Методы бикластеризации для анализа интернет-данных
Дмитрий Игнатов,
кафедра анализа данных и искусственного интеллекта ГУ-ВШЭ
1.2. Типы данных
Как уже говорилось выше, исходные данные представляют собой числовую матрицу. Значения этой матрицы в зависимости от необходимого представления данных могут принадлежать множеству действительных чисел или только лишь множеству ![]() . Значительная часть алгоритмов бикластеризации работает только с бинарными данными, например, BiMax, DR-miner и все алгоритмы поиска формальных понятий и частых (замкнутых) множеств признаков. И хотя существуют техники сведения вещественных и целочисленных данных к бинарным, такие как дискретизация и шкалирование, представляется необходимым четко разделять методы по типу данных.
. Значительная часть алгоритмов бикластеризации работает только с бинарными данными, например, BiMax, DR-miner и все алгоритмы поиска формальных понятий и частых (замкнутых) множеств признаков. И хотя существуют техники сведения вещественных и целочисленных данных к бинарным, такие как дискретизация и шкалирование, представляется необходимым четко разделять методы по типу данных.
1.3. Типы бикластеров
Укажем основные типы бикластеров, которые обнаруживают различные алгоритмы бикластеризации:
- бикластер с постоянными значениями;
- бикластер с постоянными значениями по строкам или столбцам;
- бикластер с когерентными значениями;
- бикластер с когерентными изменениями.
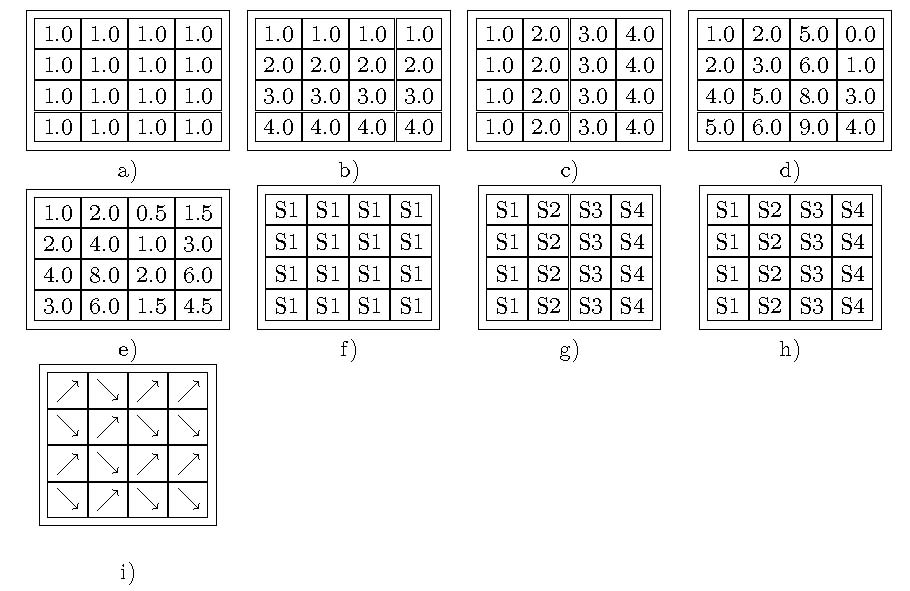{kind=link}
В таблице 1.1 приведены примеры основных типов бикластеров. Дадим пояснения:
- бикластер с постоянными значениями,
- бикластер с постоянными значениями по строкам,
- бикластер с постоянными значениями по столбцам,
- когерентные значения в рамках аддитивной модели,
- когерентные значения в рамках мультипликативной модели,
- когерентное изменение по всему бикластеру,
- когерентное изменение по строкам,
- когерентное изменение по столбцам,
- когерентное возрастание и/или убывание значений генной экспрессии.
1.4. Структура бикластеров
Среди разработанных алгоритмов представлены как те, что находят только один бикластер, так и алгоритмы, порождающие множество бикластеров. Бикластеры, входящие в такое множество, могут иметь различную структуру. Приведем перечень возможных вариантов структуры бикластеров:
- исключающие по строкам и столбцам бикластеры (прямоугольные диагональные блоки после переупорядочивания строк и столбцов);
- неперекрывающиеся бикластеры со структурой шахматной доски;
- бикластеры, исключающие пересечения по строкам;
- бикластеры, исключающие пересечения по столбцам;
- неперекрывающиеся бикластеры с древесной структурой;
- неперекрывающиеся не исключающие пересечения бикластеры;
- перекрывающиеся бикластеры с иерархической структурой;
- произвольно расположенные перекрывающиеся бикластеры.
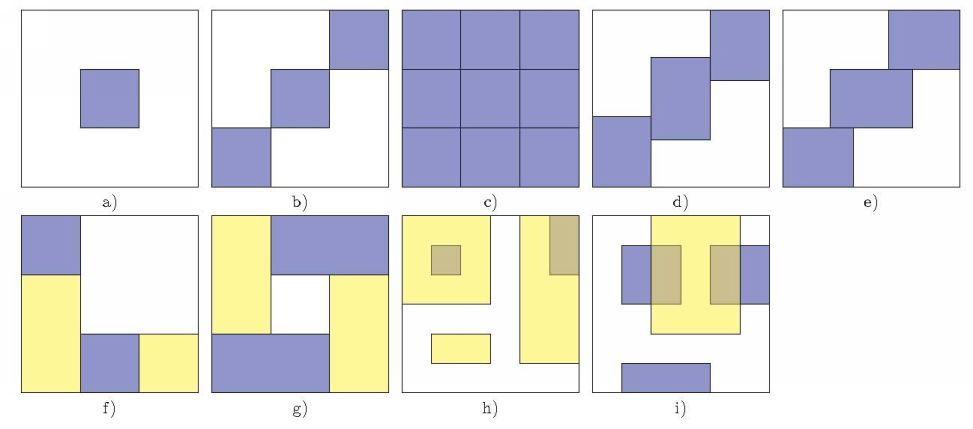{kind=link}
В таблице 1.2 проиллюстрированы различные типы структуры бикластеров. На рисунке буквой a обозначен одиночный бикластер,
- исключающие пересечения по строкам и столбцам бикластеры,
- неперекрывающиеся бикластеры со структурой шахматной доски,
- бикластеры, исключающие пересечения по строкам,
- бикластеры, исключающие пересечения по столбцам,
- неперекрывающиеся бикластеры с древесной структурой,
- неперекрывающиеся, не исключающие пересечения бикластеры,
- перекрывающиеся бикластеры с иерархической структурой и
- произвольно расположенные перекрывающиеся бикластеры.
1.5. Алгоритмические стратегии поиска
Алгоритмы бикластеризации могут порождать либо один бикластер, либо несколько, в зависимости от типа задачи. Например, алгоритм Ченга и Черча [25] находит один бикластер за проход, а для нахождения следующих необходимо маскировать найденный случайными числами и выполнить повторный запуск алгоритма. Другие бикластерные подходы позволяют находить множество бикластеров за проход. Существуют также алгоритмы, которые позволяют осуществлять одновременное выявление бикластеров.
Принимая во внимание вычислительную сложность проблемы, было предложено большое число эвристик. Эти стратегии поиска можно разделить на пять классов:
- итеративная комбинация кластеризации по строкам и столбцам;
- стратегия разделяй и властвуй;
- жадная стратегия итеративного поиска;
- полное перечисление бикластеров;
- определение параметров распределения.
1.6. Классификация методов бикластеризации
Теперь, когда четко выделены основания для классификации алгоритмов бикластеризации, построим их таксономию. В таблице 1.3 для каждого алгоритма, вошедшего в обзор, в соответствующих столбцах указаны тип бикластера, структура порождаемых бимножеств, количество бикластеров, порожденных за один запуск алгоритма, и стратегия поиска.
| Алгоритм | Тип бикластера | Структура | Порождение | Стратегия поиска |
| Block Clustering [37] | Constant | f | One Set at a Time | Div-and-Conq |
|
|
Coherent Values | i | One at a Time | Greedy |
| FLOC [84,85] | Coherent Values | i | Simultaneous | Greedy |
| pClusters [81] | Coherent Values | g | Simultaneous | Exh-Enum |
| Plaid Models [51] | Coherent Values | i | One at a Time | Dist-Ident |
| PRMs [66,67] | Coherent Values | i | Simultaneous | Dist-Ident |
| CTWC [34] | Constant Columns | i | One Set at a Time | Clust-Comb |
| ITWC [78] | Coherent Values | d,e | One Set at a Time | Clust-Comb |
| DCC [23] | Constant | b,c | Simultaneous | Clust-Comb |
|
|
Constant Rows | i | Simultaneous | Greedy |
| Spectral [45] | Coherent Values | c | Simultaneous | Greedy |
| Gibbs [68] | Constant Columns | d,e | One at a Time | Dist-Ident |
| OPSMs [16] | Coherent Evolution | a,i | One at a Time | Greedy |
| SAMBA [77] | Coherent Evolution | i | Simultaneous | Exh-Enum |
| xMOTIFs [58] [19] | Coherent Evolution | a,i | Simultaneous | Greedy |
| OP-Clusters [53] | Coherent Evolution | i | Simultaneous | Exh-Enum |
Мы используем решеточную таксономию алгоритмов, так как она лишена недостатков древесной, когда наследование свойств от различных надклассов невозможно для одного и того же подкласса. Данная таксономия построена средствами ФАП, а исходная таблица 1.3 посредством шкалирования сведена к объектно-признаковому представлению в виде бинарной матрицы.
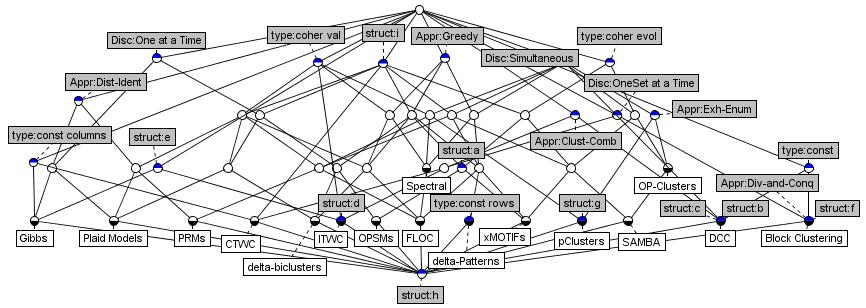{kind=link}
Мы предлагаем расширить указанную таксономию за счет введения дополнительного признака — типа исходных значений. Помимо этого, представляется желательным учесть тип бикластеров, в котором возможно присутствие некоторого числа нулевых значений, т.к. это один из способов ослабления требования к формальным понятиям. Для случая иерархической структуры бикластеров можно выделить и отдельно рассмотреть частичный (решеточный) порядок в качестве подтипа.
Для пополнения таксономии объектами мы предлагаем включить алгоритмы, используемые в ФАП для поиска формальных понятий, алгоритмы поиска частых (замкнутых) множеств признаков, алгоритм аддитивной бокс-кластеризации, DR-miner и D-miner из области DataMining, BiMax — разработанный для анализа генетических данных. Перечисленные алгоритмы, за исключением бокс-кластеризации, работают только с 0/1 данными, поэтому в таксономии им соответствует подрешетка, порожденная признаком
"![]() -данные".
-данные".
2. Модели и методы бикластеризации
2.1. Теория решёток и Формальный Анализ Понятий
Формальный Анализ Понятий — область прикладной математики, объектами исследования в которой являются (формальные) понятия и их иерархии. Прилагательное "формальный" указывает на наличие строгого математического определения понятия, как пары множеств, называемых, следуя традициям принятым в философии, объемом и содержанием. Формализация этих определений стала возможной благодаря использованию аппарата алгебраической теории решеток. Включение подраздела, посвященного ФАП, в раздел о методах и моделях бикластеризации обосновано широким спектром задач из области анализа данных, в которых ключевым является поиск бикластеров особого рода — формальных понятий. Мы не будем описывать алгоритмы ФАП в данной работе, поскольку им посвящены целые обзоры [47], а дадим лишь основные определения, составляющие основу вычислительной модели наших экспериментов.
2.1.1. Частично упорядоченные множества и решётки
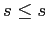 (рефлексивность);
(рефлексивность);
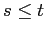 и
и 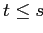 , то
, то 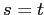 (антисимметричность);
(антисимметричность);
-
и
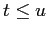 , то
, то 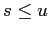 (транзитивность).
(транзитивность).
Множество S с определённым на нем отношением частичного порядка
![]() (частично упорядоченное множество) обозначается
(частично упорядоченное множество) обозначается ![]() . Если
. Если ![]() , то говорят, что элемент
, то говорят, что элемент ![]() меньше, чем
меньше, чем ![]() ,
или равен ему. Если для
,
или равен ему. Если для ![]() не существует
не существует ![]() , такого что
, такого что ![]() ,
то
,
то ![]() называют максимальным элементом
называют максимальным элементом ![]() (относительно
(относительно ![]() ).
).
Если ![]() и
и ![]() , то пишут
, то пишут ![]() и говорят, что
и говорят, что ![]() строго меньше, чем
строго меньше, чем ![]() .
.
Конечное частично упорядоченное множество ![]() может быть графически представлено с помощью диаграммы Хассе (или просто
диаграммы [1]). Элементы
может быть графически представлено с помощью диаграммы Хассе (или просто
диаграммы [1]). Элементы ![]() изображаются
в виде точек. Если
изображаются
в виде точек. Если
![]() , то
, то ![]() размещается "над"
размещается "над" ![]() (вертикальная координата
(вертикальная координата ![]() больше вертикальной координаты
больше вертикальной координаты ![]() ), и две
точки соединяются линией.
), и две
точки соединяются линией.
-
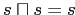 (идемпотентность);
(идемпотентность);
-
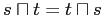 (коммутативность);
(коммутативность);
-
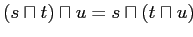 (ассоциативность);
(ассоциативность);
-
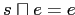 .
.
Для
![]() и
и
![]() мы пишем
мы пишем ![]() вместо
вместо
![]() . Если
. Если ![]() , то
, то
![]() .
.
Полурешёточная операция
Тогда множество с определённой на нем полурешёточной операцией
Очевидно, что система замыканий (относительно ![]() )
) ![]() с
определённой на ней операцией,
с
определённой на ней операцией,
![]() и
и
![]() , образует полурешётку.
, образует полурешётку.
Операции ![]() и
и ![]() называют операциями взятия точной
нижней и верхней грани в решётке, или инфимума и супремума соответственно.
называют операциями взятия точной
нижней и верхней грани в решётке, или инфимума и супремума соответственно.
Полурешёточные операции ![]() и
и ![]() удовлетворяют в решётках
следующему условию:
удовлетворяют в решётках
следующему условию:
![]() (поглощение).
(поглощение).
Из любой конечной полурешётки можно получить решётку добавлением одного (максимального или минимального в зависимости от типа полурешетки) элемента.
Решётка называется полной, если у каждого подмножества его элементов есть супремум и инфимум (всякая конечная решётка является полной).
Элемент ![]() решётки называется инфимум-неразложимым или
решётки называется инфимум-неразложимым или ![]() -неразложимым (или неразложимым в
пересечение), если для любых
-неразложимым (или неразложимым в
пересечение), если для любых ![]() и
и ![]() , не
выполняется
, не
выполняется
![]() . Элемент
. Элемент ![]() решётки называется супремум-неразложимым или
решётки называется супремум-неразложимым или ![]() -неразложимым (или неразложимым в объединение), если для любых
-неразложимым (или неразложимым в объединение), если для любых ![]() и
и ![]() не выполняется
не выполняется
![]() .
.
Подмножество ![]() полной решётки
полной решётки ![]() называется инфимум-плотным,
если
называется инфимум-плотным,
если
![]() , и супремум-плотным, если
, и супремум-плотным, если
![]() ).
).
-
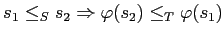 ;
;
-
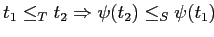 ;
;
-
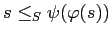 и
и
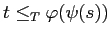 .
.