В ANSI SQL-92 [MS, ANSI] уровни изолированности (Isolation Levels)
определяются в терминах феноменов (phenomena): грязное чтение (Dirty Read),
неповторимое чтение (Non-repeatable Read) и фантомы (Phantom). В статье
показывается недостаточность феноменов и определений ANSI SQL для надлежащего описания нескольких популярных уровней изолированности, включая
стандартные блокировочные реализации рассматриваемых уровней. Исследуется
неоднозначность определений феноменов и дается более точное формальное
определение феномена. Вводятся новые феномены, которые лучше характеризуют предлагаемые
типы изолированности. Определяется новый тип многоверсионной изолированности
называемый изолированностью на основе моментальных снимков (Snapshot Isolation).
1. Введение
Возможность параллельного выполнения конкурирующих транзакций на различных
уровнях изолированности позволяет разработчикам приложений увеличить количество
одновременно выполняющихся транзакций, сохраняя их корректность. Нижние
уровни изолированности дают возможность увеличить количество одновременно
выполняющихся транзакций за счет риска получения размытого или несогласованного
состояния данных. Поразительно, что в то время, когда некоторые транзакции
выполняются на высшем уровне изолированности (совершенная сериализуемость),
совместно выполняющиеся транзакции на нижних уровнях изолированности могут работать с еще не зафиксированными или устаревшими данными, прочитанными
транзакцией ранее [GLPT]. Конечно, транзакции, выполняющиеся на
нижних уровнях изолированности, могут произвести в результате работы неправильные
данные. Разработчики приложений должны остерегаться распространения таких
ошибок при использовании некорректных данных транзакциями, выполняемыми на высших уровнях
изолированности.
В стандарте ANSI SQL-92 [MS, ANSI] определяются четыре уровня изолированности:
1) чтение незафиксированных данных (READ UNCOMMITED);
2) чтение зафиксированных данных (READ COMMITED);
3) повторимое чтение (REPEATABLE READ);
4) сериализуемость (SERIALIZABLE).
Они определяются на основе классического определения сериализуемости
и трех запрещенных последовательностей операций, называемых феноменами:
грязное чтение,, неповторимое чтение и фантомы. В стандарте нет четкого определения
понятия феномена, предполагается что феномен – это последовательность операций,
обладающая аномальным (возможно, не сериализуемым) поведением. В дальнейшем
изложении мы говорим об аномалиях, когда делаем необходимые добавления
ко множеству ANSI-феноменов. Показанное ниже техническое различие между
аномалиями и феноменами несущественно для качественного понимания сути
вопроса.
Уровни изолированности ANSI родственны по поведению планировщику блокировок.
Некоторые планировщики блокировок позволяют транзакциям варьировать границы
и продолжительность устанавливаемых ими запросов блокировок, таким образом
отступая от чистой двухфазной блокировки. Эта идея была предложена в [GLPT],
где степени согласованности определяются тремя способами: на основе механизма блокировок,
графов потоков данных и аномалий. В стандарте ANSI SQL определение уровней
изолированности дается в терминах феноменов (аномалий), чтобы
допустить реализации
стандарта SQL, основанные не только на механизме блокировок.
В этой статье показан ряд слабых мест ANSI в определении уровней изолированности
с помощью аномалий. Определения трех ANSI-феноменов двусмысленны. Они даже
в самой свободной своей интерпретации не исключают некоторые аномальные
последовательности операций в историях выполнения транзакций. Это приводит
к нескольким нетривиальным следствиям. В частности, уровни изолированности,
реализованные с помощью механизма блокировок, имеют характеристики, отличные
от характеристик их ANSI-эквивалентов. Это удручает, так как в коммерческих
системах обычно используются реализации, основанные на блокировках.
Кроме этого, ANSI-феномены не различаются типы поведения, возможные на каждом
уровне изолированности, распространенные в коммерческих системах. Чтобы точно определить уровни изолированности, предлагается ввести
дополнительные феномены.
Во втором разделе вводится основная терминология, связанная с уровнями
изолированности. Определяются ANSI SQL и блокировочные уровни изолированности.
В третьем разделе исследуются недостатки уровней изолированности в ANSI
SQL и предлагается к рассмотрению новый феномен. Также даны определения
других популярных уровней изолированности. Проводятся сравнительные параллели
между уровнями изолированности в ANSI SQL и степенями согласованности,
определенными в [GLPT] в 1977 году. Они также охватывают определения устойчивости
курсора и повторимого чтения, данные Крисом Дейтом в [DAT]. Обсуждение
уровней изолированности на основе однородной общеупотребительной терминологии позволяет избежать непонимания, происходящего от употребления своей собственной
терминологии.
В четвертом разделе описан механизм многоверсионного управления параллельным
выполнением транзакций, названный изолированностью на основе моментальных снимков (Snapshot Isolation). Он позволяет избежать
феноменов ANSI SQL, но не является сериализуемым. Изолированность на основе моментальных снимков
интересна тем, что обеспечивает промежуточный уровень изолированности,
лежащий между уровнями чтением зафиксированных данных и повторимым чтением. Новый
формализм (описанный в более полной версии этой статьи [OOBBGM]) соединяет
в себе промежуточный уровень изолированности для многоверсионных данных
и классическую одноверсионную теорию блокировочной сериализуемости.
В пятом разделе исследуются несколько новых аномалий. Они позволяют
выделить различия между уровнями изолированности, введенными в третьем
и четвертом разделах. Дополнительные ANSI SQL-феномены, приводимые здесь,
позволяют точно определить изолированность на основе моментальных снимков и устойчивость курсора.
В шестом разделе представлено краткое резюме и сделаны выводы.
2. Определение изолированности
2.1. Концепция сериализуемости
Концепции транзакции и механизма блокировок хорошо документированы в
литературе [BHG, PAP, PON, GR]. В следующих нескольких абзацах делается
обзор терминологии, используемой в этой области.
Транзакцией называют упорядоченное множество операций, переводящих базу
данных из одного согласованного состояния в другое. История моделирует
перекрывающееся выполнение множества транзакций в виде линейно упорядоченной последовательности
их операций чтения и записи (вставки, модификации, удаления) определенных
элементов данных. Говорят, что две операции в истории конфликтуют, если
они выполняются различными транзакциями над одним и тем же элементом данных, и
хотя бы одна из них выполняет операцию записи этого элемента данных. Согласно [EGLT], это определение
можно широко интерпретировать в зависимости от того, что понимать под "элементом
данных". Это может быть строка таблицы, область страницы,
целая таблица или коммуникационный объект, такой, например, как сообщение
в очереди. Конфликтующие операции могут возникать не только на отдельных
элементах данных, но и на множествах элементов данных, покрываемых предикатными блокировками.
Отдельная история приводит к образованию графа зависимостей (dependency graph), определяющего
временные потоки данных между транзакциями. Операции зафиксированных
транзакций представляются вершинами графа. Если в истории операция op1
транзакции T1 конфликтует с операцией op2 транзакции T2 предшествует этой операции,
то пара <op1, op2> становится ребром графа зависимостей. Две истории
считаются эквивалентными, если они включают одни и те же зафиксированные транзакции
и один и тот же граф зависимостей. История называется сериализуемой, если
она эквивалентна последовательной истории (serial history), т.е. если она имеет
такой же граф зависимостей (межтранзакционный поток временных данных),
как если бы все транзакции в ней выполнялись поочередно.
2.2. Уровни изолированности в ANSI SQL
Разработчики ANSI SQL дали такое определение изолированности, которое
допускает широкий спектр механизмов реализации, не только механизм блокировки.
Они определили изолированность с помощью следующих трех феноменов (phenomena):
P1 (грязное чтение, Dirty Read): Транзакция T1 модифицирует некоторый элемент данных. После этого
другая транзакция T2 читает содержимое этого элемента данных до того,
как транзакция T1 выполняет операцию COMMIT (фиксируется) или ROLLBACK
(откатывается). Если T1 затем завершается операцией ROLLBACK, то получается, что
транзакция T2 прочитала элемент данных, который никогда не фиксировался и, значит, никогда реально не существовал.
P2 (неповторимое, или размытое чтение, Non-repeatable or Fuzzy Read): Транзакция T1 читает некоторый элемент данных. После этого другая
транзакция T2 модифицирует или удаляет этот элемент данных и фиксируется.
Если T1 после этого попытается прочитать этот элемент данных
снова, то она получит другое значение или обнаружит, что элемент данных
больше не существует.
P3 (фантомы, Phantom): Транзакция T1 читает набор элементов данных, удовлетворяющих некоторому условию <search condition>. После этого транзакция T2
создает элемент данных, удовлетворяющий этому условию, и фиксируется.
Если транзакция T1 повторит чтение с тем же условием <search condition>,
то получит уже другой набор данных, отличный от полученного в первый раз.
Ни один из этих феноменов не может произойти в последовательной истории.
Поэтому, по теореме о сериализуемости, они не могут произойти и в сериализуемой
истории [EGLT, BHG Теорема 3.6, GR Раздел 7.5.8.2, PON Теорема 9.4.2].
Истории, состоящие из операций чтения, записи, фиксации и отката, могут
быть записаны в сокращенной нотации: "w1[x]" обозначает операцию
записи транзакции 1 в элемент данных x (таким образом данные "модифицируются"), а "r2[x]" представляет операцию чтения x в транзакции 2. Операции
чтения и записи в транзакции
1 множества записей, удовлетворяющих предикату P, обозначаются r1[P] и w1[P] соответственно. Фиксация (COMMIT) и откат
(ROLLBACK) транзакции 1 обозначаются "c1" и "a1" соответственно.
Феномен P1 может быть переформулирован как запрет на следующего сценария:
(2.1) w1[x]...r2[x]... (a1 и c2 в любом порядке)
Словесное определение феномена P1 неоднозначно. Оно в действительности не настаивает на
том, чтобы T1 заканчивалась аварийным образом, а только утверждает, что если это
произойдет, то может случиться что-то плохое. Некоторые люди интерпретируют
P1 как:
(2.2) w1[x]...r2[x]... ((c1 или a1) и (c2 или a2) в любом порядке)
Если запретить P1 в варианте (2.2), то не будет допускаться любая история, в которой T1 модифицирует элемент данных x, а затем T2 читает элемент данных
x до того как T1 зафиксируется или откатится. Не требуется, чтобы T1 завершалась аварийно, или чтобы T2 фиксировалась.
Определение (2.2) является намного более свободной интерпретацией P1, чем (2.1), поскольку оно запрещает все четыре возможных варианта пар фиксация-откат транзакций
T1 и T2, когда в (2.1) запрещаются только две пары из четырех. Интерпретация
(2.2) феномена P1 запрещает все варианты последовательности выполнения, в которых что-то аномальное могло бы произойти в будущем. Мы называем
интерпретацию (2.2) свободной интерпретацией P1, а (2.1) – строгой интерпретацией
P1. Интерпретация (2.2) определяет феномен, который может привести к аномалии,
а (2.1) определяет реальную аномалию. Обозначим их P1 и A1 соответственно. Тогда:
P1: w1[x]...r2[x]... ((c1 или a1) и (c2 или a2) в любом порядке)
A1: w1[x]...r2[x]... ((a1 и c2) в любом порядке)
Аналогично, словесные определения феноменов P2 и P3 тоже имеют свободную
и строгую интерпретации. Обозначим свободные интерпретации через P2 и P3,
а строгие через A2 и A3:
P2: r1[x]...w2[x]... ((c1 или a1) и (c2 или a2) в любом порядке)
A2: r1[x]...w2[x]...c2...r1[x]...c1
P3: r1[P]...w2[y in P]... ((c1 или a1) и (c2 или a2) в любом порядке)
A3: r1[P]...w2[y in P] ...c2...r1[P]...c1
В третьем разделе все варианты интерпретаций феноменов рассматриваются
более подробно. Аргументируется необходимость выбора свободных интерпретаций.
Заметим, что в словесном ANSI SQL определении феномена P3 после чтения множества элементов данных, удовлетворяющих предикату P, запрещается только вставлять данные, которые попадают в область
действия этого предиката, а в определении P3, которое было приведено выше, запрещается
производить любую операцию записи (вставку, обновление, удаление), влияющую
на кортеж, который удовлетворяет предикату.
Далее в статье рассматривается концепция многозначной истории (multi-valued
history, MV-история, см. [BHG], Глава 5). Если не вдаваться в детали, в многоверсионной системе может одновременно
существовать несколько версий одного элемента данных. При каждом
чтения должно быть совершенно ясно, какую версию данных следует читать.
Известны попытки связать определения изолированности
ANSI с многоверсионными системами, а также с более распространенными одноверсионными
системами (single-version) (SV-истории) стандартного блокировочного планировщика.
Тем не менее, словесные определения феноменов P1, P2 и P3 подразумевают одноверсионные
истории. В следующем разделе показано, как мы их интерпретируем.
В таблице 1 приводятся четыре уровня изолированности, определенные в
ANSI SQL. Каждый уровень изолированности характеризуется соответствующим феноменом, который не должен быть свойственен поведению транзакций на данном уровне (в строгой или свободной интерпретации). Однако сериализуемый
уровень изолированности в ANSI SQL не определяется только в терминах феноменов.
В подразделе 4.28 "SQL-транзакции" [ANSI] отмечается,
что на уровне изолированности SERIALIZABLE должно обеспечиваться поведение,
которое "общеизвестно как полностью сериализуемое выполнение".
Анализируя верхнюю часть таблицы и принимая во внимание эту оговорку, обычно
приходят к распространенному заблуждению, что запрет всех трех феноменов
приведет к сериализуемости. Истории, исключающие три указанных феномена,
в таблице 1 называются аномально сериализуемыми (ANOMALY SERIALIZABLE).
Таблица 1. Уровни изоляции ANSI SQL в терминах трех исходных феноменов
|
Уровень изолированности
|
Р1 (или А1)
грязное чтение
(Dirty Read)
|
Р2 (или А2)
размытое чтение
(Fuzzy Read)
|
Р3 (или А3)
фантом
(Phantom)
|
|
ANSI НЕЗАФИКСИРОВАННОЕ ЧТЕНИЕ
(ANSI READ UNCOMMITTED)
|
возможно
|
возможно
|
возможен
|
ANSI НЕЗАФИКСИРОВАННОЕ ЧТЕНИЕ
(ANSI READ UNCOMMITTED)
|
невозможно
|
возможно
|
возможно
|
ANSI ПОВТОРИМОЕ ЧТЕНИЕ
(ANSI REPEATABLE READ)
|
невозможно
|
невозможно
|
возможен
|
АНОМАЛЬНАЯ СЕРИАЛИЗУЕМОСТЬ
(ANOMALY SERIALIZABLE)
|
невозможно
|
невозможно
|
невозможен
|
Свободные интерпретации феноменов встречаются в большем количестве историй,
чем строгие интерпретации. Так как уровни изолированности определяются
запрещенными феноменами, то из того факта, что в третьем разделе мы выступаем в пользу их
свободных интерпретаций, следует, что мы агитируем за более ограничительные
уровни изолированности (в которые не допускается большее количество историй). В третьем
разделе показано, что даже если мы берем свободные интерпретации P1, P2
и P3 и запрещаем эти феномены, то мы все равно не получим истинной сериализуемости.
Было бы проще оотказаться в [ANSI] от P3 и использовать для
определения ANSI0-сериализуемости подраздел 4.28. В таблице 1 представлен
только промежуточный результат, окончательный результат будет представлен
в таблице 3.
2.3. Механизм блокировок
В большинстве SQL-продуктов изолированность реализована на основе механизма
блокировок. Поэтому полезно описать уровни изолированности ANSI SQL в терминах
блокировок, хотя при этом возникают некоторые проблемы.
Выполнение транзакций происходит под управлением планировщика блокировок.
Перед выполнением операции чтения или записи над отдельными элементами
данных или множеством элементов данных транзакция делает запрос планировщику блокировок на установление
соответствующей блокировки по чтению (Share) или записи (Exclusive). Две блокировки, запрошенные различными транзакциями
на одном и том же элементе данных, конфликтуют, если хотя бы одна из них
является блокировкой по записи.
Предикатная блокировка по чтению (записи) множества элементов данных,
определяемого задаваемым условием <search condition>, фактически блокирует
все элементы данных, удовлетворяющие этому условию. Это множество элементов
данных теоретически является бесконечным, поскольку включает все
элементы данных, уже присутствующие в базе данных и удовлетворяющие условию
<search condition>, и также все фантомные элементы данных, которых
еще нет в базе данных, но которые будут удовлетворять условию
<search condition>, если попадут в нее вследствие выполнения операции вставки
или модификации. В терминах SQL предикатная блокировка покрывает все присутствующие
в базе данных элементы, которые удовлетворяют предикату, и любые другие
элементы, которые могут быть стать удовлетворяющими этому предикату в результате выполнения операторов INSERT, UPDATE, or DELETE. Две
предикатных блокировки разных транзакций конфликтуют, если хотя бы одна из них является
блокировкой по записи и имеются (возможно, фантомные) элементы данных,
покрываемые обеими блокировками. Блокировка элемента данных (блокировка записи (record))
– это предикативная блокировка, в которой предикат именуюет данную запись.
Транзакция обладает правильно построенными (well-formed writes) записями (чтениями), если она запрашивает блокировку по записи (чтению)
каждого элемента данных или предиката перед выполнением операции записи
(чтения) этого элемента данных или множества элементов данных, определяемого предикатов. Транзакция называется правильно построенной (well-formed),
если правильно построены все ее операции записи и чтения. Транзакция
обладает двухфазными (two-phase writes) записями (чтениями), если она
не устанавливает новую блокировку по записи (чтению) на элемент данных
после снятия с него блокировки по записи (чтению). Транзакция осуществляет
двухфазное блокирование (two-phase locking), если она не запрашивает новeю
блокировку (по записи или чтению) после снятия какой-либо блокировки.
Блокировка, запрашиваемая транзакцией, называется долговременной (long
duration), если она не снимается до конца транзакции (фиксации или аварийного завершения). В противном случае блокировка называется
кратковременной (short duration). На практике кратковременные блокировки
обычно снимаются сразу же после завершения операции.
Если одна транзакция удерживает блокировку, а другая транзакция запрашивает
установку конфликтующей блокировки, то этот запрос не удовлетворяется до тех пор, пока конфликтующая блокировка первой транзакции не будет освобождена.
Фундаментальная теорема сериализуемости гласит, что правильно построенное
двухфазное блокирование гарантирует сериализуемость – каждая история, порождаемая
двухфазным блокированием, эквивалентна некоторой последовательной истории.
Наоборот, если транзакция не является правильно построенной или не
осуществляет двухфазное блокирование, то возможны несериализуемые истории
выполнения [EGLT]. Исключения составляют только вырожденные случаи.
В стремлении показать эквивалентность блокировок, зависимостей
и формализмов, основанных на аномалиях, в статье [GLPT] определялись четыре
степени согласованности (degrees of consistency). Определения аномалий
(см. определение 1) были слишком расплывчатыми. Авторов этой статьи продолжают критиковать
за этот аспект определений (см. также [GR]). Испытание временем смогли выдержать только более строгие
математические определения в терминах историй, графов зависимостей
и блокировок.
Уровень согласованности
= Блокировочный уровень
изолированности
|
Блокировки по чтению на
элементах данных и предикатах
(одинаковы, если нет замечаний)
|
Блокировки по записи на
элементах данных и предикатах
(везде одинаковы)
|
|
Степень 0
|
Ничего не требуется
|
Правильно построенные записи
|
Степень 1 = блокировочное
чтение незафиксированных данных
(Locking READ UNCOMMllTED)
|
Ничего не требуется
|
Правильно построенные записи
Долговременные блокировки по записи
|
Степень 2 = Блокировочное
чтение зафиксированных данных
(Locking READ COMMITTED)
|
Правильно построенные чтения
Кратковременные блокировки по чтению
(в обоих случаях)
|
Правильно построенные записи
Долговременные блокировки по записи
|
Таблица 2. Степени согласованности и блокировочные уровни изоляции, опреляемы в терминах блокировок
Устойчивость курсора (см. разд. 4.1)
(Cursor Stability)
|
Правильно построенные чтения
Блокировка по чтению удерживается
на текущем элементе курсора
Кратковременные предикатные
блокировки по чтению
|
Правильно построенные записи
Долговременные блокировки по записи
|
Блокировочное
повторимое чтение
(Locking REPEATABLE READ)
|
Правильно построенные чтения
Долговременные блокировки по чтению
на элементах данных
Кратковременные предикатные
блокировки по чтению
|
Правильно построенные записи
Долговременные блокировки по записи
|
Степень 3 = Блокировочная
сериализуемость
(Locking SERIALIZABLE)
|
Правильно построенные чтения
Долговременные блокировки по чтению
(в обоих случаях)
|
Правильно построенные записи
Долговременные блокировки по записи
|
Во таблице 2 определяется несколько типов изолированности в следующих
терминах: области действия блокировок (элементы или предикаты), режимы (по
чтению или по записи) и продолжительность (кратковременные или долговременные).
Мы полагаем, что блокировочные уровни изолированности, называемые блокировочным чтением незафиксированных данных (Locking READ UNCOMMITTED), блокировочным чтением зафиксированных данных (Locking READ COMMITTED), блокировочным повторимым чтением (Locking REPEATABLE READ) и блокировочной сериализуемостью (Locking SERIALIZABLE), подразумевались в определениях уровней изолированности ANSI SQL,
но, как демонстрируется позже в этой статье, они существенно отличаются от тех, которые перечислены в
таблице 1. Следовательно, необходимо
различать уровни изолированности, определяемые в терминах блокировок, и
уровни изолированности ANSI SQL, определяемые с помощью феноменов. Поэтому названия уровней изолированности в таблице 2
имеют префикс "Блокировочные", а в таблице 1 – "ANSI".
В [GLPT] определяется согласованность Степени 0, на которой разрешаются
грязное чтение и запись (Dirty Reads and Writes). Требуется только
атомарность операций. Степени 1, 2 и 3 аналогичны Locking
READ UNCOMMITTED, Locking READ COMMITTED и Locking SERIALIZABLE соответственно. Ни одна степень согласованности
не соответствует уровню изолированности Locking REPEATABLE READ.
Дейт и IBM [DAT, DB2] поначалу использовали термин "повторимые чтения" (Repeatable Reads) для обозначения сериализуемости или блокировочной сериализуемости.
Этот термин кажется более понятным, чем термин "третья степень
изолированности" [GLPT], хотя по значению они идентичны. Значение термина ANSI SQL REPEATABLE READ отличается
от значения оригинального определения, данного Дэйтом, и мы полагаем, что принятая в ANSI SQL терминология является неудачной. Поскольку аномалия P3 специальным образом не
исключается на уровне изолированности ANSI SQL REPEATABLE READ, из
определения P3 ясно, что чтения НЕ являются повторимыми! В таблице 2 мы продолжаем неправильно использовать этот термин в Locking REPEATABLE READ, чтобы соответствовать определению ANSI. Аналогично, Дейт ввел термин "устойчивость курсора" (Cursor Stability)
как более понятное название для второй степени изолированности с дополнительной
защитой от потерянных изменений через курсор, как объясняется ниже в подразделе 4.1
ниже.
Определение. Уровень изолированности L1 слабее (weaker) уровня
изолированности L2 (или L2 сильнее (stronger), чем L1; обозначим это как L1
<< L2), если все несериализуемые истории, удовлетворяющие критериям
уровня L2, также удовлетворяют критериям уровня L1, и существует хотя бы
одна несериализуемая история, возможная на уровне L1 и невозможная на
уровне L2. Два уровня изолированности L1 и L2 эквивалентны (equivalent), что
обозначается как L1 == L2, если множества допустимых несериализуемых историй
на уровнях L1 и L2 идентичны. L1 не сильнее (no stronger), L2, что обозначается
как L1 << L2, если L1 << L2 или L1 ==
L2. Два уровня изолированности
несравнимы (incomparable), что обозначается как L1 >><< L2, когда
каждый уровень изолированности допускает несериализуемую историю, недопустимую
на другом уровне.
Сравнивая уровни изолированности, мы различаем их только по несериализуемым
историям, которые могут произойти на одном уровне и невозможны на другом.
Два уровня изолированности могут также различаться по тем сериализуемым
историям, которые они допускают, но мы считаем, что Locking SERIALIZABLE == Serializable, хотя хорошо известно, что блокировочный планировщик не допускает все возможные сериализуемые истории.
Возможно, такие уровни изолированности несколько непрактичны, поскольку не допускают слишком много сериализуемых историй, но мы здесь
этот вопрос не рассматриваем.
Эти определения приводят к слудующему замечанию.
Замечание 1.
Locking READ UNCOMMITTED
<< Locking READ COMMITTED
<< Locking REPEATABLE READ
<< Locking SERIALIZABLE
В следующем разделе мы сравним определения ANSI с блокировочными определениями.
3. Анализ уровней изолированности ANSI SQL
Сначала сделаем позитивное замечание с том, что блокировочные уровни
изолированности соответствуют требованиям ANSI SQL.
Замечание 2. Блокировочные протоколы во таблице 2 определяют
блокировочные уровни изолированности, которые, как минимум, сильны настолько
же, как и соответствующие основанные на феноменах
уровни изолированности
в таблице 1. Доказательство этого утверждения приводится
в [OOBBGH].
Поэтому блокировочные уровни изолированности обеспечивают, по крайней мере, не меньшую изоляцию, чем одноименные ANSI-уровни. Могут ли они обеспечивать большую изоляцию? Ответ – да, даже на самом нижнем уровне. Чтобы
избежать феномена, который мы называем "грязной записью" (Dirty
Write), на Locking READ
UNCOMMITTED обеспечивается долговременная блокировка по записи, тогда как в
определениях ANSI SQL, основанных на аномалиях, такое аномальное
поведение не исключается на всех уровнях, кроме ANSI SERIALIZABLE. "Грязное чтение" определяется следующим образом.
P0 (Грязная Запись): Транзакция T1 модифицирует некоторый элемент данных. После этого другая транзакция
T2 тоже модифицирует этот элемент данных перед тем, как T1 выполнит COMMITT
или ROLLBACK. Если T1 или T2 после этого выполнит ROLLBACK, то становится
непонятным, каким должно быть корректное значение данных. Свободной
интерпретацией этого является следующая история:
P0: w1[x]...w2[x]... ((c1 или a1) и (c2 или a2) в любом порядке)
Одной из причин, по которым феномена грязной записи следует избегать, является то, что
он может нарушить согласованность базы данных. Предположим, что существует
ограничение на значения элементов данных x и y (например x = y). Обе транзакции, и T1, и T2,
поддерживают согласованность, если выполняются порознь. Однако ограничение легко может быть
нарушено, если транзакции параллельно производят операции записи в x
и y в разном порядке. Это может произойти, если не допускаются грязные
записи. Например, если возможна история
w1[x]...w2[x]...w2[y]...c2...w1[y]...c1
то "выживут" изменения, сделанные
T1 в y, и изменения, сделанные
T2 в x. Если
T1 записывает в оба элемента x и y 1, а
T2 – 2, то
результатом будет x = 2, y = 1, что нарушает ограничение x=y.
В [GLPT, BHG] и других работах рассматривается необходимость
защиты от феномена P0 для возможности автоматического отката транзакций.
Без защиты от P0 система не может аннулировать изменения, просто восстановив
предыдущие значения. Рассмотрим историю:
w1[x]w2[x]a1
Аннулирование
w1[x] и восстановление предыдущего значения x не являются удовлетворительными, потому
что в результате такого восстановления уничтожится и изменение x w2[x], сделанное
второй транзакцией. На если не аннулировать w1[x] путем восстанавления
предыдущего значения x, и вторая транзакция тоже выполнит откат, то нельзя будет
аннулировать изменение w2[x] путем восстановления
его предыдущего значения x! Именно поэтому даже самые слабые блокировочные системы
удерживают долговременную блокировку по записи. В противном
случае не смогли бы работать их механизмы восстановления.
Замечание 3. Изолированность в ANSI SQL должна быть изменена
таким образом, чтобы исключить P0 на всех уровнях изолированности.
Теперь мы приведем доводы в пользу того, почему требуются именно свободные интерпретации
всех трех ANSI-феноменов. Напомним, что строгие интерпретации выглядят следующим образом:
A1: w1[x]...r2[x]... ((a1 и c2) в любом порядке) (грязное чтение)
A2: r1[x]...w2[x]...c2...r1[x]...c1 (размытое или неповторимое чтение)
A3: r1[P]...w2[y in P] ...c2...r1[P]...c1 (фантом)
Согласно таблице 1, на уровне изолированности READ COMMITTED запрещаются аномалии A1, на уровне REPEATABLE READ – аномалии
A1 и A2, и на уровне SERIALIZABLE – аномалии A1, и A2, и A3.
Рассмотрим историю H1, в которой две транзакции производят перевод 40 долларов между строками x
и y в банковском балансе:
H1: r1[x=50] w1[x=10] r2[x=10] r2[y=50] c2 r1[y=50] w1[y=90] c1
История H1 демонстрирует несериализуемую, классическую проблему анализа несогласованности
(inconsistent analysis), когда транзакция T1 переводит 40 долларов с x
на y, сохраняя размер общей суммы баланса, равный 100, но транзакция T2
производит чтение в тот момент, когда баланс находится в несогласованном
состоянии при общей сумме равной 60. История H1 не подходит ни под одну
из аномалий A1, A2 и A3. В случае A1 одна из транзакций должна была бы завершиться аварийно; для A2 элемент данных должен был бы быть прочитан одной из транзакцией повторно; в случае A3 должна была бы измениться область истинности соответствующего предиката. Ни что из этого не
происходит в H1. Рассмотрим свободную интерпретацию A1, феномен P1:
P1: w1[x]...r2[x]... ((c1 или a1) и (c2 или a2) в любом порядке)
H1 действительно нарушает P1. Поэтому для того, что подразумевалось в стандарте ANSI SQL, следует выбирать интерпретацию
P1, а не A1. Именно свободная интерпретация является корректной.
Аналогичные доводы показывают, что для интерпретации второго ANSI-феномена
следует выбирать интерпретацию P2, а не A2. Различия между A2 и P2 видны
на примере следующей истории:
H2: r1[x=50] r2[x=50] w2[x=10] r2[y=50] w2[y=90] c2 r1[y=90] c1
H2 является несериализуемой – это еще одна проблема анализа несогласованности, где
T2 видит общий баланс, равный 140. В этой истории ни одна транзакция не
читает грязные (т.е. незафиксированные) данные. Таким образом, история
не противоречит P1. Кроме того ни один элемент данных не читается дважды и нет
изменяющейся области истинности соответствующего предиката. Проблема с H2 состоит в том, что
T1 читает значение y, когда значение x уже устарело. Если бы T1 прочитала
значение x снова, то оно бы обновилось, но она этого не делает, и A2 к
этому случаю не подходит. Заменяя A2 на P2, т.е. свободную интерпретацию,
мы решаем эту проблему:
P2: r1[x]...w2[x]... ((c1 или a1) и (c2 или a2) в любом порядке)
H2 будет отвегнута при попытке второй транзакции (w2[x=10]) перезаписать
значение переменной, прочитанной до этого первой транзакцией r1[x=50].
И наконец, рассмотрим A3 и историю
H3:
A3: r1[P]...w2[y in P] ...c2...r1[P]...c1 (фантом)
H3: r1[P] w2[insert y to P] r2[z] w2[z] c2 r1[z] c1
T1 осуществляет поиск по условию P=<T2 производит вставку нового служащего и потом обновляет
z – счетчик служащих в компании. Затем T1 читает значение счетчика служащих,
проверяет и находит рассогласование. Ясно, что эта история несериализуема,
но она допустима, поскольку не подходит под A3: никакой предикат не применяется дважды. Снова только свободная интерпретация решает проблему:
P3: r1[P]...w2[y in P]... ((c1 или a1) и (c2 или a2) в любом порядке)
Если запретить P3, то история H3 станет недопустимой. Ясно, что именно это подразумевалось в стандарте ANSI SQL. Дальнейшее обсуждение направлена на то, чтобы продемонстрировать полученные результаты.
Замечание 4. Строгие интерпретации A1, A2 и A3 имеют непредусмотренные
недостатки. Правильными являются свободные интерпретации. Определяя P1,
P2 и P3, мы полагаем, что в ANSI имелось в виду именно это.
Замечание 5. Множество феноменов ANSI SQL неполно. Может возникнуть ряд других аномалий. Чтобы
сделать определение блокировок, необходимо определить новые феномены.
Кроме того, необходимо переформулировать определение P3. В следующих определениях мы опускаем
(c2 или a2), что не ограничивает возможные истории.
P0: w1[x]...w2[x]... (c1 или a1) (Dirty Write, грязная запись)
P1: w1[x]...r2[x]... (c1 или a1) (Dirty Read, грязное чтение)
P2: r1[x]...w2[x]... (c1 или a1) (Fuzzy or Non-Repeatable Read, размытое или неповторимое чтение)
P3: r1[P]...w2[y in P]... (c1 или a1) (Phantom, фантом)
Заметим, что определение P3, приведенное выше, отличается от определения
P3 в ANSI SQL. Определение P3 в ANSI SQL запрещает только операции вставки
(и модификации в соответствии с некоторыми интерпретациями), попадающие
под область действия предиката, когда определение P3, приведенное выше,
запрещает любую операцию записи (вставки, модификации, удаления), попадающую
под предикат, по которому была произведена операция чтения.
Определения предложенных ANSI уровней изолированности в терминах этих
феноменов приведены в таблице 3.
Таблица 3. Уровни изолированности ANSI, определенные в терминах четырех феноменов
|
Уровень изолированности
|
Р0
грязная запись
(Dirty Write)
|
Р1
грязное чтение
(Dirty Read)
|
Р2
размытое чтение
(Fuzzy Read)
|
Р3
фантом
(Phantom)
|
|
ЧТЕНИЕ НЕЗАФИКСИРОВАННЫХ ДАННЫХ
(READ UNCOMMITTED)
|
невозможен
|
возможен
|
возможен
|
возможен
|
ЧТЕНИЕ ЗАФИКСИРОВАННЫХ ДАННЫХ
(READ COMMITTED)
|
невозможен
|
невозможен
|
возможен
|
возможен
|
ПОВТОРИМОЕ ЧТЕНИЕ
(REPEATABLE READ)
|
невозможен
|
невозможен
|
невозможен
|
возможен
|
СЕРИАЛИЗУЕМОСТЬ
(SERIALIZABLE)
|
невозможен
|
невозможен
|
невозможен
|
невозможен
|
В одноверсионных историях оказывается, что феномены P0, P1, P2 и P3
являются замаскированными версиями блокировок. Например, запрещая P0,
мы устраняем возможность записи второй транзакцией
элемента, до этого записанного первой транзакцией. Это эквивалентно
долговременной блокировке по записи на элементах данных или предикате.
Следовательно, грязная запись невозможна на всех уровнях. Подобно этому,
запрет P1 эквивалентен наличию правильно построенного чтения элементов данных.
Запрещет P2 означает долговременную блокировку элементов данных по чтению.
И наконец, запрет P3 эквивалентен долговременной предикатной блокировке
по чтению. Таким образом, уровни изолированности, определенные в таблице
3 с помощью этих феноменов, обеспечивают то же поведение, что и блокировочные уровни
изолированности, определенные в таблице 2.
Замечание 6. Определения блокировочных уровней изолированности
в таблице 2 эквивалентны феноменологическим определениям в таблице 3. Другими словами, P0, P1, P2 и P3 являются замаскированнымии определениями
блокировочного поведения.
В дальнейшем мы будем ссылаться на уровни изолированности, перечисленные в
таблице 3, по их именам из этой таблицы, подразумевая их эквивалентность
блокировочным уровням изолированности из таблицы 2. Когда мы будем употребляем
термины ANSI READ UNCOMMITTED, ANSI READ COMMITTED, ANSI REPEATABLE READ и ANOMALY
SERIALIZABLE, будут иметься в виду определения ANSI из
таблицы 1 (недостаточной, т.к. она не включает P0)
В следующем разделе показывается, что в ряде коммерческих реализаций
изолированности обеспечиваются уровни изолированности, которые
попадают между уровнями READ COMMITTED и REPEATABLE READ. Для
получения осмысленных уровней изолированности, которые позволили бы четко различить эти реализации, мы примем P0 и P1 в качестве
базиса, а затем добавим новые зарактерные феномены.
4. Другие типы изолированности
4.1. Устойчивость курсора
Тип изолированности "устойчивость курсора" (Cursor Stability) вводится для того, чтобы предотвратить
феномен потерянных изменений (Lost Update).
P4 (потерянные изменения, Lost Update): Аномалия потерянных изменений
происходит в том случае, когда транзакция T1 читает элемент данных, после
чего T2 изменяет этот элемент (на основе его предыдущего чтения), а затем T1 (основываясь на ранее прочитанном ею значении) модифицирует тот же элемент данных и фиксируется. В терминах историй это будет выглядеть следующим образом:
P4: r1[x]...w2[x]...w1[x]...c1 (Lost Update)
Как иллюстрируется в истории H4, проблема заключается в том, что даже
если транзакция T2 зафиксируется, ее изменения будут
потеряны.
H4: r1[x=100] r2[x=100] w2[x=120] c2 w1[x=130] c1
В конечном значении элемента x отражается только приращение 30, добавленное транзакцией T1.
Феномен P4 возможен на уровне изолированности READ COMMITTED, поскольку история H4 допустима,
если запрещены феномен P0 (фиксация транзакции, осуществляющей первую
запись, происходит до второй записи) и P1
(в котором требуется чтение после записи). Однако запрет феномена P2 устранит и
P4, поскольку w2[x] происходит после r1[x] и перед фиксацией или откатом
T1. Поэтому аномалия P4 полезна для различия промежуточных уровней изолированности
между уровнями READ COMMITED и REPEATABLE READ.
Уровень изолированности Cursor Stability расширяет блокировочное
поведение уровня READ COMMITED для SQL-курсоров, добавляя новую
операцию чтения (Fetch) по курсору rc (означает read cursor,
т.е. чтение по курсору) и требуя, чтобы блокировка устанавливалась на текущем элементе курсора. Блокировка удерживается до тех пор, пока курсор не будет перемещен (пока не изменитьтся его текущий элемент)
или закрыт, возможно, операцией фиксации. Естественно, транзакция, читающая по курсору, может изменить текущую строку (wc – запись по курсору), и в этом случае блокировка
по записи этой строки будет сохраняться до тех пор, пока транзакция не зафиксируется,
даже после передвижения курсора с последующей выборкой следующей строки. Между
rc1[x] и последующей wc1[x] не может вклиниться w2[x]. Следовательно, в этом случае предотвращается
феномен P4, переименованный ниже в P4C
P4C: rc1[x]...w2[x]...wc1[x]...c1 (Lost Update) (потерянные изменения)
Замечание 7.
READ COMMITTED << Cursor Stability << REPEATABLE READ
Режим Cursor Stability широко применяется в SQL-ориентированных системах для предотвращения
потери изменений строк, читаемых через курсор. В некоторых системах режим READ COMMITTED в действительности является более сильным, чем Cursor Stability. Стандарт
ANSI это допускает.
Техника установки курсора на элемент данных для сохранения его значения неизменным может использоваться для нескольких элементов за
счет применения нескольких курсоров. Таким образом, программисты могут использовать режим Cursor Stability для обеспечения изоляции Locking REPEATABLE READ для любых транзакций, оперирующих с небольшим,
фиксированным числом элементов данных. Однако этот метод неудобен и совсем не универсален. Поэтому всегда существуют истории, соответствующие
феномену P4 (и, конечно, более общему P2) и не устранимые на уровне Cursor Stability.
4.2. Изолированность на основе моментальных снимков
Транзакция, выполняемая на уровне изолированности на основе моментальных снимков (Snapshot Isolation), всегда читает
данные из моментального снимка (зафиксированных) данных, произведенного в момент начала
транзакции, который называется стартовой временной меткой (Start-Timestamp). В качестве этого момента может быть выбран любой момент до выполнения этой транзакцией первого чтения. Транзакции, выполняемая
на уровне Snapshot Isolation, никогда не блокируется при попытке произвести чтение до тех пор, пока можно поддерживать данные моментального снимка, соответствующего стартовой временной метке. В этом моментальном снимке также отражаются результаты всех операций записи (модификация, вставка и удаление) данной транзакции, используемые при повторном обращении этой транзакции (по чтению или записи) к тем же элементам данных. Изменения, производимые другими транзакциями после момента стартовой временной метки, для данной транзакции являются невидимыми.
Snapshot Isolation является разновидностью многоверсионных механизмов управления параллельными транзакциями (multiversion concurrency control). Он расширяет многоверсионный
смешанный метод (Multiversion Mixed Method), описанный в [BHG], в котором допускается чтение данных из моментального снимка для только читающих транзакций.
Когда транзакция T1 становится готовой к фиксации, она получает временную метку
фиксации (Commit-Timestamp), которая должна быть больше любой существующей Start-Timestamp и Commit-Timestamp. Транзакции T1 успешно фиксируется только в том
случае, если ни одна другая транзакция T2 c Commit-Timestamp, попадающей в интервал [Start-Timestamp, Commit-Timestamp] транзакции T1, не записала в те же элементы данных, что и T1.
В противном случае T1 завершается аварийно. Этот метод, называемый "Выигрывает
первая зафиксированная транзакция" (First-committer-wins), устраняет потерянные изменения (феномен
P4). Когда транзакция T1 фиксируется, ее изменения
становятся видны всем транзакциям, у которых Start-Timestamp больше, чем Commit-Timestamp транзакции T1.
Snapshot Isolation является многоверсионным (multi-version, MV) методом. Он мотивируется тем, что одноверсионные (single-version, SV) истории
не могут должным образом отображать временные последовательности операций.
В любое время для каждого элемента данных может иметься несколько версий,
созданных активными или зафиксированными транзакциями. Для операций чтения,
выполняемых транзакциями, должна выбираться подходящая версия. Рассмотрим
историю H1, приведенную в разд. 3, которая показывает потребность в
P1 при одноверсионном выполнении. При применении Snapshot Isolation та же последовательность
операций привела бы к многоверсионной истории:
H1.SI: r1[x0=50] w1[x1=10] r2[x0=50] r2[y0=50] c2 r1[y0=50] w1[y1=90] c1
Но в H1.SI имеются потоки данных сериализуемого выполнения. В [OOBBGM] мы показываем,
что все истории с уровня Snapshot Isolation могут быть отображены о
одноверсионные истории с сохранением зависимостей потоков данных (говорят,
что MV-истории эквивалентны по представлениям (View Equivalent) SV-историям; этот подход описывается в [BHG], Глава 5). Например, MV-история H1.SI может
быть отображена в сериализуемую SV-историю.
H1.SI.SV: r1[x=50] r1[y=50] r2[x=50] r2[y=50] c2 w1[x=10] w1[y=90] c1
Отображение MV-историй в SV-истории является единственным строгим
критерием, требуемым для помещения Snapshot Isolation
в иерархию изолированности.
Snapshot Isolation не является сериализуемой, потому что чтения транзакции происходят в один момент времени, а записи – в другой. Для примера рассмотрим следующую одноверсионную историю:
H5: r1[x=50] r1[y=50] r2[x=50] r2[y=50] w1[y=-40] w2[x=-40] c1 c2
H5 не является сериализуемой и имеет такие же межтранзакционные потоки
данных, которые могут возникнуть на уровне Snapshot Isolation (нет выбора
версии, читаемой транзакциями). Предполагается, что обе транзакции, записывающие новые
значения x и y, поддерживают то ограничение, что сумма x + y всегда должна быть
положительна. При полной изолированности обе транзакции поддерживают это ограничение,
а в истории H5 нарушают его.
Нарушение ограничения (constrant violation) является типичным и важным
типом аномалий, возникающих при параллельном выполнении транзакций. Индивидуальные
базы данных удовлетворяют ограничениям, задаваемым на множествах элементов
данных (например уникальность ключей, целостность ссылок, репликация строк
в двух таблицах и т.д.). Все вместе они образуют неизменяемый ограничительный
предикат базы данных C(DB). Предикат принимает значение True, если состояние
базы данных DB согласуется с ограничениями False в противном случае. Для
поддержки согласованности базы данных транзакции должны сохранять истинность
ограничительного предиката: если база данных является согласованным
до начала транзакции, то она останется согласованной и после ее
фиксации. Если транзакция читает содержимое базы данных, нарушающее ограничительный предикат, то она испытывает аномалию
нарушения ограничения из-за наличия параллельно выполняемой транзакции. Подобные нарушения ограничений называются
анализом несогласованности (inconsistent analysis) [DAT].
A5 (Нарушение ограничения на элементах данных). Предположим, что C()
– ограничение между двумя элементами данных x и y из базы данных. Ниже приводятся
две аномалии, возникающие при нарушении ограничения.
A5A (Искажение чтения, Read Skew). Предположим, что транзакция T1 читает
x, а затем другая транзакция T2 изменяет значения x и y и фиксируется.
Если теперь T1 прочитает значение y, она может обнаружить несогласованное состояние, и поэтому она произведет тоже несогласованное состояние.
В терминах историй мы имеем аномалию:
A5A: r1[x]...w2[x]...w2[y]... c2...r1[y]...(c1 или a1) (искажение чтения, Read Skew)
A5B (Искажение записи, Write Skew). Предположим, что транзакция T1 читает
x и y, которые согласованы в соответствии с предикатом C(), а затем другая транзакция
T2 читает значения x и y, записывает x и фиксируется. После этого T1
записывает y. Если на x и y было какое-нибудь ограничение, то
оно может нарушиться. В терминах историй:
A5B: r1[x]...r2[y]...w1[y]... w2[x]...(c1 или c2) (искажение записи, Write Skew)
Феномен размытого чтения (P2) является частным случаем искажения чтения,
где x=y. Более часто в транзакции читаются два разных, но взаимозависимых элемента
(например, поддерживается целостность ссылок). Искажение записи (Write Skew) (A5B) может
возникнуть при наличии ограничения в банке, когда балансам счетов разрешается быть отрицательными, пока сумма совместно поддерживаемых балансов остается положительной. Это приводит к такой аномалии, как в истории H5.
Понятно, что ни аномалия A5A, ни A5B не могла бы возникнуть в историях с исключенным феноменом P2, поскольку в обоих случаях транзакция T2записывает элемент данных, предварительно прочитанный незафиксированной
транзакцией T1. Поэтому феномены A5A и A5B полезны только для классификации
уровней изолированности, более слабых, чем REPEATABLE READ.
В ANSI SQL определение уровня REPEATABLE READ в строгой интерпретации
позволяет поддерживать частные случаи ограничений на строках, но в нем отсутствует общая концепция. Более конкретно,
Locking REPEATABLE READ из таблицы
2 обеспечивает защиту от нарушения ограничений на строках (row constraint
violations), а определение ANSI SQL из таблицы 1,
запрещая аномалии A1 и A2, – нет.
Возвращаясь к обсуждению уровня изолированности Snapshot Isolation, следует заметить,
что он поразительно силен, даже сильнее, чем READ COMMITTED.
Замечание 8.
READ COMMITTED << Snapshot Isolation
Доказательство. На уровне Snapshot Isolation механизм "выигрывает первая зафиксированная транзакция"
устраняет феномен P0 (грязная запись), а механизм временных меток не допускает возникновение феномена
P1 (грязное чтение). Отсюда следует, что Snapshot Isolation не слабее,
чем READ COMMITTED. Кроме того, на уровне READ COMMITTED возможен феномен A5A, но он невозможен при использовании механизма временных меток на уровне Snapshot Isolation. Следовательно, READ COMMITTED << Snapshot Isolation.
Заметим, что в одноверсионной интерпретации сложно описать, как в историях на уровне
Snapshot Isolation можно избежать феномена P2. Аномалия
A2 произойти не может, так как транзакция
на уровне Snapshot Isolation будут читать одно и то же значение элемента данных даже в том случае, когда в промежутках между чтениями этот элемент изменяется другой
транзакцией. Очевидно,
что в истории на уровне Snapshot Isolation может произойти аномалия искажение
записи (A5B) (например, в истории H5), а в одноверсионной интерпретации историй запрещет феномена P2 устраняет A5B. Поэтому на уровне Snapshot Isolation допускаются истории с аномалиями, которые не допустимы на уровне
REPEATABLE READ.
На уровне Snapshot Isolation невозможна аномалия A3. При повторном
чтении транзакции по предикату после изменения данных другой транзакцией
будет всегда выдаваться тот же самый старый набор данных. Но на уровне REPEATABLE READ аномалии вида
A3 возможны. Snapshot Isolation не допускает
историй с аномалией A3, но допускает истории с аномалией A5B, а у REPEATABLE READ все наоборот. Следовательно:
Замечание 9.
REPEATABLE READ >><< Snapshot Isolation
Однако Snapshot Isolation не устраняет P3. Рассмотрим следующее
ограничение: для множества рабочих заданий, определяемых предикатом, общая продолжительность этих заданий не должна превышать 8 часов. T1 читает по этому предикату, определяет,
что общая продолжительность равна 7 часам и добавляет новое задание продолжительностью 1 час.
Конкурирующая транзакция T2 делает то же самое. Поскольку обе транзакции вставляют разные элементы данных (а также разные значения ключей индексов, если таковые имеются), такой сценарий не устраняется механизмом "выигрывает первая зафиксированная транзакция" и может иметь место на уровне Snapshot Isolation.
Но в любой эквивалентной последовательной истории такой сценарий привел бы
к возникновению феномена P3.
Возможно, наиболее замечательно то, что на уровне Snapshot Isolation отсутствуют
фантомы (в строгой интерпретации A3 определения ANSI). Каждая транзакция
никогда не видит изменений, производимых параллельно выполняемыми транзакциями.
Таким образом, без дополнительных ограничений в подразделе 4.28 в [ANSI]
можно сформулировать следующий поразительный результат: (напомним, что в таблице
1 ANOMALY SERIALIZABLE соответствует определению ANSI SQL SERIALIZABLE)).
Замечание 10.
В историях на уровне Snapshot Isolation устраняются аномалии A1, A2 и A3.
Следовательно, в аномальной интерпретации ANOMALY SERIALIZABLE из таблицы
1
ANOMALY SERIALIZABLE << Snapshot Isolation.
На уровне Snapshot Isolation разрешается выполняться транзакциям
с очень старыми временными метками, что позволяет им совершать путешествия во времени, вопринимая исторические аспекты базы данных, не блокируя транзакции, изменяющие базу данных, и не блокируясь такими транзакциями. Конечно, если транзакции с очень старыми временными метками, попытались бы изменять данные, уже измененные более молодыми транзакциями
транзакциями, они были бы завершены аварийным образом.
Достаточно простая реализация механизма Snapshot Isolation была предложена
Ридом (Reed) в [REE]. Существует несколько коммерческих реализаций таких
многоверсионных баз данных. В InterBase 4 фирмы Borland [THA] и
сервере, лежащем в основе Exchange System компании Microsoft, обеспечивается Snapshot Isolation с механизмом "Выигрывает первая зафиксированная транзакция". Этот
механизм заставляет систему помнить все изменения (блокировки по записи),
принадлежащие каждой транзакции, которая фиксируется после снятия стартовой временной
метки каждой активной транзакции. Транзакция завершается аварийным образом,
если ее изменения конфликтуют с запомненными изменениями других транзакций.
"Оптимистический" подход Snapshot Isolation к управлению параллельным выполнением транзакций имеет очевидное преимущество
для только читающих транзакций, но его преимущества для изменяющих
транзакций до сих пор обсуждаются. Возможно, этот метод не подходит для долговременных
изменяющих данные транзакций, конкурирующих с высоко состязательными кратковременными транзакциями. Кратковременные транзакции будут фиксировать свои модификации быстрее и, следовательно, поскольку "выигрывает первая зафиксировавшаяся транзакция",
долговременные транзакции, вероятнее всего, будут постоянно откатываться.
(Заметим, что такой сценарий привел бы к реальной пролеме и в блокировочных реализациях,
а если принять решение не использовать долговременные изменяющие транзакции,
то будет применим и подход Snapshot Isolation.) Конечно, в случае, когда
кратковременные транзакции конфликтуют минимально, а долговременные ndash; только
читают данные, подход Snapshot Isolation должен дать хорошие результаты. В
случае сильной конкуренции между транзакциями сопоставимой длины Snapshot Isolation представляет собой классический оптимистический подход. Мнения относительно
его полезности расходятся.
4.3. Другие многоверсионные системы
Существуют другие модели многоверсионности. В некоторых коммерческих продуктах
поддерживаются версии объектов, но ограничивают область применения метода Snapshot Isolation только читающими транзакциями. (Например, SQL-92, Rdb и SET TRANSACTION
READ ONLY в некоторых других базах данных [MS, HOB, DRA]; в Postgres и Illustra
[STO, ILL] такие версии поддерживаются долговременно (long-term), и обеспечивается возможность темпоральных запросов.) В других реализациях допускаются
изменяющие транзакции, но не поддерживается защита "Выигрывает первая зафиксированная транзакция" (например, уровень изолированности READ CONSISTENCY
в Oracle [ORA]).
На уровне READ CONSISTENCY в Oracle каждому SQL-оператору перед
началом его выполнения дается самое свежее зафиксированное состояние базы
данных. Это похоже на то, как если бы стартовая временная метка транзакции
снималасьдля каждого SQL-оператора. Множество строк курсора формируется во время выполнения операции открытия курсора. Базовый механизм заново вычисляет
подходящую версию строки на основе временной метки оператора. Операции вставки, модификации
и удаления строк защищаются блокировками по записи, что приводит к политике "Выигрывает первая записавшая транзакция", а не к "Выигрывает первая зафиксированная транзакция". Уровень READ CONSISTENCY
сильнее, чем READ
COMMITTED (на нем исключается потеря изменений по курсору
(P4C)), но допускает неповторимое чтение (P3), потерю изменений в общем
случае (P4) и искажение чтения (A5A). Snapshot Isolation не допускает
P4 и A5A.
Если пристально посмотреть на стандарт SQL, то можно сказать, что он
трактует каждый оператор как атомарный. В начале каждого оператора имеется
сериализуемая подтранзакция (или временная метка). Можно представить иерархию
уровней изолированности, определяемых различными вариантами комбинации
оператора и присоединенной к нему временной меткой. (Например, в Oracle, операция
чтения по курсору имеет временнуя метку, снятую в момент открытия курсора.)
5. Резюме и Выводы
Подводя итоги, можно сказать, что оригинальные определения уровней изолированности в ANSI SQL имеют серьезные недостатки (как пояснялось в
разд. 3). Словесные определения противоречивы и неполны. Не исключается
феномен грязной записи (P0). В Замечании 5 мы даем рекомендации по тому,
как модифицировать определения уровней изолированности ANSI SQL, чтобы
сделать их эквивалентными блокировочным уровням изолированности в [GLPT].
В ANSI SQL уровень изолированности REPEATABLE READ мыслился как уровень,
на котором исключаются все аномалии, кроме фантомов. Определение, данное
в терминах аномалий в таблице 1, не достигает этой
цели, в отличие от блокировочного определения из таблицы 2. Выбор ANSI-термина REPEATABLE READ является вдвойне неудачным:
(1) повторяемые чтения не дают повторяемых результатов; (2)
в индустрии этот термин уже занят, и в некоторых продуктах
повторимое чтение означает сериализуемость. Мы рекомендуем найти для этого
уровня новое название.
Некоторые коммерчески популярные уровни изолированности, по степени
изолированности попадающие в интервал между уровнями REPEATABLE READ
и SERIALIZABLE из таблицы 3, в разд. 4 охарактеризованы
новыми феноменами и аномалиями. Все уровни изолированности,
о которых упоминается в этой статье, можно классифицировать, как показано
на рис. 1 и в таблице 4. Чем выше на рисунке расположен
уровень, тем он сильнее (см. определение в начале
подраздела 4.1). Уровни соединены линиями, помеченными
феноменами или аномалиями, которые отличают один уровень от другого.
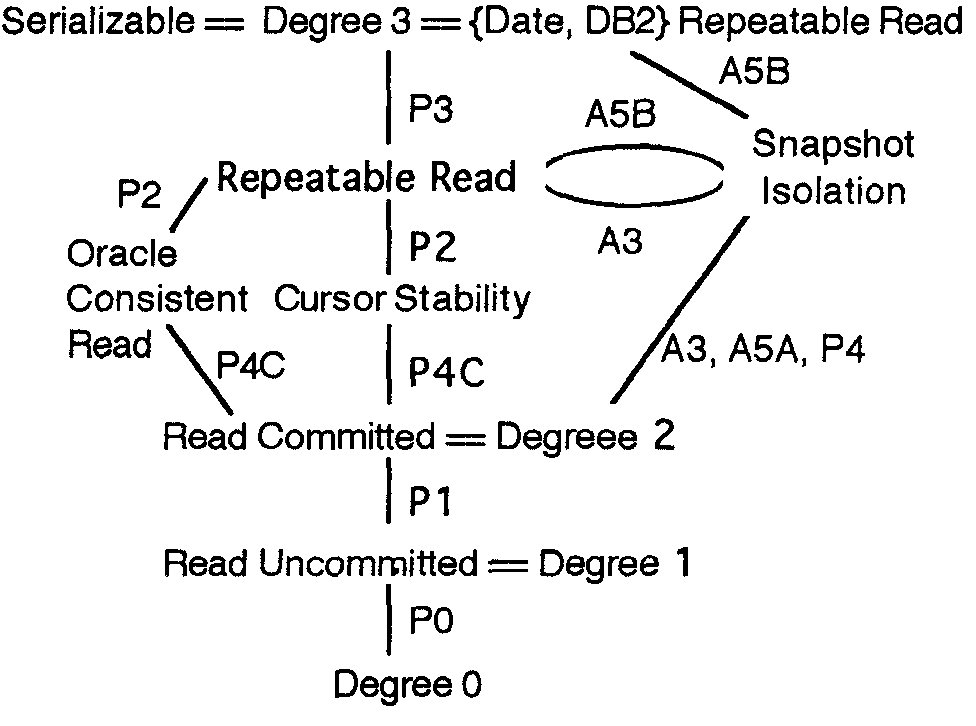
Рисунок 1. Диаграмма уровней изолированности и их взаимосвязей. Предполагается, что уровни изолированности ANSI SQL усилены в соответствии с замечанием 5 и таблицей 3. Дуги аннотированы названиями феноменов, отличающих уровни изолированности. Не показана потенциальная многоверсионная иерархия, расширяющая Snapshot Isolation на более слабые степени изолированности путем установки временных меток на пооператорной основе. Также не показаны исходные уровни изолированности ANSI SQL, основанные на строгой интерпретации феноменов P1, P2 и P3.
Таблица 4. Типы изолированности, характеризуемые возможными допустимыми аномалиями
Уровень
изолированности
|
Р0
Dirty
Write
|
Р1
Dirty
Read
|
Р4С
Cursor
Lost
Update
|
P4
Lost
Update
|
Р2
Fuzzy
Read
|
Р3
Phantom
|
A5A
Read
Skew
|
A5B
Write
Skew
|
READ
UNCOMMITTED
== Степень 1
|
невозможен
|
возможен
|
возможен
|
возможен
|
возможен
|
возможен
|
возможен
|
возможен
|
READ COMMITTED
== Степень 2
|
невозможен
|
невозможен
|
возможен
|
возможен
|
возможен
|
возможен
|
возможен
|
возможен
|
|
CURSOR
STABILITY
|
невозможен
|
невозможен
|
невозможен
|
иногда
возможен
|
иногда
возможен
|
возможен
|
возможен
|
иногда
возможен
|
|
REPEATABLE READ
|
невозможен
|
невозможен
|
невозможен
|
невозможен
|
невозможен
|
возможен
|
невозможен
|
невозможен
|
|
SNAPSHOT ISOLATION
|
невозможен
|
невозможен
|
невозможен
|
невозможен
|
невозможен
|
иногда
возможен
|
невозможен
|
возможен
|
ANSI SQL
SERIALIZABLE
== Степень 3
== Repeatable Read
Дейт, IBM,
Tandem,...
|
невозможен
|
невозможен
|
невозможен
|
невозможен
|
невозможен
|
невозможен
|
невозможен
|
невозможен
|
Заметим, что уровни ограниченной изолированности
для многоверсионных систем никогда раньше не классифицировались, хотя реализованы в нескольких продуктах. Во многих приложениях состязания за блокировки избегаются путем использования уровней изолированности типа Cursor Stability
или Read Consistency в Oracle. Snapshot Isolation имеет лучшие
характеристики, чем любой из таких уровней: исключаются аномалия потерянных изменений, некоторые фантомные аномалии (например описанная в ANSI SQL),
никогда не блокируются только читающие транзакции, и они не блокируют изменяющие транзакции.
Благодарности
Мы выражаем благодарность Крису Ларсону (Chris Larson) из Microsoft,
Алану Рейтеру (Alan Reiter), которые нашли несколько новых аномалий в ИЗОЛИРОВАННОСТИ
ОБРАЗА, Франко Путзолу (Franco Putzolu) и Анил Нори (Anil Nori) из Oracle,
Майку Убеллу (Mike Ubell) из компании Illustra и всем анонимным рефери
из SIGMOD за ценные предложения, которые улучшили эту статью. Сашил Джодиа
(Sushil Jajodia), V.Atluri и E.Bertino, которые прислали нам черновой вариант
своей работы [ABJ], касающейся уровней ограниченной изолированности для
многоверсионных историй.
Литература
[ANSI] ANSI X3.135-1992, American National Standart for Information
Systems – Database Language – SQL, November, 1992.
[ABJ] V.Atluri, E.Bertino, S.Jajodia, "A Theoretical Formuation
for Degrees of Isolation in Databases", Technical Report, George Mason
Iniversity, Fairfax, VA, 1995.
[BHG] P.A. Bernstein, V. Hadzilacos, N. Goodman, "Concurrency
Control and Recovery in Database Systems", Addison-Wesley, 1987.
[DAT] C.J. Date, "An Introduction to Database Systems",
Fifth Edition, Addison-Wesley, 1990.
[DB2] C.J. Date and C.J. White, "A Guide to DB2", Third
Edition, Addison-Wesley, 1989.
[EGLT] K.P. Eswaran, J. Gray, R. Lorie, I. Traiger, "The Notions
of Consistency and Predicate Locks in a Database System", CACM V 19.11,
pp. 624-633, Nov. 1978.
[GLPT] J. Gray, R. Lorie, G. Putzolu and, I. Traiger, "Granularity
of Locks and Degrees of Consistency in a Shared Data Base", in Readings
in Database Systems, Second Edition, Chapter 3, Michael Stonebraker, Ed.,
Morgan Kaufmann 1994 (ordinally published in 1997).
[GR] J. Gray and A. Reuter, "Transaction Processing: Concepts
and Techniques", Corrected Second Printing, Morgan Kaufmann 1993,
Section 7.6 and following.
[HOB] L Hobbs and K. England, "Rdb/VMS, A Comprehensive Guide",
Digital Press, 1991.
[ILL] Illustra Information Technologies, "Illustra User"s Guide",
Illustra Information Technologies, Oakland, CA. 1994.
[MS] J. Meiton and A.R. Simon, "Understanding The New SQL: A
Comlete Guide", Morgan Kaufmann, 1993.
[OOBBGM] P. O'Neil, E. O'Neil, H. Berenson, P. Bernstein, J. Gray,
J. Melton, "An Investigation of Transactional Isolation Levels",
UMass/Boston Dept. of Math &" C.S. Preprint.
[ORA] "PL/SQL User's Guide and Reference, Version 1.0",
Part. 800-V1.0, Oracle Corp., 1989.
[PAR] C. Papadimitriou, "The Theory of Database Concurrency
Control", Computer Science Press, 1986.
[PON] P. O'Neil, "Database: Principles, Programming, Performance",
Morgan Kaufmann, 1994, Section 9.5.
[REE] D. Reed, "Implementing Atomic Actions On Decentralized
Data", ACM TOCS 1.1, 1981, pp. 3-23.
[STO] M.J. Stonebraker, "The Design of the POSTGRES Storage
System", 13th VLDB, 1987, reprinted in Readings in Database Systems,
Second Edition, M.J. Stonebraker, Ed., Morgan Kaufmann, 1994.
[THA] M. Thakur, "Transaction Models in InterBase 4", Proceedings
of the Borland International Conference, June, 1994.

 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС

