"Суета сует, все суета! Что пользы человеку от трудов его, которыми трудится он под солнцем?" - велик Екклезиаст… Велик и пессимистичен - "Всему свое время… время разрушать, и время строить; время разбрасывать камни, и время собирать камни" (Экл. 3, 1 5).
Не знаю, как другим поколениям, но, как мне кажется, нашему поколению хочется собирать. Мы слишком много занимались анализом, мы слишком много разделяли, расчленяли, мы очень много экспериментировали. Кажется, что настало время синтеза.
Но, прежде чем перейти к синтезу, хотелось бы коротко проанализировать то, что появилось в СУБД ЛИНТЕР нового и что изменилось за прошедший год.
Не будем перечислять массу мелких изменений, а остановимся на наиболее значимых и на тех новых возможностях, которые были реализованы по просьбам наших пользователей.
Для изменения параметров мандатной защиты введена конструкция SET SESSION DEFAULT SECURITY, которая позволяет изменить уровни доступа по умолчанию для сессии.
Реализована шифрация файлов базы данных. Поддерживаются алгоритмы AES, DES, ГОСТ. В дальнейшем этот список может быть расширен.
В подсистему обработки графической информации введена поддержка обобщённого типа GEOMETRY.
В подсистему фразового поиска добавлена возможность поиска с учётом расстояния между словами.
Частично переработана подсистема горячего резервирования. Уменьшено время восстановления резервного сервера. Добавлена поддержка нескольких групп резервных серверов.
Реализована возможность автоматического определения параметров запуска ядра ЛИНТЕР - объёма выделяемой памяти и размеров очередей ядра. Добавлена возможность выделения для процессов сортировки пула более 256М.
Также расширен список поддерживаемых платформ - добавились 64-х разрядные Linux и FreeBSD.
Более подробно хочется остановиться на распределённом выполнении запросов. А именно на выполнении SELECT-запросов к таблицам, расположенным на различных узлах распределённой БД.
При построении плана запроса, на начальном этапе декомпозиции анализируются все отношения, входящие в запрос, на предмет того, являются ли они удалёнными. Если все отношения являются удалёнными и расположены на одном и том же узле, то запрос целиком передаётся на этот узел и там выполняется. Если же только часть из них являются удалёнными, либо они расположены на разных узлах, то отдельные предикаты условия WHERE и подзапросы, которые могут быть вычислены на удалённых узлах, передаются для выполнения на эти узлы в асинхронном режиме.
Это наш первый шаг в сторону кластеров, и Grid-вычислений. Шаг небольшой, но на наш взгляд, очень важный.
Время синтеза
Люди придумали системы управления базами данных, и тут же разделились по странам, операционным системам, фирмам, моделям данных… А ещё были (да и сейчас ещё есть) ортодоксы, которые вообще не признавали обобщённых универсальных систем. Такие системы казались им недостаточно гибкими и быстрыми, а главное - ненужными, потому что и без них всё можно закодировать так, "чтоб летало".
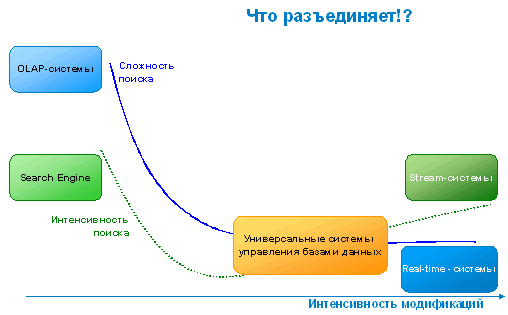
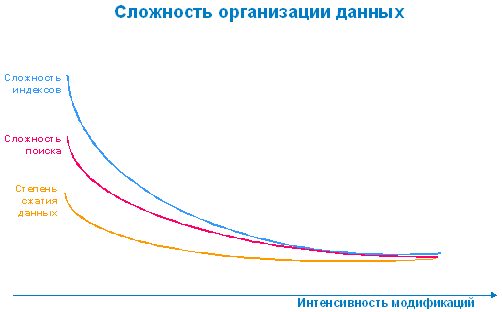
И действительно, если мы посмотрим на общий график, то непременно покажется, что все эти разделения вполне обоснованы. ЧТО ИНАЧЕ И БЫТЬ НЕ МОЖЕТ!…
Более того, все мы прекрасно знаем, что с усложнением запросов усложняется и база данных, и, напротив, интенсивный ввод требует простейшего устройства, тут уж "не до жиру", суметь бы как можно быстрее "втолкнуть" новую информацию.
Если перечислить типы индексов, которые требует для себя аналитическая система, то получится достаточно длинный список, в то время как в правой части нашего графика интенсивности модификаций мы сможем иметь исключительно hash индекс, т.е. наиболее простое, наименее трудоёмкое и ресурсоёмкое.
Даже универсальные системы отделены от указанных крайностей. Все они относительно бедны индексами - обычно две-три разновидности, реже - более.
Сжатием данных универсальные СУБД также не блещут. Практически все системы представляют весьма скудные наборы методов сжатия, которые можно перечислить на пальцах одной руки.
Видно, что разделение типов СУБД порой проходит прямо по "телу" какой-то из систем. Кто-то позволяет строить JOIN индексы, но… на их использование обычно накладывается большое количество ограничений. MySQL предоставляет достаточно разнообразное сжатие, правда, опять же есть ограничение - только для read-only таблиц. Да, мы допускаем ускорение и усложнение поисковых запросов, но должны при этом идти на сильное ограничение или вообще запрет модификации данных, выбираемых подобными запросами.
Что предлагает здесь компания РЕЛЭКС? Мы предлагаем воспользоваться синтезом, интеграцией, двух (а возможно и большего числа) систем. Одна из них - это традиционная СУБД ЛИНТЕР, которая уже достаточно зарекомендовала себя скорее в правой части нашего слайда. Другая - ROLAP система с рабочим названием SLICESYS. Точнее говоря ядро для построения OLAP систем, DWH и DSS. Справедливости ради нужно отметить, что речь всё таки идёт о Read Only реляционной СУБД.
SLICESYS - новая разработка фирмы РЕЛЭКС, ориентированная как раз на левую часть пространства СУБД, т.е. на Read Only системы и аналитические приложения.
Главное при этом - это взаимодействие между двумя системами. База данных SLICESYS состоит из отдельных кусочков, называемых инкрементами. Каждый из них имеет ту же самую структуру, что и основная база. Это сжатые по отдельности порции новой информации из материнской базы.
В данном случае в качестве материнской базы данных выступает СУБД ЛИНТЕР. Однако это может быть не только ЛИНТЕР. В принципе, на источник данных не накладывается каких-либо ограничений.
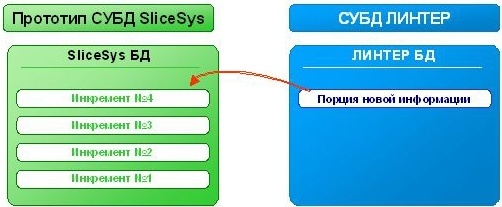
Репликация данных в OLAP-систему
Сжатие при этом может быть самым разнообразным - от межстолбцевого до локального, ограниченного рамками одной страницы. Для увеличения скорости декодирования формируются внешние исполняемые модули. Причём как упаковка, так и программы декодирования подготавливаются именно для той платформы, где будет работать SLICESYS.
Рисунок. Сжатие данных в SLICESYS.
Коэффициент сжатия данных в SLICESYS может достигать очень больших значений, недостижимых для универсальных систем. В среднем, типичные для таких задач наборы данных сжимаются в 6-20 раз, а возможно и более. Причём это вместе с индексными структурами(!)
Собственно, в этом подходе к такого рода СУБД мало нового. Все разработчики подобных систем идут по пути максимального, по возможности, сжатия данных для предельного уменьшения или даже сведения на нет процессов ввода вывода. Примеров подобных систем много, но наиболее похожим в чём-то можно считать Sybase IQ.
Хочу обратить внимание, что использование SLICESYS как дополнительного инструмента исследования имеет смысл только для тех приложений, которые имеют сложность OLAP, для хранилищ данных (DWH) и систем поддержки принятия решений (DSS) на их основе. Для таких приложений затраты на поиск и сжатие новых данных на порядок меньше, нежели затраты на обработку полученных данных.
Например, в Областном управлении ГИБДД требуется почти 8 часов для подготовки месячного отчёта. Но тот же самый отчёт в SLICESYS базе требует всего около часа. И это вместе со сжатием и перекачкой данных.
Налицо серьёзное ускорение процесса обработки данных, при этом освобождаются ресурсы основного сервера для выполнения рутинных каждодневных операций обновления.
Очевидно, что такой подход СИНТЕЗИРУЕТ "НОВУЮ" ТЕХНОЛОГИЮ работы с информацией. Особенно сейчас, когда стремительно развиваются мобильные технологии, позволяющие сотруднику компании работать практически где угодно.
Вы можете отдыхать, обедать в кафе или ехать в транспорте, а в это время на ваш ноутбук будет закачиваться новая порция сжатой информации.
Исследования IT-консалтинговой компании NOP World Technology показывают, что возможность работать там, где требуется, приводит к экономии почти 80 минут рабочего времени в день на каждого сотрудника. В денежном выражении это исчисляется от $95 до $1420 в месяц в зависимости от величины компании…
У нас в России эта экономия обычно на порядок меньше. Но даже если бы эта экономия была сведена на нет, то об этом стоит подумать, так как мир движется именно в этом направлении. И ценность мобильного работника всё время возрастает.
Здесь будет уместным поговорить о DOLAP (Desktop OLAP). Причём в несколько ином, можно сказать в "новом" понимании этого термина. Обычно, говоря про desktop OLAP, подразумевается некий недо-OLAP : небольшие объёмы, малые размерности, невысокая сложность и низкая эффективность.
Все эти недостатки являются следствием ограниченности ресурсов персональных рабочих станций и мобильных компьютеров - скромными возможностями ввода/вывода, относительно небольшим объёмом оперативной памяти и дисков. При этом в распоряжении пользователя имеются неплохие вычислительные ресурсы.
Использование систем, подобных SLICESYS, позволит частично стереть эти границы и расширить область применения Desktop OLAP. 100-гигабайтный диск обычного ноутбука позволит иметь "на борту" до терабайта (возможно и более, компания Fujitsu выпустила жесткий диск для ноутбуков емкостью 200 гигабайт!) данных, появится возможность удерживать в кеше гигантские по "ноутбучным" меркам объёмы и обрабатывать их с высокой скоростью.
В некотором роде можно говорить о Desktop DWH. Хотя такой термин выглядит несколько нелепо, но как ещё можно назвать базу данных объёмом в несколько терабайт?
С другой стороны SLICESYS является не совсем Read-Only системой. Что это означает? Это означает широкие возможности для администрирования структур, обеспечивающих скорость поиска. Проще говоря, индексных структур базы данных.
Однако можно перестраивать не только индексы. Можно до некоторой степени, модифицировать и структуру хранения данных, располагая или сжимая их так, чтобы максимально ускорить определённые виды поиска. Однако, при этом, сами данные, то есть, собственно, суть изменению не подлежат.
Таблицы баз данных OLAP имеют большое количество атрибутов, а в обработку запросов обычно вовлечено лишь их небольшое подмножество. Поэтому уместно вертикально секционировать данные и хранить их по столбцам (так делает, например, Sybase IQ).
Как нам кажется, ещё более эффективным может быть смешанное хранение таблицы - когда "пассивные" столбцы (не участвующие в условиях и вычислении агрегатов) можно хранить покортежно, а "активные" столбцы лучше всего хранить поатрибутно.
Главная проблема здесь - это проблема администрирования, т.е. создание такой утилиты, которая бы позволяла видеть и понимать, какие из индексов необходимы для скорейшего разрешения конкретного класса запросов. Ну и, конечно же, проблема в оптимизаторе, которому доступна обработка и сравнение всего этого разнообразия индексов.
Рисунок. Индексная анатомия обработки запроса.
Из этого следует то, что индекс уже не есть часть данных, ускоряющая доступ к ним. По нашему мнению, мы культивируем неверный термин - "МЕТОД ДОСТУПА", но пока что именно так переводится с английского фраза "ACCESS METHOD", когда речь идёт об индексах.
В современном понимании индекс лучше трактовать как обобщенную структуру, позволяющую ускорять обработку некоторого множества запросов. И здесь речь может не идти о доступе к данным с целью их скорейшей выборки, но об ускорении обработки уже полученных данных. Например, данные уже отобраны (читай, найдены) и нам необходимо ускорить их суммирование или получение усреднённого значения.
Ведь эта операция - такая же часть запроса, как и другие прочие. Она ничем не хуже, и часто важнее. Например, очень интересные результаты при вычислении агрегатов может дать использование Bit-Sliced индексов. Или применение похожих структур для группировок - Grouping-Set индексов.
Да и сами традиционные индексы могут иметь совершенно неожиданные причудливые, на первый взгляд, формы.
Рисунок. Примеры синтетических индексов.
Мы называем такие индексы синтетическими.
Собственно и описание таких индексов стало более естественным и декларативным.
Примеры запросов на построение индексов:
CREATE INDEX IND1 FOR QUICK (SELECT *
FROM A
WHERE A.I < ?);
CREATE INDEX IND2 FOR QUICK (SELECT A.J
FROM A
WHERE A.I = ?);
CREATE INDEX IND3 FOR QUICK (SELECT *
FROM A,B
WHERE A.I = B.I);
CREATE INDEX IND4 FOR QUICK (SELECT A.J, B.J, AGG(*)
FROM A, B
WHERE A.K = ? AND A.I = B.I
GROUP BY A.J, B.J);
Пока такие декларации ограничены только одним уровнем (без подзапросов, без внешних ссылок и т.п.), но это связано опять-таки с основными проблемами - проблемой администрирования и проблемой оптимизации.
Ось формализованности данных
Теперь хочется остановиться на ещё одной оси координат, которую очень многие хорошо ощущают. Это ось формализованности данных (см. ниже).
Почему-то именно в последнее время стали появляться новые источники информации. Раньше мы и не предполагали возможность их появления и тем более существенности этих источников, а теперь жизнь без их учёта просто немыслима…
Добавим к этому многочисленные факты появления в Европе художественных выставок коллажей, про которые, казалось бы, все забыли ещё в начале прошлого века… А ещё появилось такое новомодное слово МЕГАПОРТАЛ, которого ещё совсем недавно не было и в помине.
Разнородная, на первый взгляд, информация странным образом объединяется, синтезируя новые формы, новые структуры, новые данные…
Информатика в этом смысле всё более напоминает старушку медицину. На последнюю ещё совсем недавно возлагались такие большие надежды… Но нет. Чем сильнее медицина становится, тем больше начинают болеть люди.
Так и в информатике. Появляются новые способы обработки информации, а следом за ними появляются новые устройства и процессы, генерирующие и интегрирующие информацию. И конца этому нет. Это уже не обработка информации о внешнем мире… Это, в большей степени, обработка информации о нас самих или о том, как мы себе представляем внешний мир.
Мы сами и источники информации, и её потребители. Как та змея, которая кусает свой хвост. Люди вошли в бесконечный цикл, бесконечно порождая новую информацию и так же ненасытно поглощая её. Энтропия растёт, и как бы человек не старался навести порядок, любыми своими действиями мы только увеличиваем хаос.
Так что за нашу обустроенность, как разработчиков ПО, и бесконечную востребованность можно не сомневаться.
Но, обратите внимание, что на этой оси достаточно востребована только правая часть. Т.е. всё, что относится к достаточно структурированной информации.
Рисунок. Ось формализованности данных.
В левой же части остаётся только поиск релевантных данных, да ещё алгоритмы кластеризации. Очевидно, что так или иначе человеческий мозг пытается найти хоть какие-то закономерности в общей "свалке" разнородной информации.
Здесь, в левой части, только три простые возможности: ПОИСК МАКРО ЗАВИСИМОСТЕЙ, ПОИСК МИКРО ЗАВИСИМОСТЕЙ и ПОИСК ОТКЛОНЕНИЙ от макро зависимостей.
Хорошо видеть, что речь идёт о двух двойственных или "параллельных" мирах.
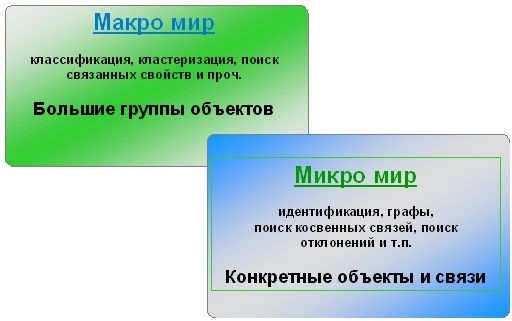
Параллельные миры.
Но оба эти "мира" необходимы для исследователей, ведущих поиск закономерностей. Для исследователя важны не только общие, не только глобальные законы. Любое отклонение от нормы, так или иначе, ставит вопросы, которые требуют ответов и объяснений.
Это особенно важно именно в наше время. Время очень непростое с точки зрения отклонений от нормы. Мир стал шире, динамичнее, многообразнее. Имеет уже смысл говорить об атаках отклонений на устойчивые кластеры.
Поэтому сейчас, как никогда раньше, стали важны информационные системы поиска закономерностей. Системы поиска структуры. Системы, которые позволяют пользователю постепенно структурировать "свалку" фактов, коллекцию данных.
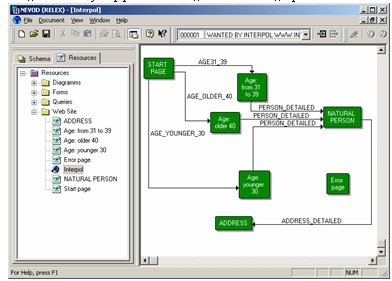
Такова информационно-аналитическая система НЕВОД.
Первоначально она строилась для использования в силовых структурах. Мы её ориентировали в помощь следователю при поиске закономерностей в разнородных и, казалось бы, разрозненных данных.
Но дальнейшее развитие системы показало, что эта информационно аналитическая система необходима не только следователям и аналитикам МВД.
Она так же требуется бизнесменам, врачам, политикам, учёным для поиска и выявления сути законов, для поиска и объяснения отклонений от них, для организации и обобщения данных своих исследований.
Естественной моделью данных НЕВОД является граф. Вернее, семантическая сеть, составленная из неких объектов и связей между ними.
Это так называемые микро зависимости - связи между конкретными двумя объектами.
Например:
- два различных объекта есть на самом деле одно и то же (идентификация);
- конкретный объект автор написал конкретный объект (конкретную) книгу;
- объекты-слова "дом" и "жилище" связаны синонимичностью и т.п.
Так для двух конкретных, но далёких по структуре информационных документов (например, изображение автора и книга), можно решить, что они СВЯЗАНЫ между собой. Некто, прочитавший, книгу данного автора, может также считаться связанным с этим автором, например, связью "ЗНАКОМ С ТВОРЧЕСТВОМ". И т.д.
Постепенно вводя в такую базу данных различные объекты, устанавливая известные нам микро зависимости, мы, тем самым, "организуем" наш фактографический материал. И вот через какое-то время, когда такая организация превысит некую критическую массу, в этой базе данных начинают "просматриваться" более глубокие связи, более косвенная, более "сокровенная" информация.
Собственно ЭВМ для того и созданы, чтобы помогать человеку видеть то, что он не в состоянии увидеть непосредственным зрением.
При этом акцент здесь может быть сделан как на работу с отдельным объектом (выявление его связей и отношений с другими объектами, обнаружение в его поведении характерных признаков и т.п.), так и на работу с агрегированными данными (например, ведение статистики спроса по регионам).
Это так называемые макро-зависимости, при поиске которых, мы определяем большие группы информации, близкие друг к другу по каким-то критериям, или же мы ищем зависимости, характерные для больших групп.
Среди этих методов:
- классификация;
- кластеризация;
- поиск связанных свойств;
- и проч.
В любом случае речь идёт о больших множествах "похожих" или близких объектов.
НЕВОД - инструмент, который поможет своему владельцу "оприходовать" информацию, наделить её свойствами (в терминах предметной области), снабдить связями с другой имеющейся информацией и т.д.
Через какое-то время уже сама накопленная информация будет работать на владельца, являясь поистине неиссякаемым источником "новой" (а через некоторое время исторической) информации.
Неотъемлемая часть построения любого хранилища данных - процедуры ETL, позволяющие объединить информацию из разных источников, имеют индустриальные стандарты и, так называемую, "лучшую практику". Для данных, синтезированных в хранилище, разработано большое количество методов анализа. Каждый СУБД-гигант имеет свое решение для построения хранилищ данных и дальнейшего анализа этих данных.
При этом обычно забывается, что собранные в хранилище очищенные, согласованные данные имеют смысл и образуют семантическую сеть. Мы оперируем наборами данных, но не имеем представления о том, есть ли связь между ними и какова она.
Увидеть смысл в уже формализованных данных помогают диаграммы семантической сети, например, такие, как реализованы в продукте НЕВОД.
Однако до сих пор слабо автоматизированной остается рутинная операция выделения связей в неструктурированных данных. Т.е. процесс извлечения формализованной информации из текста и, на её основе, синтез отдельных фрагментов информационного наполнения.
Например, в тех же подразделениях МВД, для которых изначально разрабатывался НЕВОД, остро стоит задача ввода данных. На основе сводок, уголовных дел и других неформализованных документов, необходимо ввести о фигурирующих в них физических и юридических лицах, предметы, адреса и т.д., а также установить смысловые связи между ними.
Практика показывает, что каждая предметная область, помимо специфики представления и хранения информации со всеми её внутренними взаимосвязями, имеет свои особенности при представлении в виде неформализованного текста, что выражается не только в способах оформления документа и перечне используемых приёмов форматирования, но и в самих способах построения отдельных фрагментов текста, используемых словах-сокращениях, специфических для данной предметной области условных обозначениях и т.д. Наиболее яркими примерами являются номера телефонов, сокращения вида "г. Москва", различные способы написания ФИО, указание конкретных дат и т.п.
Эти особенности сказываются непосредственно на самом автоматизированном процессе извлечения данных и выражаются в виде особенностей пользовательского интерфейса, необходимых обращений к различным вспомогательным справочникам и т.п.
Поскольку пока речь идёт только об автоматизированных средствах извлечения информации, то требования к пользовательскому интерфейсу особенно высоки.
Перечисленные выше доводы говорят о том, что создание некоторого универсального средства для автоматизированного анализа текстовых документов и синтеза формализованных данных, содержащих сведения рассматриваемой предметной области, может быть не только неудобно, но и стать существенным фактором, ограничивающим скорость работы пользователя, а, следовательно, и скорость извлечения информации.
С другой стороны, независимо от предметной области данных, процесс извлечения информации всегда включает в себя одни и те же операции, к которым может быть отнесён как анализ текста (прежде всего, лексический, морфологический, синтаксический и семантический), так и работа с полученными данными, куда стоит отнести очистку, корректировку, согласование, устранение конфликтов и, наконец, синтез полученных данных в единую семантическую сеть.
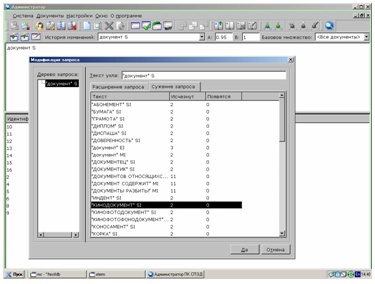
В результате проведённых исследований, было разработано средство для построения систем анализа текстовых документов и извлечения формализованной информации.
Увеличить
Программа для построения систем анализа текстовых документов и извлечения формализованной информации.
Основными требованиями были универсальность, расширяемость, гибкость и интегрируемость с другими информационными системами.
Кроме того, в систему изначально включены модули лексического, морфологического, синтаксического и семантического анализа, модули для работы со словарями и модули для работы с различными форматами текстовых документов.
Сочетание полученной системы и уже имеющихся в НЕВОД средств анализа структурированной информации представляет собой достаточно мощное решение для обработки слабо формализованных данных, представленных в виде текстовых документов. Тем не менее, этого не достаточно для автоматизации обработки самих текстовых документов и, прежде всего, полнотекстового поиска.
Фактически, имеются две, в принципе различные, цели. Одной целью является извлечение, формализация и синтез фактов ("осмысление" данных). Другая цель - поиск документов, содержащих эти факты.
Поэтому, в дополнение, была разработана система семантического поиска электронных документов, имеющая свои особенности по сравнению с уже существующими системами.
Прежде всего, стоит отметить, что за основу взята не классическая схема поиска "запрос-выборка", а итерационная, где на каждом шаге поиска документа выполняется запрос и формируется выборка документов, но дополнительно могут быть даны рекомендации по дальнейшему поиску, каждая из которых представляет собой модификацию текста исходного запроса.
Если рассматривать отдельный шаг описанного итерационного процесса, то он полностью повторяет работу "классической" информационно-поисковой системы. При этом производятся все этапы обработки текстовых документов: морфологический, синтаксический (выделение правильно построенных словосочетаний) и семантический, под которым пока подразумевается только сопоставление содержимого текстового документа с тезаурусом языка.
Архитектура каждого модуля позволяет производить настройку всех используемых вспомогательных словарей.
Дальнейшее развитие этой поисковой системы подразумевает включение в механизмы поиска "тезауруса" фактов. Т.е. поиск по смыслу содержимого.
Система реализована в виде трёхзвенного приложения и представляет все необходимые программные интерфейсы, что делает её средством организации полнотекстового семантического поиска, пригодным для использования в других информационных системах, и, прежде всего, в системах документооборота и электронных архивах.
И в заключение…
Хочется сказать, что нами выделены только две оси в огромном многомерном пространстве информационных систем. На самом деле их бесконечно много. Здесь можно найти очень примечательные оси, например, ось секретности, ось размера, ось объектности (специальных типов данных) и т.д., и т.п.
По всем этим осям изначально проходила линия разделения, но в последнее время растёт вектор сближения, системы начинают пользоваться методами друг друга, всё более растёт понимание необходимости синтетических технологий, необходимости технологий, объединяющих системы, расположенные на различных гранях этого многомерного пространства…
Этот созидательный процесс, по нашему мнению, начался сравнительно недавно. Это время синтеза, время "сбора камней". Мы рады отметить, что компания РЕЛЭКС также двигается в этом направлении.

 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС