1998 г
Дорогие читатели!
Актуальность темы хранилищ данных (Datawarehousing) и систем оперативной аналитической обработки данных (OLAP) продолжает повышаться. Сейчас трудно найти компанию, специализирующуюся на технологии систем баз данных, которая не представляла бы на рынке свои подходы, методологии и средства организации таких систем. Одной из наиболее известных компаний, специализирующихся в этом направлении, является NCR со своей СУБД Teradata, относящейся к категории high-end, т.е. обеспечивающей максимальную производительность при использовании соответствующих аппаратных средств. Я представляю Вашему вниманию пересказ статьи Сэма Стерлинга, посвященный подходу NCR к использованию чисто реляционной Teradata для эмуляции многомерных баз данных в сочетании с использованием нормализованной модели данных для выполнения непредвиденных аналитических запросов. Не могу сказать, что я в восторге от этой статьи. Наверное, автор мог бы написать ее более четко. Но это крик души практика. Ну не умеют практики хорошо писать. Спасибо, что хотя бы стараются. Надеюсь, что мой пересказ позволит Вам понять суть: многомерные модели позволяют избежать соединений, группирования и агрегации для заранее выбранного класса запросов. Но в реальной жизни аналитика возникают потребности в непредвиденных запросах, выводящих за пределы многомерных моделей. NCR предлагает поэтому использовать базовую нормализованную схему базы данных в качестве основы. Многомерность и денормализация эмулируются через представления. Вот так.
С уважением, Сергей Кузнецов
Teradata Review Fall 1998
Essential Modelling Options
Sam Sterling
Independent consultant, over the last 11 years has built and consulted on dozens of warehouses, using various databases.
Оригинал статьи можно найти по адресу http://www.teradatareview.com/Fall98/sterling.html
Несмотря на возникающие иногда религиозные войны между направлениями многомерного моделирования и построения схемы на основе третьей нормальной формы, истина состоит в том, что нужны оба подхода.
Когда меня спрашивают сегодня, какую позицию я занимаю в сражении между звезднообразной схемой и третьей нормальной формой (3NF), я упорно отвечаю: "ровно по середине". Некоторые полагают, что пригоден один из подходов, но на самом деле имеется место для каждого из них. Я прислушиваюсь к аргументам, читаю статьи и обзоры дискуссий, реализую разнообразные модели, но не думаю, что любой узкий выбор пригоден для всех ситуаций.
Третья нормальная форма является моделью сущностей, связей и атрибутов. При использовании этого подхода мир обычно представляется логическим и математическим образом, подобно подходу "кто, что, когда и как", применяемому в журналистике. Любой отход от этой "нормальной" модели называется денормализацией.
Многомерная модель представляет мир в терминах менее абстрактных понятий, таких как "сколько и как часто" - "фактах", появляющихся на интересующем нас пересечении измерений. Она "денормализована", поскольку в данном пересечении может содержаться много фактов, которые можно было бы поместить в одну "строку" таблицы.
К счастью для нас (людей из области информационных технологий и из мира бизнеса), Teradata предоставляет выбор физической реализации той и другой моделей. Я приведу обсуждение того, как все это работает и почему выбор является настолько важным.
3NF: За
Нормализованное представление вселенной является математической моделью, основанной на сущностях и их связях. Атрибуты каждой сущности описываются только один раз -- они соответствуют "ключу, ключу целиком и ничему, кроме ключа". Нормализация допускает задание творческих запросов, выходящих за рамки заранее предписанных измерений звездообразной схемы. Например, при использовании нормализованной модели можно увидеть, как связаны погодные условия с продажей определенных товаров или кредитоспособностью заказчика. При применении многомерной модели или средства оперативной аналитической обработки (On-Line Analytical Processing - OLAP) вы не можете просто добавить новую таблицу или источник данных. Вы должны либо денормализовать ее до таблицы фактов (представьте, какой объем дополнительной работы понадобится для этого), либо создать для нее новое измерение. Другим способом является добавление строк, что вызовет многократное увеличение таблицы против ее исходного размера. Вспомните, что во многих РСУБД понадобится согласовывать разделение и распределение дискового пространства. (См. вкладку "Как задать запрос вне звезды".)
Но имеются и другие доводы в пользу 3NF. Эта модель максимально увеличивает нашу гибкость. В гонке по построению склада данных конкурентное преимущество получает та компания, которая может наиболее быстро и эффективно реагировать на новые ситуации, и 3NF дает соответствующую возможность моделирования данных, оставляя за своими пределами бизнес-правила (такие как связи измерений).
Любое отклонение от реляционной логической модели, представляющей бизнес математически, порождает ограничение, с которым приходится жить в течение долгого времени. Иногда это осмысленно для бизнеса, но часто приходится в скором времени раскаиваться. Такие решения делают нас менее эффективными и реактивными, поскольку вынуждают изменять реализованную базовую модель вместо того, чтобы искать данные в другой (возможно, новой) таблице. Следование модели 3NF позволяет нам видеть наиболее дискретные (атомарные или детальные) аспекты предметов. Всегда проще построить нечто при наличии базисных строительных блоков вместо того, чтобы стараться выбросить ненужные части и вставить новое.
3NF: Против
Третья нормальная форма выставляет серьезные требования к базе данных. По причине нормализованности модель требует большего числа соединений, чем базисная звезднообразная схема или денормализованная модель. Помните, что для выполнения соединений требуются компьютерные ресурсы, которые могут быть вам недоступны.
К тому же третью нормальную форму более трудно понимать. Во многих складах данных на основе 3NF, которые мне пришлось реализовывать, имеется более 50 таблиц, в то время как в типичной звезднообразной схеме достаточно десяти. При прочих равных условиях реализация большего числа таблиц требует большего объема работы (в общем случае для спецификации 50 таблиц требуется в пять раз больше команд, чем для спецификации 10 таблиц, если только эти десять таблиц не являются сильно денормализованными). Кроме того, несмотря на особенности модели, требуется сообщить средству выполнения запросов, что нужно делать с таблицами, и чем больше существует таблиц, тем большая требуется работа.
Многомерные модели: За
Человеческие мозги думают в терминах измерений (обычно в двух, трех или четырех), поскольку таким образом мы привязываемся ко всему в мире - как пространственным объектам, существующим во времени. Это также способ нашего представления данных; многие вопросы бизнеса естественно сводятся к многомерным взглядам. Транзакция продажи происходит в определенном месте, в определенное время и вовлекает как товар, так и покупателя. В телефонный разговор вовлекаются тот, кто звонит, тот, кому звонят, время начала и время конца разговора, а также оборудование, поддерживающее разговор.
Измерения (география, время, предмет и человек) представляют затрагиваемые сущности (где, когда, что и кто). Коротко говоря, представления - это то, как мы представляем реальность в мыслях, словах и поступках. Поскольку я использовал термины "измерение" и "сущность" в одном предложении, можно видеть, что они не исключают друг друга. Можно использовать их как взаимно дополняющие для облегчения понимания жизни.
В большинстве продуктов OLAP и многих других пользовательских средствах для генерации SQL требуется использование схем "звезда" или "снежинка". Физическая реализация многомерной модели может существенно облегчить управление данными в сервере баз данных. Для некоторых баз данных обработка сложных соединений может создать огромную проблему. Наличие большой денормализованной таблицы фактов помогает СУБД избежать накладных операций, таких как соединения, сканирования, агрегирования и сортировки, путем создания составных данных и помещения их в том порядке, который наиболее вероятно запрашивается. Сама таблица фактов содержит иерархию.
Многомерная модель: Против
Для создания многомерной модели требуется разработать комбинацию составных данных, все DDL (операторы определения данных), программы извлечения данных; все сценарии нагрузки должны работать в соответствии с моделью и поддерживать ее. Многомерное моделирование уменьшает рабочую нагрузку СУБД и перекладывает работу на плечи разработчика базы данных. Очевидно, что это не идеально; база данных может работать быстрее и точнее, чем люди, у которых уже имеется трудная задача реализации сложного склада данных. Появляются дополнительные расходы, связанные с выполнением работы вручную.
Дополнительной ценой многомерного моделирования является свойственная денормализации (через внешние соединения) избыточность данных. Кроме того, для обеспечения доступа к большой денормализованной таблице фактов часто приходится создавать много индексов, чтобы избежать сканирований, и несколько уровней сводных таблиц, чтобы избежать как сканирований, так и агрегаций. СУБД должна поддерживать это при обновлениях, что иногда занимает больше времени, чем бы этого хотелось, и всегда отнимает ресурсы, которые правильнее было бы потратить на выполнение запросов. По определению (и даже по своей номенклатуре) многомерные модели ограничены построенными измерениями. Для большинства запросов и бизнес-вопросов этих измерений достаточно. Но известные вопросы, заранее подготовленные, ожидаемые вопросы сами по себе обладают относительно низкой значимостью. Они могут возвращать полезную информацию, но вы можете достичь понимания и мудрости, преобразующих деятельность компании, только размышляя "за пределами звезды".
Лучшее из двух миров
Если реализовать многомерную модель с использованием представлений (и индексов и сводных таблиц) поверх модели 3NF, то вы сможете получить быстроту выполнения и удобство "подготовленных" запросов и много средств, изолирующих пользователей от базовых таблиц и нудной работы (и ошибок) на SQL. Кроме того, вы сможете получить гибкость в расширении модели почти в любом направлении для включения преобретенных или других новых данных. При использовании модели 3NF физическая модель является логической моделью; преобразования очень просты и прямолинейны. Вы можете создать представления, позволяющие инструментальным средствам демонстрировать пользователю многомерную модель, облегчая понимаемость и упрощая использование. Наконец, вы можете обеспечить прямой доступ к нормализованной модели с помощью таких реляционных средств как BI/Query компании Hummingbird Communication Ltd. (www.hummingbird.com), или умудренные пользователи и профессионалы IT могут написать собственный SQL-код.
Имеются все основания использовать преимущества других подходов к моделированию, если они представляют какую-то ценность. Например, псевдоключи (идея, заимствованная из многомерного моделирования) при корректном использовании упрощают пользовательский доступ, повышают эффективность выполнения запросов и снижают уровень требований к общей нагрузке системы.
В Teradata используется этот гибрид физической модели 3NF и многомерных представлений, поскольку система очень хорошо обрабатывает соединения и обладает зрелым и надежным оптимизатором. Представления в Teradata не материализуются до выполнения соответствующих запросов, что делает возможным отражать в плане запроса с соединением потребности каждого индивидуального запроса, минимизировать объем данных, которые требуется перераспределять или дублицировать. Хэширование на первичном индексе упрощает разделение, и распределение памяти происходит только на уровне базы данных, а не на основе принципа таблица-раздел и индекс-раздел. В оптимизаторе Teradata используется пересечение индексов, что обеспечивает эффективность почти такого же уровня, который дают битовые индексы, без потребности в накладных расходах для их поддержки. Это означает, что Teradata нуждается в создании меньшего числа индексов, что приводит к дальнейшему сокращению требуемых объемов памяти и времени для поддержки индексов. Наличие возможности синхронного сканирования (sync scan) позволяет использовать время, требуемое для сканирования больших таблиц, для выполнения нескольких (и даже сотен и тысяч) параллельно выполняемых запросов, делающих одну и ту же работу, что повышает пропускную способность системы на несколько порядков. Это всего лишь несколько причин (к ним следует добавить параллелизм системы), благодаря которым Teradata минимизирует зависимость от сводных таблиц.
Однако реальное преимущество Teradata происходит от фактического устранения избыточных многомерных моделей и вероятного уменьшения чрезмерных требований к аппаратуре, поддерживающей многочисленные лавки данных (data marts). Вследствие простого размещения данных на основе хэширования Teradata делает возможной реализацию практически всех комбинаций подходов 3NF и звезднообразных схем. Если для поддержки бизнеса требуются расширение возможностей и ренормализация, можно переключиться со звезднообразной схемы на 3NF.
Оптимизация соединений малой и большой таблиц. Когда в 1988 г. Teradata впервые начала обслуживать сверхбольшие базы данных, обнаружились некоторые странные проблемы. Даже при использовании подхода с отказом от общих ресурсов (shared-nothing) для обработки и сканирования больших таблиц требуется большое время. В результате инженеры (включая меня) разработали методы, заставляющие оптимизатор сначала обрабатывать малые таблицы измерений, соединяя из с целью создания первичного индекса для большой таблицы фактов и сокращая тем самым время ответа для многих запросов. Эти методы были включены в оптимизатор Teradata выпуска 1990 г. Как показывает рис. 1, у большой таблицы (Sales) имеется составной первичный индекс, составленный из внешних ключей таблиц измерений Stores, Items и Weeks. В звезднообразной схеме все четыре таблицы логически (а иногда и физически) объединяются. На рисунке представлена физическая модель 3NF, и запрос, представленный на листинге 1, позволяет произвести выборку из Stores, Items и Weeks с пересечением с указанными данными из Sales. В частности, здесь мы хотим узнать общий объем продаж всех телевизоров в некоторой группе штатов (скажем Colorado и Minnesota) в течение двух недель перед Super Bowl, и мы хотим видеть это в соответствии с размером экрана телевизора и в лексикографическом порядке названий магазинов. Указанное представление эмулирует звезнообразную схему, в запросе не принимается во внимание базовая физическая модель, и запрос очень прост. (Особенности модели скрываются представлением.)
SELECT store, SUM(sales$), SUM(salesQty), Substr(itemdesc, 1, 3)
Named screensize, itemdesc
FROM SalesStar
WHERE weeknbr BETWEEN 9805 AND 9806
AND state IN ('CO', 'MN')
AND subdept = 'Television'
ORDER BY Sales$ Desc, store
GROUP BY screensize;
View:
CREATE VIEW SalesStar AS
SELECT (*)
FROM SALES B, STORES S, ITEMS I, WEEKS W
WHERE B.STORE_NBR = S.STORE_NBR
AND B.ITEM_NBR = I..ITEM_NBR
AND B.WEEK = W.WEEK;
Листинг 1. Запрос к таблице Sales
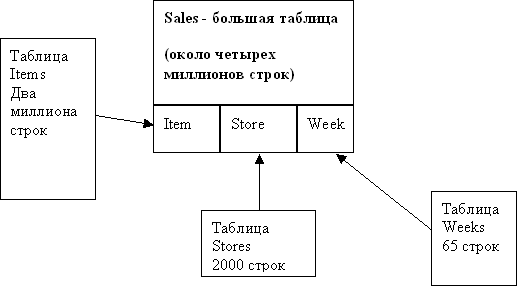
Рис. 1. Таблица Sales со звезднообразной схемой и составным первичным индексом
Оптимизатор Teradata знает, что таблица Weeks содержит меньше всего строк, поэтому он выбирает только те недели, которые нас интересуют. Затем он копирует эти две строки в каждое виртуальное AMP (параллельное устройство Teradate), помещая их в кэш. Поскольку оптимизатор знает, что таблица Stores не содержит много строк, и имеется индекс на столбце state, он выбирает около 30 строк для указанных штатов, соединяет их с двумя строками уже в основной памяти и копирует результат в каждое AMP. Оптимизатор не знает, что нам требуется только немногая часть товаров из таблицы Item, содержащей два миллиона строк, пока не пройдет по индексу на столбце subdepartment и не выберет телевизоры.
Теперь оптимизатор получает, скажем, 2433032 строк. Он перераспределяет эти строки с помощью хэширования (таким же образом, что и таблицу Sales) в соответствующие AMP, по ходу дела сортируя строки.
Наконец, оптимизатор сопоставляет хэш-коды полученной промежуточной таблицы и таблицы Sales -- выполняя соединение слиянием -- и возвращает результат в отсортированном порядке, производя их агрегацию по store. На листинге 2 приведено перефразированное объяснение плана соединения.
- Каждое AMP производит выборку из таблицы Weeks по условию <Week selection criteria>. Промежуточный результат (Spool) дублируется на всех AMP.
- Все AMP производят выборку из таблицы Stores по условию <Store selection criteria>. Выполняется соединение со Spool по фиктивному условию (). Spool дублируется на всех AMP.
- Все AMP производят выборку из таблицы Items по условию <Item selection condition>. Выполняется соединение со Spool по фиктивному условию. Результат перераспределяется между всеми AMP и сортируется.
- На всех AMP выполняется соединение Sales и Spool с использованием MERGE JOIN (сканирование строк с сопоставлением хэш-кодов).
Пользовательские представления. Когда разработчики Teradata работали над методами, влияющими на планы соединений, они формализовали и реализовали их с использованием представлений. Хотя теперь оптимизатор стал умнее, чем восемь лет назад, представления остаются полезными в обеспечении инструментальных средств и людей возможностью не заботиться обо всех базовых таблицах.
Нежелательно заставлять людей, которые думают в терминах фиксированных измерений, реконструировать эти измерения для каждого нового запроса. Пользовательские представления упрощают жизнь пользователей, поддерживая в то же время согласованность применяемых бизнес-правил.
Новый индекс соединения. Индекс соединения, появившийся в Teradata V2R2.1, может комбинировать таблицы детальных данных (фактов) и связанные таблицы в одной индексной структуре, избавляя от потребности соединять таблицы во время выполнения. Можно рассматривать индекс соединения как комбинацию таблицы фактов и некоторого числа таблиц измерений, если внести в этот индекс достаточно выразительные данные. Teradata автоматически распространяет изменения в базовых таблицах в индекс соединения, так что дополнительные расходы на поддержку минимальны. Оптимизатор автоматически опознает наличие индекса соединения и использует его, включая подмножества и надмножества.
Сводные таблицы. Использование нормализованной модели не может удовлетворить все потребности. Для некоторых приложений имеет смысл создавать отдельные сводные структуры внутри среды склада данных. Для облегчения поддержки среды начните с обобщения таблиц на физической машине, где размещается склад данных. Иногда это обобщение все равно не сможет обеспечить требуемую производительности (например, для систем обработки телефонных звонков). В таких экстремальных случаях может быть оправдано размещение приложения на физически отдельной платформе.
Teradata допускает и поощряет использование сводных таблиц, когда это имеет смысл
если они обеспечивают существенное улучшение реактивности для большого числа запросов с малыми накладными расходами на сопровождение. Но при использовании Teradata сводные таблицы не требуются слишком часто по причине наличия развитых возможностей оптимизатора и параллельной обработки. Поэтому не планируйте использование сводных таблиц, пока вы не знаете, какие запросы будут задавать пользователи и как часто они будут это делать. Проанализируйте доходы и расходы прежде, чем потратить множество усилий для построения и поддержки сводных таблиц.
Что реально ставится на карту
Teradata предоставляет возможность создания модели, наиболее соответствующей имеющейся задаче, с минимальными уступками технологическим ограничениям. Многие компании страдают от того, что путают логические и физические модели, поскольку мыслят в терминах конкретных продуктов. Никогда не разрешайте технологии руководить вашим бизнесом. Не очаровывайтесь бросающимися в глаза продуктами или любимцами Уолл Стрит. Не давайте стандартам управлять вашей компанией и разрушать ее. Подход "один размер, пригодный для всех" -- как и в случае одежды -- это маркетинговый миф. В случае складов данных нет размера, годного для всего. Решение о том, стоит ли создавать физическую многомерную модель, должно делаться не используемой СУБД, а соответствовать потребностям бизнеса.
Вкладка
Как задать запрос вне звезды
Предположим, что у нас имеется многомерная модель для заказанных товаров (Ordered Items) - одна для поставленных товаров (Shipped Items) и одна для полученных товаров (Received Items). Я могу пройти свою иерархию измерений, чтобы получить любой уровень Item, Store и Date. Просто, не правда ли?
Я могу узнать, сколько телевизоров получу в течение следующих нескольких дней. Хотя для этого требуется группирование, я встраиваю информацию о своей категории и своем отделе в таблицу фактов и могу спуститься по иерархии выбрать подмножество строк -- и достаточно быстро получить ответ. Не нужны соединения, строки, вероятно, уже сгруппированы и требуется минимальная агрегация. (Но если имеется нечто, что я должен знать на обобщенном уровне, мне, видимо, придется построить для этого таблицу.) Вероятно, более 80% запросов будут выглядеть подобным образом.
Но что делать, если я отвечаю за разгрузку товаров, а мой лучший рабочий будет отсутствовать на службе в следующие два дня? Мне может понадобиться узнать, какие из ожидаемых поставок слишком велики или слишком тяжелы, чтобы с ними можно было справиться усилиями оставшейся части бригады. Что из отправленного не будет получено (NOT IN в числе полученного) и что заказано, но еще не поставлено (возможно, UNION) c весом больше 80 фунтов, объемом в шесть кубических футов, длиной в шесть футов к каком-либо измерении или суммарной длиной каких-то двух измерений в семь футов? Вот так так!
У меня нет ничего из этой информации, включенного в звезду. Все это имеется в таблице Item -- и я могу выполнить с ней соединение. Но для этого я должен выйти за пределы звезды и не могу использовать свои обычные средства OLAP. Более того, мне придется рассматривать три разные звезды.
Средства подобные BI/Query компании Hummingbird позволяют взглянуть на модель (и, следовательно, на проблему) с реляционной точки зрения. Вы можете легко встроить в таблицу Item необходимые ограничения, соединить ее с Ships, исключить Received и добавить Orders c датой отправки в течение следующих двух дней.
Вы решаете свою незамедлительную проблему без потребности построения и внедрения новой схемы.

 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС

