Конференция "Корпоративные базы данных'2001"
Обзор объектно-ориентированной СУБД Jasmine
Александр Зашихин, Computer Associates
- Введение
- Терминология
- Мощность
3.1. Свойства
3.2. Методы
3.3. ODQL и запросы
3.4. Объектные идентификаторы и указатели в памяти
3.5. Примеры запросов
3.6. Возможность оптимизации при работе в узкополосных средах
3.7. Ограничения на число одновременно обслуживаемых пользователей и масштабируемость
- Простота
4.1. Администрирование Jasmine
4.2. Jasmine Studio - инструмент формирования и реализации систем
4.3. Формирование системы и ее эволюция
4.4. Реализация системы и эволюция приложений
- Открытость
5.1. Интеграция с другими СУБД
5.2. Возможность использования различных средств разработки
- Надежность
- Требования к ресурсам технических средств клиентов
- Нейроагенты (Neugents) - агенты нейронных сетей
- Заключение
1. Введение
Сегодня, чтобы быть конкурентноспособными, многие предприятия все чаще обращаются к Internet-приложениям и естественно - к мультимедийным типам данных. Пользователям современных предприятий уже недостаточно простых типов, им необходимо работать с изображениями, анимацией, звуком, текстами и т.п.
Многие понимают, что реляционная технология мало пригодна для работы со сложными объектами мультимедийных приложений. Возникают вопросы:
- Какие нужны технологии?
- Если они существуют, то как перейти на них максимально сохранив инвестиции, сделанные в ныне действующие технологии?
- Как уменьшить головную боль от частой смены того дышла, что зовется у нас законодательством и которое выходит там, где вышло?
Еще в середине 1997 года, когда реляционные базы данных были на подъеме, ЦКБ АСУ НЕФТЕПРОДУКТ (Генеральный директор Веденеев Геннадий Иванович т. 178-34-10), с целью ответить на эти вопросы, а так же, как упростить а значит и ускорить процессы создания новых приложений и повысить их качество, как снизить затраты на их сопровождение и эволюцию, решило обратиться к объектным базам данных. Это не было гаданием на кофейной гуще, поскольку руководство ЦКБ уже имело определенный опыт работы с объектными базами данных. Еще в 1986 году по инициативе и при непосредственном участии Веденеева Г.И. в Краснодарском, Ставропольком краях и Ростовской области были внедрены системы "АСУ реализация н/п" (всего около 15 систем), уже тогда имевших клиент/серверную архитектуру, а в качестве базы данных - объектную СУБД !, разработанную одним из Ленинградских институтов. В 1997 году объектные базы данных естественно не были новшеством: Itaska (IBEX), Jasmine (Computer Associates), Matisse (ODB), Object Store (ODI), Ontos (Ontos), O2 (O2), Poet (Poet), Versant (Versant) и.т.д. Другой вопрос, сколь мощны были тогда наши компьютеры и как сильно мы нуждались в Internet(е) и мультимедийных приложениях ? Выбор был остановлен на Jasmine. В начале 1998 года Московское представительство Computer Associates (CA) (Менеджер Кузнецов Сергей Сергеевич т. 937-48-50) любезно предоставило ЦКБ АСУ НЕФТЕПРОДУКТ первую коммерческую версию объектной базы данных Jasmine. Последовательно были опробованы Jasmine v1.1 и v1.21. Сегодня это уже Jasmine ii (intelligent infrastructure).
Прежде чем начать обзор Jasmine, бегло обозначим основные термины и понятия, которые используют и к которым пришли в ЦКБ в процессе практического использования именно Jasmine. Терминологию можно оспаривать.
2. Терминология
Объект в общем смысле - это все, чему можно дать название, т.е. практически все, что угодно.
Объектный идентификатор (OId - Object Identifier) - это нечто, уникально идентифицирующее объект в базе данных.
Класс - это некий шаблон, позволяющий группировать (классифицировать) каким-то образом эти самые объекты. Класс можно представить в виде таблицы, где строки - это экземпляры в классе (в реляционной базе данных они назывались записями), а столбцы - это свойства (в реляционной базе данных они назывались атрибутами) и методы.
Свойства бывают двух типов: свойства-атрибуты и свойства-связи, т.е. связь в Jasmine - это тоже свойство!
Необходимо видеть разницу между свойством класса и свойством экземпляра в классе. Свойство класса определяют именем и типом, а свойство экземпляра в классе заполняют значением (пояснить).
Метод. Физически - это код, реализующий некоторый алгоритм и записанный на одном из алгоритмических языков(!), называемых базовым, с включением кода на языке запросов в базу данных. С другой стороны, метод - это действие, которое может выполнить некоторый объект (а какой объект, - мы узнаем позже) при получении некоторого сообщения, обнаруживая тем самым некоторое поведение.
Приложение - это коллекция (набор) сцен (окон) с которыми работает пользователь.
Смысл создания мультимедийного приложения заключается в визуальном конструировании его сцен. Чтобы сконструировать сцену, необходимо сначала на нее "отбуксировать" (переместить) все необходимые объекты, а затем задать их поведение, теперь уже как элементов сцены.
Элементами сцены могут быть:
- классы;
- экземпляры в классах;
- свойства;
- локальные элементы;
- запросы.
Локальными элементами называются поля редактирования, кнопки, элементы ActiveX и т.д.),
Запрос. Физически - это код, реализующий алгоритм некоторого запроса в базу данных и полностью записанный, естественно, на языке запросов в базу данных. С другой стороны, запрос - это объект в общем смысле, который может быть "отбуксирован" на сцену, где и задается его поведение.
Поведение в Jasmine - это совокупность сообщения получаемого некоторым элементом сцены и действия выполняемого этим элементом.
Сообщение - это сигнал, уведомляющий элемент сцены о необходимости выполнения некоторого действия.
Действие - это реакция (ответ) элемента сцены на полученное сообщение.
Jasmine предоставляет большой набор как сообщений, так и действий (поряка двадцати только категорий сообщений и более двадцати категорий действий). Именно действиями являются методы!
Объектом в Jasmine называется экземпляр в классе с его свойствами-атрибутами, свойствами-связями и методами. Понятно, что о поведении речи не идет.
Между классами объектной базы данных Jasmine существует два вида отношений: наследования и агрегации.
Отношение наследования (общее - частное, или is - a) возникает между классами при их создании путем наследования и изображается в виде стрелки, идущей от потомка к его родителю означая, что потомок унаследовал свойства и методы (действия) родителя. Иерархическое дерево классов объектной базы данных напоминает структуру иерархической базы данных. Наследование считается множественным, когда потомок имеет более одного родителя.
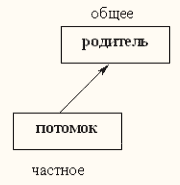
Некоторые эксперты советуют никогда не использовать множественное наследование на том основании, что проблем может быть больше, чем выгоды. В Jasmine при использовании множественного наследования необходимо соблюдать только одно требование: родительские классы не должны иметь свойств и методов с одинаковыми именами.
Отношение агрегации (целое-часть, или has-a) возникает между классами при добавлении в класс свойства-связи и изображается в виде линии идущей от этого свойства, обозначаемого жирной точкой к другому классу означая, что свойство-связь из класса (целое или агрегат) ссылается на другой класс (часть), раскрывающий содержание свойства-связи. Свойства-связи мы рассмотрим несколько позже.
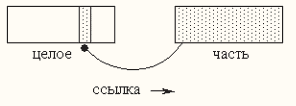
Эволюция - это изменение проекта системы или приложения в связи с изменившимися требованиями.
Сопровождение - это исправление допущенных ошибок как в проекте системы, так и в приложениях.
Сохранение - использование любых средств для поддержания жизни в дряхлеющей системе.
3. Мощность
В Jasmine можно делать все, что и в реляционных базах данных!
3.1. Свойства
Итак, класс в Jasmine - это шаблон свойств и методов, позволяющий группировать экземпляры с идентичными именами и типами свойств.
В Jasmine меется два вида свойств:
- свойства-атрибуты;
- свойства-связи.
Свойство-атрибут (имея в виду классы) - это свойство, которое может быть определено:
1. Литеральными типами:
| Decimal | десятичный тип | ( Decimal[1,0] - Decimal[18,18] ) |
| Integer | целый тип | ( - 2 147 483 648 - + 2 147 483 647 ) |
| Real | вещественный тип | ( + 4.941e -324 - + 1.797e +308 ) |
| String | строка | ( до 65 536 символов ) |
| ByteSequence | произвольные двоичные данные | |
| Date | дата | ( 1 янв. 1582г. - 31 дек. 2382г.) |
| Boolean | логический тип | ( TRUE, FALSE ) |
2. Мультимедийными типами, базовыми из которых являются:
| Audio | звук (*.WAV) |
| Video | видео (*.AVI) |
| Text | текст (*.TXT, *.HTM) |
| Bitmap | изображение (*.BMP, *.GIF, *.JPG, *.TGA, *.TIF) |
Обычно упоминают семь мультимедийных типов:
звук, видео, текст, изображение, графика, анимация, составной.
Недостающие мультимедийные типы (три последних), а так же еще около пяти с лишним десятков других мультимедийных типов, Вы можете взять в семействе классов mediaCF. Но их можно получить и из базовых. Далее мы узнаем, как можно получить анимационную последовательность из базового типа Bitmap.
Свойство-связь надо рассматривать комплексно:
С одной стороны, свойство-связь класса указывает на некоторый класс, с другой стороны, значения этого свойства-связи ссылаются на конкретные экземпляры указанного класса. Мы помним, что свойство класса определяется типом и именем, а свойство экземпляра в классе заполняется значением.
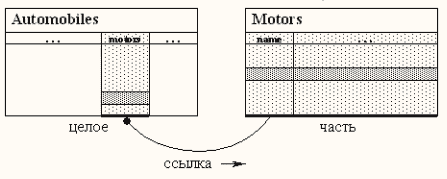
Из рисунка видно, что в классе Automobiles свойство-связь определено именем motors и типом Motors, указывающим на некоторый класс Motors (CA рекомендует давать свойствам-связям имена классов, на которые они ссылаются, только с маленькой буквы), а заполненные значения свойства-связи motors указывают на конкретные экземпляры класса Motors, т.к. являются объектными идентификаторами экземпляров класса Motors (пояснить). В классе Motors, в свою очередь, тоже может быть свойство-связь (например, automobiles), указывающее на класс Automobiles. Это к вопросу о реляционных связях типа "многие ко многим" . . . и никаких при этом связующих таблиц (пояснить).
Свойство коллекции значений
Но это еще не все! Все перечисленные свойства могут быть не только свойствами отдельных (единичных) значений, но и свойствами коллекции значений.
В случае атрибутов литерального типа в реляционной базе данных возможны следующие записи:
Резервуар1 ТРК1 . . .
Резервуар1 ТРК3 . . .
Резервуар2 ТРК2 . . .
Резервуар2 ТРК4 . . . и т.д.
Свойство коллекции значений объектной базы данных позволяет представить экземпляры более просто:
Резервуар1 ТРК1,ТРК3 . . .
Резервуар2 ТРК2,ТРК4 . . . и т.д.
В реляционных базах данных, чтобы идентифицировать подобные записи, приходится прибегать к сегментированным первичным ключам. Последние, в свою очередь, приводят к усложнению связей между таблицами и SQL-запросов. Вспомним, что заполнить запись в реляционной базе данных мы можем двумя командами Insert и Update. При этом, команда Insert обязательно должна быть первой и единственной, с ее помощью заполняются атрибуты, заданные как уникальные, обязательные, первичный ключ. Следующие команды Update заполняют все остальные атрибуты записи, включая и те, что вычисляются из значений, вставленных командой Insert. Ну а если вычисляемый атрибут из числа обязательных или уникальных? Вот тут начинают появляться новые атрибуты в виде Zip-кодов, новые связи, а с ними и . . . перепроектирование системы.
В объектной базе данных Jasmine нет даже первичных ключей. Небезызвестное свойство name нельзя считать аналогом первичного ключа, поскольку это свойство может иметь коллекцию одинаковых значений. Даже в случае полной идентичности значений всех свойств и методов нескольких экземпляров - это разные экземпляры. И возможно это только благодаря объектным идентификаторам, значения которых можно и не знать.
Если говорить о мультимедийных типах, то анимационная последовательность - это и есть коллекция значений мультимедийного типа Bitmap (какие типы файлов он поддерживает, мы знаем). В коллекции можно использовать даже разные типы файлов!
Следует различать мультимедийный тип Video и коллекцию мультимедийных типов Bitmap. В случае коллекции каждый тип (кадр) - это отдельный объект, характеристики которого и порядок размещения в коллекции можно изменять. Хотя смотрятся эти типы одинаково.
Свойство может быть:
Уровня экземпляра - это когда значение данного свойства для разных экземпляров класса может различаться, т.е. у каких-то экземпляров оно может иметь и одинаковое значение.
Уровня класса - это когда значение данного свойства для разных экземпляров класса одно и то же.
Свойство, как и в реляционных базах данных, может быть:
Уникальным (Unique) - это когда значение этого свойства для разных экземпляров класса всегда различно. Необходимо помнить, что уникальность:
- применима к свойствам-атрибутам и свойствам-связям только единичного значения - не к коллекциям значений!
- наследуется и не может быть отменена в подклассах, т.е., если мы в классе Sotrudniki, в котором определили свойство reg_nom как уникальное, создадим путем наследования несколько подклассов, то в каждом из них будет уникальное свойство reg_nom. Это значит, что в созданной ветви классов абсолютно все сотрудники будут иметь неповторяющиеся регистрационные номера, независимо от класса, к которому они принадлежат.
Обязательным (Mandatory) - это значит, что при добавлении экземпляра в класс это свойство должно иметь значение. Обязательность, как и уникальность, наследуется.
Кроме того, говоря о значениях свойств, необходимо отметить, что в Jasmine существует понятие значения NIL. Но это не то же самое, что NULL в реляционной базе данных. NULL - это значит нет значения, а NIL - это неизвестно, есть значение или нет.
3.2. Методы
Петер Коуд (Peter Coad) "Объектные модели. Стратегии, шаблоны и приложения" считает, что каждый объект должен отвечать на три вопроса: "что он знает?", "что он видит?", "что он может делать?". Так вот:
- то, что знает объект - это свойства-атрибуты;
- то, что видит объект - это свойства-связи;
- то, что может делать объект - это методы (действия) .
Примерно так же считают Эдвард Йордон (Edward Yourdon) и Карл Аргила (Carl Argila).
Метод - это действие, которое может выполнить тот или иной объект. Такими объектами могут быть:
- экземпляр;
- коллекция экземпляров;
- класс;
- коллекция классов.
В соответствии с этим и методы могут быть:
- Уровня экземпляра, это когда метод может быть вызван любым, но только одним экземпляром в классе.
- Уровня коллекции экземпляров, это когда метод может быть вызван некоторой коллекцией экземпляров в классе.
- Уровня класса, это когда метод может быть вызван классом в целом.
- Уровня коллекции классов, это когда метод может быть вызван некоторой коллекцией классов.
Физически метод - это код, реализующий некоторый алгоритм (сейчас говорят - алгоритм некоторого бизнес-процесса), выполненный на одном из алгоритмических языков, называемых базовым, с включением кода на языке запросов в базу данных и позволяющий не только добавлять, удалять, корректировать и получать данные, но и создавать новые классы, свойства и т.д., т.е. изменять существующую систему (речь идет об эволюции системы).
Технология создания метода проста. Сначала, с использованием некоторого базового языка и языка запросов в базу данных, пишется код (любым текстовым редактором), реализующий алгоритм некоторого бизнес-процесса. Затем этот код средствами Jasmine Method Editor (о нем мы будем говорить позже) оформляется (речь идет о компиляции) в виде метода и добавляется в один из классов. Надо сказать, что алгоритм бизнес-процесса может и не содержать запросов в базу данных, а может быть только запросом в базу данных.
В качестве базового языка можно использовать C/C++ или Java, а для запросов в объектную базу данных можно использовать только ODQL (Object Database Query Language - язык запросов в объектную базу данных).
Поскольку методы являются частью объектов, то они всегда находятся там же, где и объекты, - в базе данных, а значит выполняются на сервере, т.е. быстро и с полным набором всех средств защиты и операционной системы и СУБД. Таким образом, при использовании методов, клиент всегда "тонкий" и, как мы узнаем дальше, его можно еще "утоньшить". Сторонники реляционных баз данных спросят: "А чем хранимая процедура выбора или выполнения (т.е. откомпилированный код SQL, хранящийся в базе данных, а значит выполняющийся на сервере), обеспечивающая "тонкого" клиента, хуже?" Основное отличие методов от хранимых процедур заключается в том, что методы наследуются!
Транзакции можно начинать, заканчивать, или откатывать назад из приложения, но не из методов! Отсюда вытекает основное требование: методы должны быть не интерактивными и по возможности короткими!
Существует два способа использования методов:
- Метод можно использовать в качестве действия при задании поведения элемента сцены.
- Метод можно использовать в запросе, делая так называемый вызов метода. Запрос же, в свою очередь, может быть элементом сцены с вытекающими отсюда последствиями (пояснить).
3.3. ODQL и запросы
Давайте вспомним, почему SQL встраивался в алгоритмический язык? Да потому, что в нем не было основного: возможности объявления переменных и условных операторов. В ODQL все это есть, т.е. можно и объявлять переменные, и использовать условные операторы (инструкции) if-else, while, scan, indexScan.
Переменные можно объявлять следующим образом:
1. Integer I;
String S;
Decimal[8,2] D;
где переменные I, S и D - соответственно целое число, символьная строка и десятичное
число.
2. Bag BI;
Bag BS;
где переменные BI и BS - соответственно коллекция (набор) целых чисел и коллекция
символьных строк.
3. Manager M;
где переменная M - экземпляр класса Manager.
На языке С это могло бы выглядеть как-то так:
struct Manager
{
int ABC;
float CDE;
. . .
char name[10];
};
4. Bag BM;
где переменная BM - коллекция экземпляров класса Manager.
5. Manager class MC;
где переменная MC - класс Manager и любой из его подклассов, если далее это
специально не оговаривается.
6. Bag BMC;
где переменная BMC - коллекция классов из числа подчиненных классу
Manager, включая класс Manager.
7. [Integer I, String S, Decimal[8,2]] ISD;
где переменная ISD - кортеж (коллекция свойств экземпляра в классе).
8. Bag<[Integer I, String S, Decimal[8,2]]> BISD;
где переменная BISD - коллекция кортежей.
Если инструкции if-else, while обычны, то инструкция scan (ABC, A) { . . . }; означает: для каждой переменной A из коллекции ABC (а коллекции, мы уже знаем, могут состоять из кортежей, классов, экземпляров класса, значений свойств) надо выполнять действия, указанные в фигурных скобках. Есть готовый метод createIterator( ), называемый итератором и дающий более гибкие возможности по сравнению с инструкцией scan, т.к. он позволяет обрабатывать коллекцию в обоих направлениях, но при этом необходимо использовать еще два готовых метода advance( ) и get( ). Необходимо отметить, что можно иметь много активных итераторов одновременно. Кроме того, Вы можете создать и собственный метод итерации.
Код практически любого бизнес-процесса можно полностью написать на ODQL, т.е без использования инструкций базового языка! Однако ODQL, являясь интерпретатором, все равно встраивается в базовый язык.
Если Вы используете базовый язык с языком запросов в базу данных, то инструкции ODQL, встраиваемые в базовый язык обязательно должны начинаться со знака $, что отличает их от инструкций базового языка. К переменным ODQL необходимо обращаться из инструкций ODQL, к переменным базового языка необходимо обращаться из инструкций базового языка. Но ODQL настолько хорошо интегрирован с C/C++, что в инструкциях C/C++ можно использовать переменные ODQL ! Надо только не забывать, что для этого:
- При объявлении ODQL-переменных, каждой ODQL-переменной должны соответствовать две переменных базового языка, например: $Integer A <Aval, Astat>; т.е. переменной A целого типа языка ODQL соответствуют две переменные языка С/С++ - переменная значения Aval и переменная состояния Astat.
- При чтении переменной ODQL в инструкции базового языка сначала необходимо проверить переменную состояния, а затем уже читать переменную значения.
- При записи переменной ODQL в инструкции базового языка сначала необходимо установить переменную значения, а затем - переменную состояния.
Говорить о возможности использования библиотечных функций C/C++ как базового языка наверно нет необходимости.
Существует два способа создания запросов :
- На языке ODQL пишется код (любым текстовым редактором), реализующий алгоритм некоторого запроса в базу данных. Затем этот код средствами Method Editor оформляется (речь идет о компиляции) в виде метода и добавляется в один из классов.
- Запрос можно полностью создать без записи кода (включая отладку) в окне Query Editor. В этом случае запрос является самостоятельным объектом, который может быть "отбуксирован" на сцену. Запрос извлекает экземпляры из классов целиком! Его классовую принадлежность можно увидеть в закладке Queries в правой части окна Class Browser (разъяснить заблуждение по поводу слабости запросов ODQL).
Запрос всегда обращается ко всем подклассам класса, если не используется ключевое слово alone во from-спецификации запроса.
Существует два способа использования запросов:
- Запрос, если это метод, можно использовать в качестве действия при задании поведения элемента сцены (уже известно).
- Запрос, если он создан средствами Query Editor, можно использовать в качестве элемента сцены.
(Разъяснить заблуждение по поводу того, что ODQL - только для запросов, а C/C++ - для мощных вычислений. Сравнить листинги запросов на SQL и ODQL).
3.4. Объектные идентификаторы и указатели в памяти
В объектных базах данных по сравнению с реляционными имеется два источника повышения производительности:
- Объектные идентификаторы, при обращениии к объектам в базе данных;
- Указатели, при обращении к объектам в оперативной памяти.
Объектный идентификатор (OId - Object Identifier) - это нечто, уникально идентифицирующее объект в базе данных. Если OId является физическим адресом объекта, то выборка объекта из базы данных осуществляется по этому физическому адресу, если - логическим адресом, то выборка объекта осуществляется по адресу, взятому из хэш-таблицы, преобразующей (отображающей) логические адреса объектных идентификаторов в их физические адреса.
Сторонники реляционных баз данных утверждают, что в скорости выборки информации реляционные базы данных не уступают объектным. Оставим это на их совести.
Указатель. После того как объект извлечен из базы данных и загружен в оперативную память, его OId конвертируется в указатель. Таким образом указатель - это адрес объекта но уже в оперативной памяти. Перемещение от объекта к объекту по указателям в оперативной памяти называется навигацией и теперь уже сторонники объектных баз данных утверждают, что именно она повышает производительность объектной базы данных по сравнению с реляционной на 2-3 порядка! При этом они ссылаются на базы данных в оперативной памяти, так называемые MMDb (Main Memory Database).
Кто же прав? Дело в том, что в объектных базах данных при выборке не принято отображать информацию до полного заполнения последнего из элементов изображений. Поэтому, при внешне одинаковой реактивности реляционной и объектной систем, в объектной базе данных скорость выборки должна быть на 2-3 порядка выше. Можете ли Вы представить, что храните в реляционной базе данных и выбираете из нее в качестве свойства например, коллекцию *. JPG файлов?! BLOb здесь бессилен!
Индексация в объектных базах данных тоже повышает производительность системы, но она не так важна, как в реляционных, поскольку в объектных есть навигация. Индексы могут быть в любой момент созданы методом createIndex( ) и удалены методом dropIndex( ). CA рекомендует не использовать индексы там, где возможны частые корректировки. Эксплуатируют индексы с помощью ранее упомянутой инструкции indexScan языка ODQL, особенностью которой является возможность задания диапазона сканирования и то, что она может применяться только к конкретному классу без его подклассов.
Не надо забывать, что эволюция любой системы влечет за собой усложнение отношений между классами, а значит - увеличение числа свойств-связей, а значит - числа OId. Но чем больше указателей при загрузке объектов в оперативную память, тем выше производительность системы. Другой вопрос: "А сколько нужно этой самой оперативной памяти?". Как бы там ни было, но пока быстродействие и объем оперативной памяти растут, будет расти и производительность объектных баз данных!, поскольку именно они имеют OId и указатели в памяти.
3.5. Примеры запросов
Ранее, рассматривая методы, мы говорили о том, что их можно вызывать в запросах. Но в запросах можно вызывать и свойства. Именно через вложенные вызовы свойств реализуется так называемая навигация.
Проведем некоторые сравнения реляционной и объектной баз данных. Допустим надо извлечь данные из таблицы реляционной базы данных используя в качестве критерия данные из этой же таблицы.
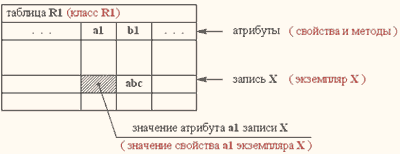
SQL-запрос может выглядеть следующим образом:
SELECT a1
FROM R1
WHERE b1 = "abc";
означая, что мы извлекаем из таблицы R1 реляционной базы данных набор значений атрибута a1 только тех записей, у которых значения атрибута b1 являются символьной строкой abc.
В объектной базе данных ODQL-запрос может выглядеть следующим образом:
Bag <String> BS; (коллекция значений типа String )
BS = R1. a1
from R1
where R1. b1 = = "abc";
Означая, что мы извлекаем из класса R1 объектной базы данных коллекцию значений свойства a1 только тех экземпляров, у которых значения свойства b1 являются символьной строкой abc. Все очень похоже, если не считать объявления переменной BS.
Но все будет выглядеть иначе, если потребуется извлечь данные из одной таблицы, используя в качестве критерия выборки данные из другой таблицы.
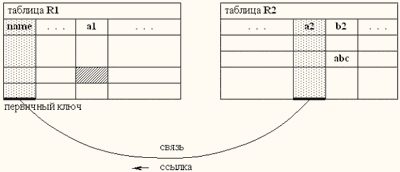
SQL-запрос может выглядеть следующим образом:
SELECT a1
FROM R1
WHERE name = (SELECT a2
FROM R2
WHERE b2 = "abc");
означая, что сначала выполняется подзапрос, который извлекает из таблицы R2 значения атрибута a2 только тех записей, у которых значение атрибута b2 является символьной строкой abc, а потом выполняется запрос, который извлекает из таблицы R1 значение атрибута a1 только тех записей, у которых значение атрибута name (первичного ключа) равно значению атрибута a2 записей, выбранных из таблицы R2 подзапросом, т.е. все идет сзаду наперед. Понятно, что значение атрибута a2 может ссылаться только на значение другого атрибута, но не на кортеж или запись! Процесс можно ускорить, если атрибут name проиндексировать.
В объектной базе данных, в этом случае, второй запрос не нужен. Необходимо только уточнить, что значение свойства b2 нужного экземпляра должно быть символьной строкой abc. Это возможно потому, что любое значение свойства r2 уже является объектным идентификатором (адресом) целого экземпляра в классе R2.
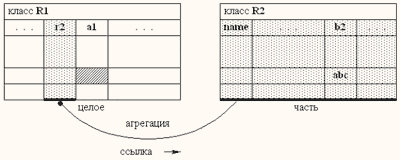
ODQL-запрос может выглядеть следующим образом:
Bag <String> BS;
BS = R1. a1
from R1
where R1. r2. b2 = = "abc";
Четвертая строка запроса - это пример использования вложенных вызовов свойств, т.е. навигации. Как видим, не надо никаких дополнительных запросов.
Сторонники реляционных баз данных могут ответить, что они тоже могут обойтись без дополнительных запросов используя механизм объединений. Да, этот пример можно с помощью реляционного объединения записать следующим образом (пояснить):
SELECT R1. a1
FROM R1, R2
WHERE R2. b2 = "abc"
AND R1. name = R2. a2
GROUP BY R1. a1;
Но представьте, что Вам надо извлечь значения не одного атрибута нужных записей, а целых записей, используя в качестве критерия значение атрибута не из второй таблицы, а из N-й. Это значит, что в запросе за словом SELECT надо дописать все недостающие атрибуты, за словом FROM дописать все объединяемые таблицы, за словом WHERE поменять левую и правую части равенства, за словом AND поменять равенство и дописать еще N-1 равенство объединения, за словом GROUP BY дописать все недостающие отрибуты в нужном для вывода порядке.
В объектной же базе данных достаточно в объявлении переменной сменить коллекцию значений на коллекцию экземпляров и за словом where просто вложить (вставить через точку) имена свойств-связей всех добавленных классов:
Bag <R1> BR1; (коллекция экземпляров класса R1)
BR1 = R1
from R1
where R1. r2. . . . = = "abc";
Надо заметить, что в объектных базах данных тоже можно использовать механизм объединений. Еще в самом начале было сказано, что в Jasmine можно делать все, что и в реляционных базах данных. Но в данном случае у нас в руках журавль навигации. Хотя синица объединения тоже может пригодиться.
Можно сделать то же самое, вызвав уже готовый метод:
. . .
where R1. r2. b2. like("abc");
Если все-таки нужно выбирать кортежи, то надо поступить так:
Bag <[String r2, Integer a1]> BSI; (коллекция кортежей)
BSI = [R1. r2, R1. a1]
from R1
where R1. r2. b2. like("abc");
Метод like( ) выбирает все значения конкретного свойства, удовлетворяющие условию в скобках (пояснить). Кроме того, этот метод легко можно заменить другим, более совершенным (это может быть и собственный метод). Замена метода не требует каких-либо изменений в запросе, а следовательно не влияет на алгоритм приложения в целом. Нам не надо знать, как взаимодействует метод с запросом. Если Вы попробуете в SQL-запросе заменить N-й подзапрос, то Вам наверняка придется переписывать весь запрос заново и непременно проанализировать работу всего приложения.
Вот здесь надо говорить об инкапсуляции. Объект всегда инкапсулирует (скрывает) в себе какие-то детали. В Jasmine, не вдаваясь в детали объектов, мы можем заменять одни объекты другими и при этом не думать о том, как эти объекты взаимодействуют с какими-то еще объектами. Например, Вам сверху спустили новый алгоритм начисления премии, это значит, что надо создать новый метод. После того как новый метод создан можно идти следующими путями:
- Если старый метод Вам не нужен, надо просто удалить его из базы данных, т.е. из какого-то класса и добавить вместо него новый с прежним именем. В этом случае приложение вообще никак не затрагивается.
- Если же Вы хотите использовать и старый и новый методы, то на одной из сцен приложения, в диалоге поведения соответствующего элемента сцены, необходимо добавить строку поведения (выбрать сообщение и действие). Об этом мы поговорим позже.
Методы могут быть, как мы помним, четырех уровней, т.е. на любой вкус и на все случаи жизни. Методы, как и свойства наследуется, значит их не надо переписывать. Методы, как мы видели, легко меняются. А отсюда - простота эволюции приложений. Методы заметно снижают головную боль в процессе эволюции приложений! Это к вопросу о частой смене законодательства.
Сторонники объектных баз данных считают, что именно методы наиболее сильно отличают объектную базу данных от других СУБД. А наследования, а агрегации, а абстрактные типы данных, а объектные идентификаторы, а указатели в памяти, а инкапсуляция? А мы еще будем говорить об абстрактных классах, о полиморфизме и т.д.
3.6. Возможность оптимизации при работе в узкополосных средах
Использование Web-приложений предполагает работу в узкополосных средах. Для оптимизации работы в этих случаях CA предлагает:
- Интеллектуальное кэширование, как на стороне сервера, так и на стороне клиента. Размеры буферов рабочей и транзакционной областей хранения на клиенте задаются в файле среды клиента (C:\Jasmine \Jasmine\envfile\*.env ).
- Итерационный доступ к данным (последовательный, по мере необходимости, а не все сразу, чтобы не перегружать линии). Привести пример реентерабельных модулей.
- Сжатие данных при передаче (отдельная коробка DoubleIT).
Для наших линий связи этого недостаточно. Хотя не всегда понятно, что подразумевают под плохой связью:
- низкую скорость передачи?
- частые отказы? (из-за помех, безответственности поставщика услуг, собственного невежества?).
Что еще можно найти или вспомнить сегодня:
- сотовую связь;
- радио-Ethernet;
- распределенные системы.
Относительно последнего: в Jasmine возможно совмещение на одном компьютере сервера и клиента. Более того, возможно совмещение до семи(!) серверов Jasmine на одном компьютере.
Если не собирать всю информацию с удаленных клиентов на центральном сервере, для последующей ее обработки, а сразу обрабатывать ее на сервере удаленного клиента (теперь клиент и сервер могут быть совмещены на удаленном компьютере), а результаты передавать на центральный сервер: с одной стороны - снизив нагрузку на линии связи, а с другой - переложив вопросы связи на плечи центрального и удаленного серверов Jasmine, т.к. они оба хорошо приспособлены для работы в узкополосных средах.
3.7. Ограничения на число одновременно обслуживаемых пользователей и масштабируемость
Представители CA утверждают, что Jasmine, благодаря многопоточности и поддержке SMP-архитектур практически не имеет ограничений на число одновременно обслуживаемых пользователей и хорошо масштабируется.
4. Простота
4.1. Администрирование Jasmine
В администрировании система Jasmine достаточно проста. Все, что Вам нужно, так это:
1. Знать, что в процессе инсталляции, а она начинается с запуска файла SETUP.EXE из каталога Intelnt Вашего CD с Jasmine (речь идет о версии 1.21 для платформы NT), необходимо выбрать тип инсталляции Custom и:
а) отмечать птичкой все, что имеется, только один раз отметив либо Netscape Navigator либо MS Internet Explorer.
б) оставлять все, что предлагается, выбрав только временную зону GMT3 и таблицу символов ISO88595.
в) не забыть нажать на кнопку Finish, после чего и начнется процесс инсталляции.
Имеется:
- создание системной и пользовательской областей хранения;
- создание мультимедийного, SQL, Web и демонстрационного семейства классов;
- инсталляция HTTP сервера;
- инсталляция WebLink сервера;
- инсталляция Netscape Navigator или MS Internet Explorer;
- инсталляция документации;
- автоматический старт Jasmine;
- установка некоторых параметров конфигурации Jasmine.
Предлагается:
- размер и число страниц областей хранения;
- имя и порт Web-сервера;
- временная зона;
- таблица символов;
- вид терминала;
- код инсталляции.
2. Знать, что для настройки в каталоге . . . Jasmine\Jasmine\files> имеются 2 файла:
- файл конфигурации (config.dat);
- файл идентификаторов (symbol.tbl), и что их можно корректировать. На этапе знакомства с Jasmine этого можно не делать.
3. Уметь создавать пользовательские области хранения (User Store). Умение заключается в том что, при запущенном Jasmine, в окне DOS-сеанса Вам необходимо с учетом регистра ввести команду createStore указав в ней число страниц, размер страницы, имя создаваемой области хранения, каталог, в котором она должна располагаться с именем сегмента.
. . . > createStore -numberOfPages 2048 -pageSize 8
UserStore01 C:\Jasmine\Jasmine\data\us_extent01
Надо сказать, что в Jasmine есть еще три области хранения:
- Системная (System Store);
- Рабочая (Work Store);
- Транзакционная (Transaction Store);
Причем все три области хранения создаются автоматически; системная расширяется автоматически, а рабочая и транзакционная и удаляются автоматически. Кроме того, их размер можно корректировать. Это те самые интеллектуальные кэши.
4. Уметь создавать семейства классов в пользовательских областях хранения. Умение заключается в том что, при запущенном Jasmine, в окне DOS-сеанса Вам необходимо с учетом регистра ввести команду createcf указав в ней имя создаваемого семейства классов и имя пользовательской области хранения, в которой оно должно располагаться.
. . . > createcf Cl_Family01 UserStore01
5. Уметь подключать пользователей к базе данных Jasmine используя утилиту Jasmine Connections . . . Jasmine\Jasmine\bin\conman . exe. Это можно выполнять как с помощью учетной записи, так и с помощью инсталляционного пароля. Для этого необходимо знать:
- имя соединения (может быть любым до 30 символов, при локальном подключении должно быть идентично имени, установленному как local_vnode в файле конфигурации config.dat );
- учетную запись / ничего;
- пароль учетной записи / инсталляционный пароль;
- сетевой адрес или имя узла сервера Jasmine ;
- сетевой протокол (используем TCP/IP, хотя говорится о SPX/IPX и MS LAN Manager);
- анализируемый адрес или Listen Address (должен быть идентичен значению переменной среды Jasmine JAS_INSTALLATION в файле идентификаторов symbol.tbl).
Отличие заключается в том, что при использовании инсталляционного пароля, последний по сети не передается и нет нужды в учетной записи на сервере Jasmine, поэтому вместо учетной записи используется символ *.
6. Знать, что для контроля за системой Jasmine можно использовать средства самой ОС:
Пуск > Настройка > Панель управления > Администрирование
и далее Просмотр событий, Системный монитор, Службы компонентов,
Управление компьютером и т.д. (Start > Settings >
Control Panel > Administrative Tools).
7. Помнить, что самой надежной защитой от потери данных является их архивирование и хранение в надежном месте. Поскольку ARCserve (Управление системами архивирования и резервирования данных) поставляется отдельно, то необходимо помнить: все, что необходимо архивировать, находится в каталоге . . . Jasmine\data>, кроме файла идентификаторов (symbol.tbl) и файла конфигурации (config.dat), которые находятся, как мы знаем, в каталоге . . . Jasmine\files>. Тогда средствами резервного копирования операционной системы все это очень просто архивируется. Архивируются:
- системная и пользовательские области хранени (. . . Jasmine\data>);
- файлы управления мультимедийными данными (. . . Jasmine\data\mmarea>);
- библиотеки методов (. . . Jasmine\data\default\methods>);
- файлы symbol.tbl и config.dat (. . . Jasmine\files>).
4.2. Jasmine Studio - инструмент формирования и реализации систем
Процесс создания системы включает:
- анализ и проектирование в процессе которых система формируется;
- программирование, в процессе которого система реализуется.
После этого система эволюционирует.
Работа с реальной базой требует конкретики, а конкретика такова, что:
1. На этапе анализа и проектирования необходимо:
а) идентифицировать классы;
б) определить их иерархическое дерево;
в) определить свойства-атрибуты;
г) определить свойства-связи;
д) определить функциональный перечень методов.
При выполнении всех этих пунктов можно утверждать, что система сформирована.
Именно эти пять пунктов CA определяет в качестве логического проектирования (определяется еще и физическое проектирование, связываемое с выделением областей на физических носителях и созданием индексов).
2. На этапе программирования необходимо:
а) создать методы (пояснить);
б) создать приложения.
При выполнением этих двух пунктов можно говорить о реализации системы.
CA вместе с Jasmine поставляет Jasmine Studio (старое название JADE). Это мощнейшее средство, с помощью которого можно просто и быстро сформировать и реализовать систему. Средства Jasmine Studio достаточно разнообразны. Это семь окон:
- Application Manager - базовое окно, как для формирования, так и для реализации системы.
- Class Browser - окно для работы с классами в процессе формирования и реализации системы.
- Class Property Inspector - окно для работы со свойствами классов в процессе формирования и реализации системы.
- Object Property Inspector - окно для работы со свойствами экземпляров в классах в процессе реализации системы (создание приложений).
- Query Editor - окно для создания запросов, используемых в качестве элементов сцены в процессе реализации системы (создание приложений).
- Method Editor - окно для создания методов в процессе реализации системы (создание методов).
- Scene Item Property Inspector - окно для работы с элементами сцены в процессе реализации системы (создание приложений).
4.3. Формирование системы и ее эволюция
"Сами по себе объекты не представляют никакого интереса: только в процессе взаимодействия объектов реализуется система". (Гради Буч (Grady Booch) "Объектно-ориентированный анализ и проектирование с примерами приложений на С++").
С точки зрения проектировщика, в объектной базе данных Jasmine любая система может быть представлена в виде коллекции классов с отношениями в виде наследований и агрегаций, напоминающей структуру сетевой базы данных.
Все классы в Jasmine создаются либо путем наследования, либо путем дублирования, кроме старшего класса. Чтобы создать старший класс необходимо в контекстном меню левой части окна уже известного нам Class Browser выбрать команду New Class и ввести имя класса с заглавной буквы (так рекомендует CA) латинскими буквами. (Напомнить смысл правой кнопки - контекстного меню объекта). После того как класс создан, можно определять его свойства, т.е. имена и типы свойств. Для этого надо в контекстном меню левой части окна Class Property Inspector (оно открывается командой Open из контекстного меню выбранного класса в окне Class Browser) выбрать команду New Property, ввести имя и:
- если это свойство-атрибут, то выбрать нужный тип свойства и указать является ли оно свойством уровня класса (Class), свойством коллекции значений (Collection), уникальным (Unique), обязательным (Mandatory);
- если это свойство-связь, то выбрать только нужный класс.
Отметим только, что у старшего класса свойства-связи быть не может.
При определении свойства-связи в классе совершенно не надо знать, есть ли другие свойства-связи в этом классе и есть ли ссылки из каких-нибудь других классов на этот класс. Может о такой инкапсуляции и надо говорить?
Чтобы создать класс путем наследования, необходимо в том же Jasmine Class Browser выбрать нужный класс, а затем в его контекстном меню - команду New Subclass, с последующим заданием имени класса.
Дублирование класса выполняется аналогично наследованию, только в контекстном меню исходного класса надо выбрать команду Duplicate Class и т.д.
В чем же отличие этих двух способов?
В первом случае мы создаем копию класса с его свойствами и методами на следующем, нижнем уровне иерархии, т.е. создаем подкласс. Во втором случае мы создаем копию класса с его свойствами и методами на на том же уровне иерархии.
Созданные наследованием и дублированием классы можно переопределять, т.е. определять в них новые свойства (аналогично тому, как это делалось в старшем классе).
Необходимо отметить, что для выполнения всех этих манипуляций можно использовать меню верхней части экранов, иногда достаточно двойных щелчков мышью, т.е. - очень большое разнообразие возможностей. Но мы знаем, что есть объект с контекстным меню - и этого вполне достаточно. И так везде в Jasmine. Это и есть один из элементов интуитивнопонятного интерфейса.
В нотации Гради Буча (Grady Booch) система может напоминать нечто изображенное ниже:
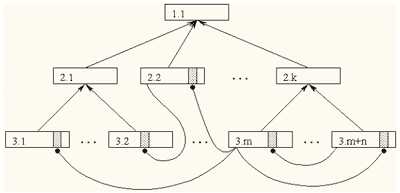
Классы, не содержащие экземпляров называются абстрактными классами иерархического дерева. Если классы заполняются экземплярами, то они называются конкретными классами, или листьями иерархического дерева.
Итак, Jasmine поддерживает абстрактные классы. Ну и что? Это значит, что систему, какая бы она сложная ни была, можно проектировать с любого ее фрагмента, не думая о том, как проект этой системы будет эволюционировать (эволюцию приложений мы уже рассматривали), поскольку такую систему в Jasmine можно наращивать с любого, не только абстрактного, но даже конкретного класса любого уровня иерархии. При этом, вновь созданная ветвь классов и дерево классов существующей системы совершенно прозрачны для свойств-связей в обоих направлениях!
В реляционных базах данных такое просто невозможно. Не потому ли разработчики, использующие реляционные базы данных обычно пытаются создать систему сразу на все случаи жизни, а создав, вынуждены обкладываться аббревиатурой вроде ИСУП, КИС и т.д.
Абстрактные классы в Jasmine - это козырь проектирования! Вот почему система, сформированнная (этап анализа и проектирования) средствами Jasmine, упрощает сопровождение (меньше ошибок), легко эволюционирует (изменяется в связи с изменяющимися требованиями) и не требует при этом сохранения (использования любых средств для поддержания ее жизни).
4.4. Реализация системы и эволюция приложений
Фраза из технической документации том, что в Jasmine Вы ограничены только рамками своего воображения, вполне может быть эпиграфом к этому разделу.
По Гради Бучу (Grady Booch) объектно-ориентированное программирование (OOP - Object-Oriented Programming) это когда:
- В качестве базовых элементов используются объекты, а не алгоритмы;
- Объекты являются экземплярами какого-то класса (для Jasmine несколько шире);
- Классы организованы иерархически.
(К чему бы все это?)
На этапе реализации системы, мы помним, необходимо создать методы и приложения.
Что касается методов, то они уже были рассмотрены. Теперь рассмотрим процесс создания приложений.
Чтобы создать приложение в Jasmine необходимо:
- присвоить имя приложению;
- сконструировать все необходимые сцены данного приложения;
- оформить его в виде клиент/серверного приложения, или Web-приложения.
- Чтобы присвоить имя приложению необходимо в контекстном меню левой части окна Application Manager выбрать последовательно команды New, Application и ввести имя приложения (можно использовать кириллицу).
- Сконструировать сцену приложения, это значит:
- создать сцену в приложении;
- открыть и настроить эту сцену;
- найти (при необходимости - создать) нужные объекты и "отбуксировать" их на сцену;
- задать поведение элементов сцены;
- доработать сцену (при необходимости).
- Чтобы создать сцену в приложении необходимо в левой части окна Application Manager выделить это приложение, в его контекстном меню выбрать последовательно команды New, Scene и ввести имя сцены (можно использовать кириллицу).
- Чтобы открыть сцену приложения необходимо в левой части окна Application Manager выделить эту сцену и в ее контекстном меню выбрать команду Open, а правой части окна установить необходимые параметра сцены (размер и позиционирование сцены, отображение сетки, ее цвет и шаг и т.д.)
- Что может быть отбуксировано на сцену ? Это могут быть: класс, экземпляр класса, свойство класса или свойство экземпляря, запрос, локальный элемент. Все они, кроме свойств, буксируются из окна Class Browser. Свойства буксируются из окон Class Property Inspector и Object Property Inspector. Объект на сцене именуется элементом сцены.
- Чтобы задать поведение конкретного элемента сцены необходимо в его контекстном меню выбрать Behavior и в открывшемся окне сначала выбрать сообщение, на которое должен отвечать этот элемент сцены, а затем - действие, которым он должен отвечать на это сообщение. Сообщений, на которые должен реагировать элемент сцены можно выбрать достаточно много, но для каждого сообщения должно быть выбрано действие.
- Доработка сцены касается, как правило, ее дизайна.
- Для оформления приложения в том или ином виде необходимо в меню верхней части Application Manager выбрать Tools, а затем Create Distribution Executable или Publish Web Application и далее по диалогу.
5. Открытость
5.1. Интеграция с другими СУБД
В Jasmine предусмотрена интеграция с реляционными СУБД: Oracle, Sybase, Ingres, Informix, MS SQL Server, DB2 и др. Это значит, что Вы, будучи клиентом Jasmine и используя методы семейства классов sqlCF, можете обращаться из своих приложений в любую из перечисленных баз данных. При этом, можно начать реализацию частями действующей системы в новой объектной базе данных. Это к вопросу о сохранении инвестиций сделанных в прежние технологии!
Анонсируется интеграция и с нереляционнымии СУБД майнфреймов: VSAM, IMS и др. Подробный перечень СУБД можно найти на: www.cai.com.
5.2. Возможность использования различных средств разработки
Из всех средств разработки для Jasmine наиболее серъезными являются:
- Jasmine Studio;
- MS Visual C++;
- MS Visual J++.
Только с их помощью можно полноценно формировать системы. Что касается реализации систем, то:
- При создании методов необходимо помнить, что:
- методы, созданные средствами MS Visual C++ и MS Visual J++ - не могут обращаться в базу данных;
- методы, созданные средствами Jasmine Studio - универсальны.
- При создании приложений можно использовать любые из перечисленных средств.
С этой целью в Jasmine интегрированы следующие интерфейсы:
- Jasmine WebLink - интерфейс обращения к объектам базы данных из Web-браузера;
- Jasmine С API - интерфейс сопряжения с языком С;
- Jasmine Java Bindings - интерфейс сопряжения с языком Java;
- ActiveX Control - интерфейс обращения к объектам базы данных из средств, поддерживающих ActiveX.
Подробный перечень средств разработки и интерфейсов можно найти на: www.cai.com.
6. Надежность
В плане надежности Jasmine имеет полный набор средств, присущих реляционным базам данных, включая конечно и транзакции. Мы уже знаем, что транзакции можно начать, закончить и откатить назад из приложений, но не из методов!
Справочная целостность (нельзя обращаться к ликвидированному объекту) в Jasmine необязательна! При обращении к ликвидированному объекту будет выдано сообщение, которое обрабатывается обычным образом.
Кроме того, CA предлагает своим заказчикам следующие средства:
- управление системами архивирования и резервирования данных (ARCserveIT);
- защищенная передача данных (CryptIT);
- защита от вирусов (InoculateIT).
7. Требования к ресурсам технических средств клиентов
Если не считать оперативной памяти, то требования достаточно просты: если производительность компьютера в требуемой операционной системе Вас устраивает, то этого вполне достаточно для нормальной работы Jasmine.
Что касается оперативной памяти то, когда появилась OS/2 Warp фирмы IBM, Билл Гейтс заявил, что она требует слишком много оперативной памяти, целых 4mB. Только через год появилась Windows 95, которую никак нельзя было сравнить с OS/2 Warp. Еще позднее появилась Windows NT4, которую уже можно было сравнивать с OS/2 Warp, но "ела" она для своих нужд порядка 20mB оперативной памяти, отдавая остатки приложениям пользователей.
Сегодня Windows 2000 Professional при загрузке "съедает" для собственных нужд порядка 50mB оперативной памяти. Jasmine забирает порядка 30mB на то самое интеллектуальное кэширование. Все остальное достается приложениям, а сколько - зависит уже от объема оперативной памяти Вашего PC.
Рассмотреть:
- системную шину;
- процессор;
- оперативную память;
- жесткие диски;
- видео адаптер;
- сетевой адаптер.
8. Нейроагенты (Neugents) - агенты нейронных сетей
Если для Jasmine v1.21 под Windows NT4 рекомендовалось 64mB оперативной памяти, то для Jasmine ii рекомендуется 128mB. Дело в том, что Jasmine ii имеет не только трехмерный (3D) интерфейс, но использует элементы технологии нейронных сетей, так называемые нейроагенты, или Neugents. Это программные модули, с помощью которых процессы можно представлять в виде функций нескольких переменных, а значит анализировать и прогнозировать эти процессы. При этом Neugents могут работать не только с предварительным заданием условий, приводящих к экстремальным ситуациям (управляемое обучение), но и в режиме самообучения, выявляя условия экстремальных ситуаций и выдавая сигнал. В обоих случаях Neugents накапливают статистическую информацию о системе, анализируют ее и выдают прогноз.
McLaren Mersedes устанавливает именно Jasmine на компьютеры болидов "Формула 1" и с ее помощью осуществляет сбор телеметрической информации (усилие на тормоза, открытие дросс.заслонок, ускорения, перегрузки) ее обработку и вывод. У нас это звучит как АСУТП.
9. Заключение
Весь материал был изложен в расчете на привычное "табличное мышление". Но перестраиваться нужно и думать надо по новому. Переход к объектным СУБД особенно тяжелым будет для тех, кто давно и хорошо сидит на игле старых технологий. Переход на объектные технологии требует не столько изучения новых языков, сколько изменения способа мышления.
В своей книге "Объектно-ориентированный анализ и проектирование" Гради Буч (Grady Booch) пишет (дается с сокращениями), что:
Профессионалу требуется всего несколько недель, чтобы освоиться с семантикой и синтаксисом нового языка программирования. Но в несколько раз больше времени потребуется этому специалисту, чтобы начать понимать мощь и важность объектов! Наконец, может потребоваться более полугода экспериментов, чтобы он созрел до понимания того, как строятся объектные модели: обучение мастерству всегда требует времени.
Обучение на примерах часто оказывается эффективным и целесообразным.
Когда же организация накопит критическую массу приложений выполненных в объектно-ориентированном стиле, станет гораздо легче обучать этому делу новых сотрудников.
Для развития объектно-ориентированного мировоззрения необходимо:
- Обеспечить формальное обучение сотрудников элементам объектной модели.
- Начать с проектов с низким уровнем риска, допуская появление ошибок. По мере приобретения опыта, лучших можно направлять в другие команды в качестве наставников.
- Продемонстрировать сотрудникам примеры хорошо структурированных объектно-ориентированных систем.
Система достаточно проста в изучении, но это не значит, что она примитивна, т.е. она не для массового потребителя. По этому поводу основатель и президент CA Чарльз Ванг сказал: "Мы вовсе не стремимся к тому, чтобы массовый потребитель применял наши продукты. У нас другой рынок и мы останемся ему верны". Это чувствуется сразу, как только Вы начинаете заполнять опросный лист, заказывая продукты CA.
Анализ и проектирование (формирование системы) уже переходят в руки экспертов.
Создание приложений (как элемент реализации системы) переходит в руки пользователей (переход от алгоритмов к объектам приводит к переходу от программирования к конструированию сцен). И только небольшая ниша, называемая методами, пока еще требует в полном смысле слова программирования.

