1999 г
Уважаемые читатели!
Дон Чемберлин в последние годы не часто балует нас своими статьями. Тем приятнее было встретить его публикацию, посвященную особенностям выполнения в DB2 операций обобщенного группирования. По-моему, статья написана предельно ясно и дает правильное представление о полезных для анализа данных операциях ROLLUP и CUBE. Мне понравилось.
До скорых встреч, Сергей Кузнецов
DB2 Magazine Online, Winter 1998
Super Groups (www.db2mag.com/98w_cham.shtml)
Don Chamberlin
Член группы разработчиков DB2 в исследовательском центре IBM Almaden. Дон Чемберлин известен в мире баз данных с 1970-х, когда он был одним из основных архитекторов и разработчиков проекта System R.
При потребности задавать запросы, пересекающие несколько измерений, вам может понадобиться знакомство с этой новой возможностью DB2.
Раздел GROUP BY языка SQL является одним из самых старых и часто используемых средств языка. Он позволяет преобразовать таблицу в группу строк и вычислить некоторые свойства каждой группы, такие как число строк в группе или среднее значение столбца или выражения. В ранних версиях DB2 можно было формировать группы только одним способом: сопоставлением значений одного или нескольких столбцов, называемых столбцами группирования.
В пятой версии DB2 Universal Database (UDB) при формировании групп допускается большая гибкость. В дополнение к возможности группировки по отдельным столбцам DB2 UDB дает возможность группировать по выражениям, таким как SALARY + BONUS или YEAR(BIRTHDATE). В UDB также поддерживается новая возможность, называемая супергруппами, позволяющая выполнять в одном запросе более одного вида группировки. Эта возможность полезна, если имеется большая коллекция точек данных, привязанных к нескольким измерениям, таким как время, позиция и тип измерения, и требуется проанализировать данные, чтобы увидеть как они изменяются в каждом измерении.
Для иллюстрации супергрупп в DB2 UDB будет использоваться база данных переписи населения, приведенная на таблице 1. Чтобы помочь в понимании приводимых запросов строки в таблице Census приведены в порядке возрастания значений столбцов state, county и city, но, конечно, в самой таблице упорядочение отсутствует. Заметим, что таблица содержит несколько неопределенных значений -- некоторые даты рождения и величина дохода неизвестны, а для некоторых людей, возможно, проживающих в сельской местности, неопределенное значение содержит столбец city.
| NAME | CITY | COUNTY | STATE | BIRTHDATE | SEX | INCOME |
|---|
| Joe | Miami | Dade | FL | 8/20/55 | M | 32100 |
| Frank | Miami | Dade | FL | 6/05/57 | M | 40200 |
| Bob | Hialeah | Dade | FL | 3/21/57 | M | 33500 |
| Karen | Hialeah | Dade | FL | 8/23/55 | F | 43900 |
| Jim | (null) | Dade | FL | 10/24/56 | M | 29600 |
| Joan | (null) | Dade | FL | 11/15/56 | F | 36300 |
| Dave | Orlando | Orange | FL | 9/25/57 | M | 38000 |
| Linda | Orlando | Orange | FL | 5/13/55 | F | 46700 |
| Jeff | Taft | Orange | FL | 2/08/57 | M | 32600 |
| Pat | Taft | Orange | FL | 10/30/57 | F | 26500 |
| Sam | Baytown | Harris | TX | 3/92/55 | M | 28500 |
| Bill | Baytown | Harris | TX | 12/21/56 | M | 32800 |
| Mary | Houston | Harris | TX | (null) | F | 44700 |
| Susan | Houston | Harris | TX | 4/30/55 | F | (null) |
| Alex | Houston | Harris | TX | 7/11/57 | M | 30900 |
| John | Austin | Travis | TX | 1/06/56 | M | 38400 |
| Fred | Austin | Travis | TX | 10/25/56 | M | 42500 |
| Anne | (null) | Travis | TX | 8/17/55 | F | 34800 |
Таблица 1. Таблица Census
Традиционный запрос с GROUP BY мог бы реорганизовать таблицу Census в группы в соответствии со значениями одного из столбцов, как показывает следующий пример, в котором находится средняя сумма доходов в каждом штате:
SELECT state, avg(income) AS avg_income
FROM census
GROUP BY state;
При написании такого запроса может захотеться в придачу к средней величине дохода в каждом штате вычислить среднюю сумму дохода для всей таблицы переписи. В DB2 UDB наиболее эффективным способом получения такой информации является один проход по данным переписи с одновременным вычислением средней суммы доходов по штатам и общей средней суммы. Чтобы обеспечить возможность задать такой тип вопроса наиболее эффективным способом, DB2 UDB позволяет написать запрос, специфицирующий более одного вида группирования. Это делают возможным три новые фразы в разделе GROUP BY -- ROLLUP, CUBE и GROUPING SETS.
ROLLUP
ROLLUP можно использовать каждый раз, когда требуется анализ коллекции данных в одном измерении, но более, чем на одном уровне детальности. Можно включить ROLLUP в раздел GROUP BY с указанием списка выражений группировки. DB2 UDB сначала группирует данные по всем выражениям группировки, потом по всем выражениям, кроме последнего, потом по всем, кроме двух последних, и т.д. После группировки по только первому выражению система выполняет последнюю группировку, в которой образуется одна группа, включающая всю таблицу целиком. (Это звучит похоже на повторяющийся процесс, но реально все группировки выполняются одновременно за один проход по таблице.)
В следующем примере иллюстрируется мощность ROLLUP. Систему просят найти число людей и среднюю сумму дохода в каждом городе, графстве и штате, а также аналогичные показатели для всей таблицы переписи:
SELECT state, county, city,
count (*) AS population,
avg (income) AS avg_income
FROM census
GROUP BY ROLLUP (state, county, city);
Поскольку этот запрос не включает раздел ORDER BY, в результирующем наборе не гарантируется какая-либо упорядоченность строк. Однако, чтобы проиллюстрировать, каким образом вычислялся результат, в таблице 2 строки приведены в соответствующем порядке. Во-первых, имеются девять строк для групп, образованных группировкой по state, county и city; затем идут четыре строки для группировки по state и county с неопределенными значениями для city; затем - две строки для группировки по state с неопределенными значениями для county и city; и, наконец, одна завершающая строка для всей таблицы Census с неопределенными значениями для state, county и city.
Напомним, что порядок выражений в списке ROLLUP является существенным. Если одна разновидность группы логически содержится внутри другой (как county содержится внутри state), следует убедиться, что первой указывается самая включающая группа (state до county).
| STATE | COUNTY | CITY | POPULATION | AVG_INCOME |
|---|
| FL | Dada | Hialeah | 2 | 38700 |
| FL | Dade | Miami | 2 | 36150 |
| *FL | Dade | (null) | 2 | 32950 |
| FL | Orange | Orlando | 2 | 42350 |
| FL | Orange | Taft | 2 | 29550 |
| TX | Harris | Baytown | 2 | 30650 |
| TX | Harris | Houston | 3 | 37800 |
| TX | Travis | Austin | 2 | 40450 |
| TX | Travis | (null) | 1 | 34800 |
| *FL | Dade | (null) | 6 | 35933 |
| FL | Orange | (null) | 4 | 35950 |
| TX | Harris | (null) | 5 | 34225 |
| TX | Travis | (null) | 3 | 38566 |
| FL | (null) | (null) | 10 | 35940 |
| TX | (null) | (null) | 8 | 36085 |
| (null) | (null) | (null) | 18 | 36000 |
Таблица 2. Результаты запроса с ROLLUP
Как показывает таблица 2, один запрос вычислил четыре разных уровня группировки, для чего потребовалось бы четыре запроса без ROLLUP. Поэтому возможность ROLLUP обеспечивает большие преимущества в отношение и удобства, и эффективности. Однако, если внимательно посмотреть на результаты запроса, можно заметить наличие некоторого беспорядка. Результат содержит две строки (помеченные звездочками) для графства Dade, штат Florida с неопределенным значением city. В одной из этих строк значение population равно двум, в другой - шести.
Первая из этих строк представляет группу на уровне state, county, city, включающую людей, проживающих в графстве Dade, Florida в сельской местности вне какого-либо города. (Из таблицы Census видно, что таких людей двое - Jim и Joan.) С другой стороны, вторая строка представляет группу уровня state, county, включающую всех людей, проживающих в графстве Dade. (В таблице Census представлено шесть таких человек.) Поэтому можно сказать, что неопределенное значение в первой строке означает "нет города", а неопределенное значение во второй строке означает "все города". Понятно, что требуется какой-то способ различать эти случаи путем указания уровня группировки, относящегося к каждой строке. DB2 UDB обеспечивает функцию, называемую grouping и служащую в точности для этих целей.
Функция grouping предназначена для использования в запросах, производящих более одного типа группировки. Аргументом функции является один из столбцов группировки, и функция возвращает значение "1", если указанный столбец слит с группой более высокого уровня. Таким образом, для тех специальных строк, в которых неопределенное значение city означает "все города", значение grouping(city) есть "1"; для обычных строк значение grouping(city) есть "0".
Функцию grouping можно использовать несколькими способами. Когда запрос с ROLLUP выполняется из прикладной программы, следует применять функцию grouping к каждому столбцу списка ROLLUP и считывать результаты в переменные основной программы для использования при интерпретации строк результата запроса. Когда функция grouping возвращает "1", ее столбец-аргумент содержит неопределенное значение, которое следует интерпретировать как "все значения".
Если запрос выбирает значения для их непосредственного отображения на экране, можно использовать функцию grouping в выражении CASE, в котором указана специальная строка для представления "всех значений". Для этой цели можно использовать любую строку, но, конечно, стоит выбрать строку, которую легко отличить от допустимого значения данных. В следующем запросе выражения CASE используются для отображения строки "(-all-)" вместо неопределенного значения, когда функция grouping показывает, что неопределенное значение представляет "все значения":
SELECT CASE grouping(state)
WHEN 1 THEN '(-all)'
ELSE state END AS state,
CASE grouping (county)
WHEN 1 THEN '(-all-)'
ELSE county END AS county,
CASE grouping (city)
WHEN 1 THEN '(-all-)'
ELSE city END AS city,
count(*) AS pop,
avg(income) AS avg_income
FROM census
GROUP BY ROLLUP(state, county, city);
В таблице 3 показаны результата запроса. Как видно, легко отличить строку, которая представляет людей в графстве Dade с неопределенными городами от строки, представляющей группу всех людей в графстве Dade независимо от города.
| STATE | COUNTY | CITY | POPULATION | AVG_INCOME |
|---|
| FL | Dade | Hialeah | 2 | 38700 |
| FL | Dade | Miami | 2 | 36150 |
| FL | Dade | (null) | 2 | 32950 |
| FL | Orange | Orlando | 2 | 42350 |
| FL | Orange | Taft | 2 | 29550 |
| TX | Harris | Baytown | 2 | 30650 |
| TX | Harris | Houston | 3 | 37800 |
| TX | Travis | Austin | 2 | 40450 |
| TX | Travis | (null) | 1 | 34800 |
| FL | Dade | (-all-) | 6 | 35933 |
| FL | Orange | (-all-) | 4 | 35950 |
| TX | Harris | (-all-) | 5 | 34225 |
| TX | Travis | (-all-) | 3 | 38566 |
| FL | (-all-) | (-all-) | 10 | 35940 |
| TX | (-all-) | (-all-) | 8 | 36085 |
| (-all-) | (-all-) | (-all-) | 18 | 36000 |
Таблица 3. Результаты запроса с ROLLUP при использовании функции grouping
В запросе с ROLLUP можно также использовать разделы WHERE и HAVING. Например, следующий запрос позволяет найти число женщин и среднюю величину их дохода для каждого города, графства и штата, для которых в переписи зарегистрировано не меньше двух женщин:
SELECT CASE grouping(state)
WHEN 1 THEN '(-all)'
ELSE state END AS state,
CASE grouping (county)
WHEN 1 THEN '(-all-)'
ELSE county END AS county,
CASE grouping (city)
WHEN 1 THEN '(-all-)'
ELSE city END AS city,
count(*) AS f_pop,
avg(income) AS avg_f_income
FROM census
WHERE sex = 'F'
GROUP BY ROLLUP(state, county, city)
HAVING count(*) >= 2;
Результаты, приведенные в таблице 4, показывают, что данные переписи содержат двух или более женщин в одном городе (Houston), в трех графствах (Dade, Orange и Harris); в двух штатах (Florida и Texas) и во всей таблице целиком.
| STATE | COUNTY | CITY | F_POP | AVG_F_INCOME |
|---|
| TX | Harris | Houston | 2 | 44700 |
| FL | Dade | (-all-) | 2 | 40100 |
| FL | Orange | (-all-) | 2 | 36600 |
| TX | Harris | (-all-) | 2 | 44700 |
| FL | (-all-) | (-all-) | 4 | 38350 |
| TX | (-all-) | (-all-) | 3 | 39750 |
| (-all-) | (-all-) | (-all-) | 7 | 38816 |
Таблица 4. Результаты запроса с ROLLUP и разделами WHERE и HAVING
CUBE
Мы обсудили полезность операции ROLLUP для группирования данных на разных уровнях детальности в одном измерении. (В примерах этим измерением была география.) При потребности анализировать данные путем их группировки в более, чем одном измерении, нужно использовать операцию CUBE.
Предположим, что нас интересует влияние пола и даты рождения на сумму дохода. Поскольку пол и дата рождения являются независимыми переменными, имеются четыре возможных способа группировки данных переписи:
- Группировка по sex и birthdate (типичный пример: женщины, родившиеся в 1955 г.)
- Группировка только по sex (типичный пример: женщины всех возрастов)
- Группировка только по birthdate (типичный пример: люди обоих полов, родившиеся в 1955 г.)
- Обработка таблицы как одной группы, содержащей оба пола и все даты рождения
Операция CUBE заставляет систему производить группировку по списку выражений всеми возможными способами. Например, если указывается GROUP BY CUBE (sex, year(birthdate)), то система будет формировать группы всеми четырьмя перечисленными выше способами. В запросе с CUBE, как и в запросе с ROLLUP, содержимое сгруппированного столбца появляется как неопределенное значение.
При взгляде на строку результата запроса с CUBE может оказаться трудно сказать, какой вид группы представляет строка. Например, строка с неопределенным значением birth_year может представлять группу с неопределенными годами рождения или группу, содержащую все возможные годы рождения. Чтобы различить группы, можно использовать функцию grouping.
В запросе с CUBE можно применять функцию grouping к любым столбцам или выражениям, используемым внутри операции CUBE. Как и в запросах с ROLLUP, если неопределенное значение выражения группировки имеет специальный смысл "все значения", функция grouping возвращает "1". Например, если grouping(sex) = 1, неопределенное значение столбца sex означает "оба пола". (Такая ситуация могла бы встретиться в строке, для которой данные группировались по году рождения, а не по полу.) Можно использовать функцию grouping внутри выражений CASE, чтобы выдавать на экран некоторое слово или символ для представления специального смысла "все значения". В следующем примере для этой цели используется "(-all-)". Нужно помнить, что в выражении CASE все возможные значения выражения должны иметь совместимые типы. В примере было необходимо использовать функцию char внутри CASE для преобразования year(birthdate) из целого типа в тип символьных строк, чтобы его тип был совместим со строкой "(-all-)".
SELECT CASE grouping(sex)
WHEN 1 THEN '(-all-)'
ELSE sex END AS sex,
CASE grouping(year(birthdate))
WHEN 1 THEN '(-all)'
ELSE char(year(birthdate))
END AS birth_year,
max(income) AS max_income
FROM census
GROUP BY CUBE(sex, year(birthdate));
В таблице 5 показаны результаты этого запроса. Операция CUBE, примененная к n измерениям, будет генерировать 2n различных видов групп. Так, GROUP BY CUBE (sex, year(birthdate)) произвела бы трехмерный результат, содержащий восемь видов групп. К каждой группе можно обычным образом применить раздел HAVING.
| SEX | BIRTH_YEAR | MAX_INCOME |
|---|
| F | 1955 | 46700 |
| F | 1956 | 36300 |
| F | 1957 | 26500 |
| F | (null) | 44700 |
| M | 1955 | 32100 |
| M | 1956 | 42500 |
| M | 1957 | 40200 |
| F | (-all-) | 46700 |
| M | (-all-) | 42500 |
| (-all-) | 1955 | 46700 |
| (-all-) | 1956 | 42500 |
| (-all-) | 1957 | 40200 |
| (-all-) | (null) | 44700 |
| (-all-) | (-all-) | 46700 |
Таблица 5. Результаты запроса с CUBE
GROUPING SETS
В предыдущих разделах обсуждалось, каким образом можно использовать операции ROLLUP и CUBE в разделе GROUP BY для выполнения детального анализа данных в одном или нескольких измерениях. DB2 UDB поддерживает также некоторые другие виды специальной группировки. Например, может понадобиться анализировать данные в одном измерении без выполнения полного ROLLUP, анализировать несколько измерений без формирования полного CUBE или просто выполнять определенные виды группировки, которые приходят в голову. DB2 UDB позволяет точно специфицировать желаемые виды групп с помощью операции GROUPING SET.
Для использования GROUPING SETS нужно просто указать список видов групп, которые должна сформировать система. Если некоторые критерии группировки включают более одного столбца или выражения, эти критерии заключаются в скобки. Можно использовать пустые скобки для обозначения единственной группы, которая охватывает всю таблицу. Запрос следующего примера разбивает данные переписи на группы по state и sex, затем формирует другие группы по году рождения и в завершение формирует одну большую группу, состоящую из всей таблицы Census. Для каждой группы отображается число человек в группе и средняя сумма дохода группы. Как и раньше, в этом запросе используется функция grouping для отображения специальной строки, когда неопределенное значение имеет специальный смысл "все значения".
SELECT CASE grouping(state)
WHEN 1 THEN '(-all-)'
ELSE state END AS state,
CASE grouping(sex)
WHEN 1 THEN '(-all')
ELSE sex END AS sex,
CASE grouping(year(birthdate))
WHEN 1 THEN '(-all)'
ELSE char(year(birthdate))
END AS birth_year,
count(*) as count,
avg(income) AS avg_income
FROM census
GROUP BY GROUPING SETS ((state, sex),
year(birthdate), ());
В таблице 6 приведены результаты этого запроса. Общее число групп в этом результате есть сумма числа групп, произведенных по каждому из трех наборов группировки: (state, sex) производит четыре группы, year(birthdate) производит четыре группы и пустой набор группировки () производит одну группу, представляющую всю таблицу; всего образуется девять групп.
| STATE | SEX | BIRTH_YEAR | COUNT | AVG_INCOME |
|---|
| FL | F | (-all-) | 4 | 38350 |
| FL | M | (-all-) | 6 | 34333 |
| TX | F | (-all-) | 3 | 39750 |
| TX | M | (-all-) | 5 | 34620 |
| (-all-) | (-all-) | 1955 | 6 | 37200 |
| (-all-) | (-all-) | 1956 | 5 | 35920 |
| (-all-) | (-all-) | 1957 | 6 | 33616 |
| (-all-) | (-all-) | (null) | 1 | 44700 |
| (-all-) | (-all-) | (-all-) | 18 | 36000 |
Таблица 6. Результаты запроса с GROUPING SETS
Множественные спецификации группировки
Теперь мы знаем, каким образом можно определять раздел GROUP BY для выполнения группировки по отдельным столбцам или выражениям, для проведения одномерного анализа с использованием ROLLUP или многомерного анализа с использованием CUBE, для создания произвольной коллекции групп с использованием GROUPING SETS. Требуется знать еще одну вещь: каким образом можно комбинировать эти возможности и использовать их совместно в одном разделе GROUP BY. Раздел GROUP BY может содержать несколько спецификаций группировки, разделенных запятыми. В каждой спецификации можно использовать любую из обсуждавшихся возможностей. Общее число групп, производимых разделом GROUP BY, получается путем перемножения числа групп, производимых каждой спецификацией группировки. Например, GROUP BY state производит три группы, и GROUP BY sex производит две группы, поэтому GROUP BY state, sex производит шесть групп. Аналогично, если GROUP BY ROLLUP (state, county) производит семь групп, и GROUP BY sex производит две группы, то GROUP BY ROLLUP (state, county), sex произведет 14 групп, формируемых по всем возможным комбинациям спецификаций группировки.
Синтаксическая диаграмма на рис. 1 показывает, как можно использовать различные виды группировки в расширенном разделе GROUP BY. DB2 UDB также поддерживает некоторые комбинации методов группировки (например, можно использовать ROLLUP и CUBE внутри операции GROUPING SETS), но для упрощения они отсутствуют в диаграмме. В документации DB2 UDB содержится детальная информация об этих комбинациях.
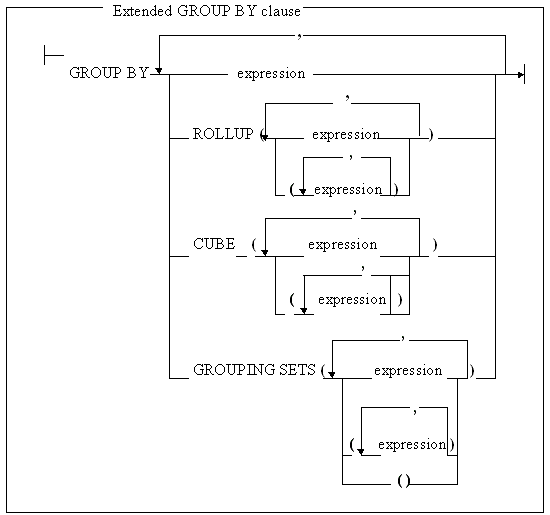
Рис. 1. В расширенном разделе GROUP BY возможны разные спецификации группировки
Действующий OLAP
Супергруппы в DB2 UDB являются мощным средством, позволяющим более просто выражать сложные аналитические запросы и дающим системе возможность более эффективно обрабатывать эти запросы. Используя супергруппы, можно выполнять многомерный анализ разного вида, который обычно связывается с отдельными продуктами хранилищ данных, напрямую над операционными данными базы данных DB2 UDB.
Эта статья основана на выдержках из последней книги Дона Чемберлина "A Complete Guide to DB2 Universal Database (Morgan Kaufmann, 1998), www.mkp.com.

 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС

