2010 г.
Данные на лету:
как технология потокового
SQL помогает преодолеть кризис данных в Web 2.0
Джулиан Хайд
Перевод: Сергей Кузнецов
Оригинал: Julian Hyde. Data in Flight. How streaming SQL technology can help solve the Web 2.0 data crunch. ACM Queue, vol. 7, no. 11, December 2009
От переводчика
Статья, перевод которой предлагается вашему вниманию, очень популярна. В ней практически отсутствуют какие-либо технические детали, касающиеся организации систем обработки запросов к потоковым данным. Однако, на мой взгляд, она обеспечивает понимание сути таких систем, их отличий от систем управления базами данных, а также областей приложений, для которых такие системы могут быть полезными.
Следует заметить, что пик исследовательских работ, посвященных непрерывной обработке запросов (и не только над потоковыми данными) пришелся на начало 2000-х гг., когда, в частности, выполнялись известные проекты Aurora и TelegraphCQ. В дополнение к чрезвычайно краткому списку литературы, приводимому в статье, рекомендую обратить внимание на подборку статей, опубликованных в Bulletin of the Technical Committee on Data
Engineering, March 2003, Vol. 26, No. 1. Кроме того, я считаю несправедливым отсутствие ссылки на сайт компании StreamBase, основанной Майклом Стоунбрейкером (Machael Stonebraker) в 2003 г. и выпустившей первую производственную систему обработки запросов к потоковым данным.
Как показывает статья, теперь в секторе рынка таких систем имеется выбор. Насколько я понимаю, программное обеспечение, производимое компанией SQLStream, в которой работает автор статьи, можно бесплатно скачать и опробовать в реальных приложениях. Мне кажется, что пора осваивать эту технологию. Пора, друзья!
Web-приложения производят данные с колоссальной скоростью, и эта скорость возрастает с каждым годом по мере того как Web занимает все более важное место в жизни людей. Быстро расширяющейся частью нашей жизни являются и другие источники данных, например, системы мониторинга окружающей среды или службы отслеживания текущего местоположения людей. Несмотря на постоянное повышение пропускной способности Internet, пользователям и препринимателям требуется возможность наблюдения интересующих их данных со все меньшими задержками. Этому отчасти способствуют достижения в области аппаратуры компьютеров (удешевление основной и дисковой памяти, увеличение числа ядер процессоров), но этого недостаточно для удовлетворения требования повышения пропускной способности при одновоеменном снижении времени задержки.
Технологии наращивания мощности Web-приложений должны быть достаточно простыми, во-первых, поскольку должна обеспечиваться возможность их быстрого изменения и масштабного внедрения с минимальными усилиями, а во-вторых, потому что люди, создающие Web-приложения, являются специалистами широкого профиля, и они не готовы изучать сложные, трудно настаиваемые технологии, используемые системными программистами.
Выполнение запросов над потоками данных – это новая технология, обеспечивающая обработку быстро поступающих данных и производящая результаты с небольшими задержками. Эта технология появилась в сообществе исследователей баз данных, и поэтому она обладает некоторыми характеристиками, сделавшими популярными реляционные системы базы данных, но, несомненно, это не СУБД. В системах баз данных сначала данные поступают в базу данных и сохраняются на дисках, а потом уже пользователи применяют к этим сохраненным данным запросы. В систему обработки запросов над потоковыми данными запросы поступают раньше, чем данные. Данные проходят через несколько постоянно выполняемых запросов, и преобразованные данные поступают в приложения. Можно сказать, что в реляционных СУБД данные обрабатываются в состоянии покоя, а в системах обработки запросов над потоковыми данными – на лету.
В реляционных базах данных основным примитивом являются таблицы. Таблица заполняется записями, каждая из которых имеет один и тот же тип записи, задаваемый несколькими именованными строго типизированными столбцами. Внутри записей отсутствует какой-либо внутренний порядок столбцов. При выполнении запросов, обычно представляемых на языке SQL, выбираются записи из одной или нескольких таблиц, и они преобразуются с использованием небольшого набора мощных реляционных операций.
В системах обработки запросов над потоковыми данными соответствующими примитивами являются потоки. Как и у таблицы, у потока имеется некоторый тип записи, но записи не хранятся, а поступают в потоке. В потоковой системе записи естественным образом упорядочены, и у каждой записи имеется временная метка, показывающая, когда эта запись была создана. У реляционных операций, поддерживаемых в реляционных базах данных, имеются аналоги в потоковой системе, и эти аналоги достаточно похожи на реляционные операции, чтобы для формулировки потоковых запросов можно было использовать SQL.
Чтобы проиллюстрировать, как система обработки запросов над потоковыми данными может помочь решить проблемы обработки данных на лету, рассмотрим следующий пример.
Запросы к данным о посещении Web-сайтов
Предположим, что нам требуется отслеживать наиболее популярные страницы некоторого Web-сайта. При каждом обращении пользователей к Web-серверу генерируется запись в журнальном файле, содержащая данные о времени, URI данной страницы и IP-адресе обращающегося пользователя. Некоторый адаптер может непрерывно анализировать журнальный файл и образовывать поток записей. Показанный ниже запрос вычисляет число запросов в минуту к каждой странице Web-сайта. Возможные результаты приведены в табл. 1.
SELECT STREAM ROWTIME, uri, COUNT(*)
FROM PageRequests
GROUP BY FLOOR(ROWTIME TO MINUTE), uri;
Таблица 1

В этом примере, как и в других примерах данной статьи, для формулировки запроса используется язык запросов SQLstream. Этот язык является стандартным языком SQL с несколькими потоковыми расширениями [4]. Другие системы обработки запросов к потоковым данным обладают аналогичными возможностями.
Единственными расширениями SQL, используемыми в данном запросе, являются ключевое слово STREAM и системный столбец ROWTIME. Если убрать из запроса ключевое слово STREAM и преобразовать PageRequests в таблицу со столбцом ROWTIME, то полученный запрос можно было бы выполнить в традиционной СУБД, такой как Oracle или MySQL. При выполнении такого запроса анализировались бы все обращения к страницам Web-сайта, произведенные до настоящего времени. Однако если PageRequests является потоком, то ключевое слово STREAM указывает системе на необходимость подсоединиться к этому потоку и применять операцию ко всем будущим записям.
Каждую минуту этот запрос генерирует набор записей, подытоживающих трафик на каждой странице в течение этой минуты. Результирующие строки с временной меткой 10:00:00 подытоживают все обращения, произошедшие между моментами времени 10:00 и 10:01(включая 10:00 и не включая 10:01). Строки в потоке PageRequests упорядочиваются по значениям системного столбца ROWTIME, так что результирующие строки с временной меткой 10:00:00 буквально выталкиваются при поступлении первой строки с временной меткой 10:01:00 или более поздней. Система обработки запросов к потоковым данным обычно обрабатывает данные и доставляет результаты только при поступлении новых данных, так что можно сказать, что она работает "под давлением" данных. Это отличается от подхода "вытягивания" данных, применяемого в реляционных СУБД, где приложения должны постоянно опрашивать систему для получения новых результатов.
В следующем примере находятся URI, для которых число обращений больше обычного. Сначала представление PageRequestsWithCount вычисляет число обращений за последний час к каждому URI и их среднее значение за последние 24 часа. Затем запрос выбирает URI, для которых число обращений за последний час более чем в три раза превышает это усредненное число.
CREATE VIEW PageRequestsWithCount AS
SELECT STREAM ROWTIME,
uri,
COUNT(*) OVER lastHour AS hourlyRate,
COUNT(*) OVER lastDay / 24 AS hourlyRateLastDay
FROM PageRequests
WINDOW lastHour AS (
PARTITION BY uri
RANGE INTERVAL ‘1’ HOUR PRECEDING)
lastDay AS (
PARTITION BY uri
RANGE INTERVAL ‘1’ DAY PRECEDING);
SELECT STREAM *
FROM PageRequestsWithCount
WHERE rate > hourlyRateLastDay * 3;
В отличие от предыдущего запроса, в котором использовался раздел GROUP BY для агрегации многих записей в одну сводную для каждого заданного промежутка времени, в данном запросе используется оконное (windowed) агрегатное выражение (агрегатная функция НАД окном, aggregate-function OVER window) для добавления к каждой строке аналитических значений. Поскольку в каждую строку добавляются статистические данные за последние час и день, не требуется накапливать пакет записей. Такой запрос можно использовать для постоянной поддержки списка "наиболее популярных страниц" своего сайта, а в коммерческих сайтах он может применяться для определения товаров, объемы продаж которых превышают норму.
Сравнение СУБД и систем обработки запросов к потоковым данным
В СУБД и системах обработки запросов к потоковым данным поддерживается схожая семантика SQL, но при обработке данных "на лету" они ведут себя очень по-разному. Почему система обработки запросов к потоковым данным в таких ситуациях работает более эффективно? Для ответа на этот вопрос полезно взглянуть на происхождение таких систем.
Иногда для обозначения подобных систем используется термин потоковая база данных, который обманчиво наводит на мысль, что такая система сохраняет данные. Системы обработки запросов к потоковым данным происходят из исследовательского сообщества, в частности, от проектов STREAMS (Stanford) [1], Aurora (MIT/Brown/Brandeis) [2] и Telegraph [3]. Системы обработки запросов к потоковым данным основываются на реляционной модели, определяющей реляционные базы данных и, как мы увидим, этот фундамент придает им мощность, гибкость и пригодность для производственного использования.
Реляционная модель, впервые описанная Э.Ф. Коддом (E. F. Codd), является простым и единообразным способом описания структур баз данных. Модель состоит из отношений (именованных коллекций записей) и набора простых операций для комбинирования этих отношений: селекция(select), проекция (project), соединение (join), агрегирование (aggregate) и объединение (union). Реляционная модель естественным образом обеспечивает независимость данных – отделение логической структуры данных от их физического представления. Поскольку создатель запроса не знает, как физически организованы данные, важным компонентом СУБД является оптимизатор запросов, производящий выбор из многих возможных алгоритмов выполнения запроса.
SQL впервые появился на рынке в конце 1970-х. Некоторые люди считают этот язык небезупречным с теоретической точки зрения (в особенности после добавления в него расширений, относящихся к таким нереляционным понятиям, как объекты и вложенные таблицы), но, тем не менее, в нем воплощаются основные принципы реляционной модели. Язык является декларативным, что дает возможность оптимизировать запросы, так что пользователь (или система) может настроить приложение без потребности в его переписывании. Поэтому можно отложить настройку новой схемы базы данных до тех пор, пока приложение не будет в основном написано, и можно безопасным образом производить рефакторинг существующей схемы базы данных. SQL прост, надежен и неприхотлив, и многие разработчики понимают этот язык.
Потоки вносят в реляционную модель новое измерение. По-прежнему можно применять базовые операции (селекция, проекция, соединение и т.д.), но можно задать системе и такой вопрос: "Если бы некоторый запрос с соединением выполнялся секунду тому назад, и снова выполнялся бы в настоящее время, то чем бы отличались его результаты?".
Это позволяет подходить к решению проблем совсем другим образом. В качестве аналогии обсудим, как можно было бы измерить скорость автомобиля, движущегося по автостраде. Можно было бы посмотреть на часы, проезжая очередной километровый знак, еще раз посмотреть на часы, достигнув следующего километрового знака, перевести прошедшее время в доли часа и поделить единицу на полученную величину. В качестве альтернативы можно использовать спидометр, устройство, в котором стрелка двигается под действием вырабатываемого тока, сила которого пропорциональна частоте вращения колес автомобиля, пропорциональной, в свою очередь, скорости автомобиля. Метод, основанный на километровых знаках, преобразует в скорость длину пути и время, в то время как спидометр измеряет скорость непосредственно, используя некоторый набор количественных показателей, пропорциональных скорости.
Длина пройденного пути и скорость – это связанные количественные показатели; в дифференциальном исчислении скорость является производной пути по времени. Аналогично, поток является производной таблицы. Ровно так же, как спидометр обеспечивает более точное решение проблемы измерения скорости машины, система обработки запросов над потоковыми данными часто оказывается намного более эффективной, чем реляционная СУБД для приложений обработки данных, работающих с быстро поступающими данными, зависящими от времени.
Преимущества потоков
Почему система выполнения запросов над потоковыми данными оказывается более эффективной, чем реляционная СУБД, при решении проблем обработки данных "на лету"?
Прежде всего, в этих системам такие проблемы выражаются очень по-разному. База данных хранит данные, а приложения выполняют над этими данными запросы (и транзакции). В системе обработки запросов над потоковыми данными сохраняются запросы, а данные для этих запросов поступают из внешнего мира. Здесь нет никаких транзакций, потому что данные "протекают" через систему.
При работе с базой данных требуется загружать и индексировать данные, запускать запросы над всем набором данных и изымать предыдущие результаты. Система обработки запросов над потоковыми данными обрабатывает только новые данные. Она удерживает только те данные, которые ей еще нужны (например, данные за последнюю минуту), и, поскольку обычно эти данные умещаются в основной памяти, не требуются обмены с дисками.
Реляционная СУБД функционирует на основе того предположения, что все данные являются одинаково важными, но в бизнес-приложениях то, что произошло минуту назад, часто важнее того, что произошло вчера, и гораздо важнее того, что произошло год назад. По мере роста базы данных приходится раскидывать данные по разным дискам и создавать индексы, чтобы обеспечить доступ ко всем данным за константное время.
В системе обработки запросов на потоковыми данными рабочие наборы имеют меньшие размеры и могут размещаться в основной памяти. Поскольку в запросах содержатся спецификации окон, и сами запросы создаются до поступления данных, системе обработки запросов над потоковыми данными не нужно угадывать, какие данные требуется сохранять. У системы обработки запросов над потоковыми данными имеется и еще одно преимущество над реляционной СУБД: сокращенные накладные расходы на управление параллелизмом и повышенная эффективность из-за асинхронности обработки данных. Поскольку СУБД изменяет структуры данных, которые могут читать и изменять другие приложения, в ней требуются механизмы управления параллелизмом. В системе обработки запросов над потоковыми данными отсутствует конкуренция за блокировки, поскольку данные, поступающие от всех приложений, ставятся в очередь и обрабатываются, когда система становится готовой к этому.
Другими словами, система обработки запросов над потоковыми данными работает с данными асинхронно. Асинхронная обработка – это характеристика высокопроизводительных серверных приложений, от приложений обработки транзакций до приложений обработки электронной почты, равно как и индексирования страниц Web. Асинхронность позволяет системе изменять свои единицы работы – от обработки отдельных записей при низкой загрузке системы до обработки пакетов из многих записей при повышении нагрузки – для получения выигрыша в эффективности за счет, например, локальности ссылок. Можно было бы подумать, что у асинхронной системы увеличивается время ответа, поскольку она обрабатывает данные, "когда захочет", но в действительности она достигает заданной пропускной способности при гораздо меньшей нагрузке системы и поэтому обеспечивает более быстрое время ответа, чем синхронная система. Реляционная СУБД не только синхронна сама по себе, но обычно вынуждает работать в режиме отдельных записей и приложения.
Теперь должно быть ясно, что обработка "под давлением" данных более эффективна для работы с данными "на лету". Однако этого можно достичь не только на основе системы обработки запросов над потоковыми данными. Streaming SQL не делает ничего такого, что было бы невозможно сделать раньше. Например, можно было бы решить многие проблемы с использованием некоторой шины сообщений, представляемых в формате XML, и некоторого процедурного языка для взятия сообщений из шины, их преобразования и помещения обратно в шину. Однако при этом пришлось столкнуться с проблемами эффективности (разбор XML обходится не дешево), масштабируемости (как расщепить проблему на подроблемы, которые можно было бы решать в отдельных потоках управления или машинах?), алгоритмистики (как эффективно объединить два потока, связать два потока по общему ключу или агрегировать поток?) и конфигурирования (как проинформировать все компоненты системы при изменении какого-либо правила?). В большинстве современных приложений используются реляционные СУБД, чтобы избежать работы с файлами данных напрямую, и основания для применения систем обработки запросов к потоковым данным являются очень схожими.
Другие приложения систем обработки запросов к потоковым данным
Подобно тому, что технология реляционных баз данных является горизонтальной, используемой для самых разных целей, от обслуживания Web-страниц до обработки транзакций и организации хранилищ данных, потоковые SQL-системы могут быть применены для решения различных проблем.
Одна из областей приложений называется CEP (complex event processing – обработка сложных событий). Запрос к системе CEP направлен на поиск последовательностей событий в одном или нескольких потоках, сопоставление их с некоторым шаблоном и создание "сложного события", представляющего бизнес-интерес. Системы CEP применяются, в частности, в приложениях обнаружения электронного мошенничества и электронной торговли.
В индустрии под термином CEP понимаются системы обработки запросов к потоковым данным в целом. К сожалению, это приводит к религиозным войнам между поставщиками систем, опирающихся на SQL, и систем, в которых SQL не используется. Кроме того, возникает излишняя фокусировка на финансовых приложениях, что приводит к пренебрежению другими областями приложений.
Упоминавшиеся выше запросы к данным об использовании Web-страниц являются простым примером приложения мониторинга. Подобные приложения отслеживают изменения в транзакциях, представляющих работающий бизнес, и предупреждают обслуживающий персонал, если не все дела идут хорошо. В отличие от CEP-запросов, которые сопоставляют с заданными шаблонами отдельные записи, запросы мониторинга находят важную информацию путем агрегирования большого числа записей и определения тенденций. Приложения мониторинга также могут заполнять в реальном времени информационные панели (dashboard), являющиеся бизнес-эквивалентом спидометра, термометра и манометра.
У потоковых запросов имеется естественная синергия с хранилищами данных, поскольку в обоих случаях используется SQL. В хранилище данных сохраняются огромные объемы исторических данных, требуемых для анализа бизнеса через "зеркало заднего вида", в то время как система обработки запросов к потоковым данным пополняет хранилище данными и обеспечивает "передний обзор" информации, чтобы "рулить компанией".
Cистема обработки запросов к потоковым данным выполняет те же функции, что и средство ETL (extract, transform, load – извлечение, преобразование, загрузка), но она функционирует непрерывно. Традиционный процесс ETL представляет собой последовательность шагов, вызываемых в виде пакетного задания. Время цикла процесса ETL ограничивает актуальность данных в хранилище данных; трудно добиться, чтобы это время было меньше нескольких минут. Например, большая часть шагов, требующих переработки большого объема данных, выполняется на основе запросов к хранилищу данных: поиск существующих значений в таблице измерений (например, клиентов, совершивших предыдущую покупку) и заполнение сводных таблиц. Система обработки запросов к потоковым данным может кэшировать информацию, требуемую для выполнения этих шагов, снимая излишнюю нагрузку с хранилища данных, в то время как процесс ETL является слишком кратковременным, чтобы в нем было выгодно производить кэширование.
На рис. 1 показана арихитектура системы бизнес-аналитики реального времени. Кроме непрерывного выполнения ETL, система обработки запросов к потоковым данным заполняет информационную панель бизнес-показателями, генерирует предупреждения, если значения этих показателей выходят за приемлемые границы и в упреждающем режиме поддерживает кэш OLAP-сервера (online analytical processing – оперативная аналитическая обработка), основанного на хранилище данных.
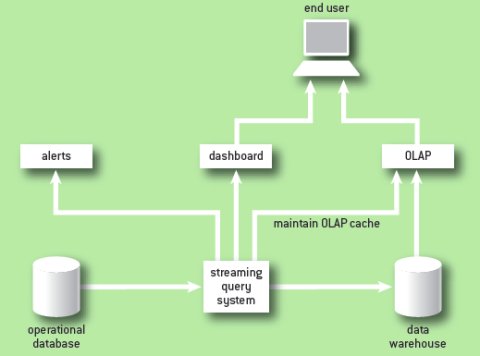
Рис. 1. Непрерывный процесс ETL с использованием системы обработки запросов к потоковым данным
Сегодня большая часть "данных на лету" передается с использованием промежуточного программного обеспечения, ориентированного на обмен сообщениями. Подобно промежуточному программному обеспечению, системы обработки запросов к потоковым данным могут доставлять сообщения надежно, с высокой пропускной способностью и малыми задержками. Кроме того, они могут применять операции SQL для маршрутизации, комбинирования и преобразования сообщений "на лету". По мере достижения зрелости эти системы могут начать играть роль промежуточного программного обеспечения и стирать границы между механизмами передачи сообщений, непрерывными процессами ETL и технологиями баз данных за счет повсеместного применения ETL.
Заключение
Системы обработки запросов к потоковым данным основываются на той же технологии, что и реляционные СУБД, но предназначены для обработки данных "на лету". Системы обработки запросов к потоковым данным могут способствовать намного более эффективному решению некоторых распространенных проблем, чем СУБД, поскольку
- они в большей степени соответствуют связанной со временем природе этих проблем,
- они сохраняют только рабочий набор данных, требуемых для решения проблемы
- и они обрабатывают данные асинхронно и непрерывно.
Поскольку и системы обработки запросов к потоковым данным, и реляционные СУБД используют язык SQL, они могут применяться совместно для решения проблем мониторинга и бизнес-анализа данных в реальном времени. SQL делает их доступными для большого числа людей, обладающих опытом использования этого языка.
Ровно так же, как СУБД могут применяться для решения большого числа проблем, от обработки транзакций до организации хранилищ данных, системы обработки запросов к потоковым данным могут поддерживать приложения, связанные с корпоративной передачей сообщений, обработкой сложных событий, непрерывной интеграцией данных, а также в новых прикладных областях, которые продолжают обнаруживаться.
Литература
1. Arasu, A., Babu, S., Widom, J. 2003. The CQL Continuous Query Language: Semantic foundations and query execution. Technical Report, Stanford
2. Aurora project
3. Chandrasekaran, S., et al. 2003. TelegraphCQ: Continuous dataflow processing for an uncertain world. In Proceedings of CIDR (Conference on Innovative Data Systems Research)
4. SQLstream Inc.



 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС