map и Reduce. В частности, он добавляет перед операциями соединения и группировки операцию переразделения, называемую также операцией Reduce Sink. Эти операции отделяют фазу Map от фазы Reduce плана запроса. Оптимизатор Hive – это простой, бесхитростный оптимизатор, основанный на правилах (rule-based). В нем не используются методы оценочной (cost-based) оптимизации. Поэтому он не всегда генерирует эффективные планы запросов. Это создает еще одно преимущество для проталкивания как можно большей части логики обработки запросов в СУБД, в которых имеются более сложные адаптивные или оценочные оптимизаторы.
- Наконец, генератор физических планов преобразует логический план запроса в физический план, который можно выполнить в виде одного или нескольких заданий MapReduce. Первая (и каждая аналогичная) операция Reduce Sink помечает переход от фазы Map к фазе Reduce некоторого задания MapReduce, а остальные операции Reduce Sink помечают начало следующего задания MapReduce. Для приведенного выше запроса образуется одно задание MapReduce с физическим планом, показанным на рис. 2(a). Прямоугольники обозначают операции, а стрелки – потоки данных.
- Каждый DAG, ограниченный некоторым заданием MapReduce, сериализуется в XML-представление. Затем драйвер Hive выпоолняет задание Hadoop. Задания считываются из XML-плана, и создаются все требуемые объекты, сканирующие данные в таблицах HDFS и покортежно обрабатывающие данные.
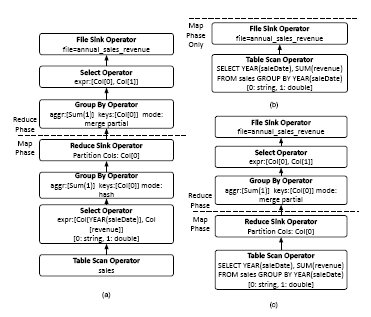
Рис. 2. (a) Задание MapReduce, генерируемое Hive; (b) задание MapReduce, генерируемое SMS, если таблица sales разделена по YEAR(saleDate) (пока эта возможность не поддерживается); (c) задание MapReduce, генерируемое SMS, если таблица sales не разделена.
Планировщик SMS является модификацией Hive. В частности, мы вмешиваемся в обычный порядок операций Hive в двух основных областях:
- До выполнения запроса мы модифицируем MetaStore, помещая в него ссылки на таблицы своей базы данных. В Hive допускается существование внешних таблиц, вне HDFS. В каталоге HadoopDB (п. 5.2.2) поддерживается информация о схемах таблиц и требуемые для MetaStore классы Deserializer и InputFormat. Мы реализовали эти классы.
- После генерации физического плана запроса и до выполнения заданий MapReduce мы производим два прохода по физическому плану. На первом проходе мы устанавливаем, какие поля данных действительно обрабатываются планом, и определяем ключи разделения, используемые в операциях Reduce Sink (переразделение). На втором проходе мы обходим DAG снизу-вверх от операций сканирования таблиц до формирования результата или операции File Sink. Все операции до первой операции переразделения с ключом разделения, отличным от ключа базы данных, преобразуются в один или несколько SQL-запросов, которые проталкиваются на уровень базы данных. Для повторного создания SQL из реляционных операций в SMS используется основанный на правилах генератор SQL. После этого логику обработки запроса можно вытолкнуть на уровень базы данных, причем эта часть работы может находиться в диапазоне от пустой (если все таблицы сканируются независимо, и кортежи по одному выталкиваются в DAG операций) до практически всей работы (задача Map требуется только для записи результата в файлы HDFS).
Для приведенного выше запроса с группировкой SMS производит один из двух разных планов. Если таблица sales является разделенной по YEAR(saleDate), производится план запроса, показанный на рис. 2(b): в этом плане вся логика обработки запроса выталкивается на уровень базы данных. Все, что требуется от задачи Map, – это запись результатов в файл HDFS. В противном случае SMS производит план, показанный на рис. 2(c), в котором на уровне базы данных производится частичная агрегация данных, и исключаются операции выборки и группировки, которые присутствуют на фазе Map в плане запроса, генерируемом Hive (рис. 2(a)). Однако в этом случае по-прежнему требуется шаг окончательной агрегации на фазе Reduce для слияния частичных результатов, полученных в каждом узле.
Для обработки запросов с соединениями в Hive предполагается отсутствие совместного размещения соответствующих таблиц. Поэтому в планах, генерируемых Hive, каждая таблица сканируется независимо, и соединение вычисляется после переразделения данных по ключу соединения. В отличие от этого, если ключ соединения совпадает с ключом разделения базы данных, SMS проталкивает на уровень базы данных все поддерево соединения.
К настоящему времени мы поддерживаем только операции фильтрации, выборки (проекции) и агрегации. Поддерживаются только исключительно бесхитростные возможности разделения; в частности, отсутствует поддержка разделения на основе выражений. Поэтому мы не можем выявить, разделена ли таблица по YEAR(saleDate), и, следовательно, вынуждены пессимистически предполагать отсутствие разделения по этому атрибуту. Следует отметить, что вариант Hive, который мы расширяли, является немного дефектным; как разъясняется в п. 6.2.5, он не справляется с выполнением задачи соединения, используемой в нашем тестовом наборе, даже при работе с таблицами из HDFS3. Однако для всех остальных тестовых запросов, использованных в наших экспериментах, которые описываются в данной статье, для автоматического проталкивания SQL-запросов на уровень СУБД системы HadoopDB использовался планировщик SMS.
5.3. Резюме
HadoopDB не заменяет Hadoop. Эти системы сосуществуют, позволяя аналитику выбирать соответствующие средства в зависимости от имеющихся данных и задач. Тестовые испытания, описываемые в следующих разделах, показывают, что использование эффективного уровня баз данных позволяет сократить время обработки, особенно при решении задач, требующих обработки сложных запросов (в частности, с соединениями) над структурированными данными. Эксперименты также показывают способность HadoopDB к отказоустойчивости и возможность использования системы в неоднородных средах, являющиеся естественными для систем в стиле Hadoop.3 Группа Hive разрешила эти проблемы в июне (2009 г.) после того как мы завершили эксперименты. Мы планируем интегрировать с SMS этот последний вариант Hive.