Статья представляет собой расширенный текст доклада, подготовленного для конференции "Корпоративные базы данных-2006" (11-12 апреля 2006 г., Москва).
Содержание
1. Введение
Три года тому назад, 4-6 мая 2003 г. в г. Лоуэлл, шт. Массачусетс (США) состоялось собрание авторитетных представителей исследовательского сообщества баз данных. Как и на предыдущих собраниях, из которых в России наиболее известны собрания в Лагуна-Бич (1989 г.) [
1] и Асиломаре (1996 г.) [
2] (общий обзор материалов этих собраний можно найти в [
3]), в Лоуэлле обсуждались текущее состояние дел в области управления данными и проблемы, требующие решения. Наиболее подробная информация по поводу Лоуэллского собрания была опубликована в 2003 г. Джимом Греем на сайте компании Microsoft [
4], и в том же 2003 г. сообщение о Лоуэллском собрании было представлено на Международной конференции по управлению данными ACM SIGMOD [
5]. Год назад я написал статью, в которой обозревался отчет, подготовленный участниками Лоуэллского собрания (Лоуэллский отчет), а также приводились некоторые собственные соображения относительно возможностей развития технологии баз данных в России [
6]. Наконец, в середине 2005 г. наконец-то появилась официальная публикация полного текста Лоуэллского отчета [
7].
На собраниях, подобных Лоуэллскому, собираются представители различных школ и направлений в области управления данными. Поскольку отчеты этих собраний строятся на основе мнения большинства участников, они неизбежно носят очень компромиссный характер, определяя общие проблемы и задачи, но не концентрируясь на конкретных технологических решениях (хотя, как показано в [6], часто формулировки проблем связаны с уже имеющимися исследовательскими проектами). Затем уже более узкие группы авторов предлагают подходы к решению этих проблем и задач, основанные на более конкретных идеях и методах.
В этом отношении показательным является отчет Лагуна-Бич [1], в котором, в частности, на абстрактном уровне говорилось о необходимости внедрения в СУБД встроенных средств расширения возможностей систем для удовлетворения потребностей новых приложений. Среди авторов этого отчета, среди прочих, числятся Дэвид Девитт и Дэвид Майер, с одной стороны, и Филипп Бернштейн, Джим Грей, Брюс Линдсей, Лоуренс Роув и Майкл Стоунбрейкер, с другой стороны. В том же 1989 г. группа исследователей, в которую входили Девитт и Майер, опубликовала "Манифест систем объектно-ориентированных баз данных" [8], а годом позже другой группой, в которой активно участвовали Берштейн, Грей, Роув и Стоунбрейкер, был выпущен "Манифест систем баз данных третьего поколения" [9]. (Подробный обзор и сравнительный анализ этих манифестов, а также "ортогонального" им Третьего манифеста Кристофера Дейта и Хью Дарвена [10] можно найти в [11].) В этих, уже практически бескомпромиссных документах предлагались практические шаги для решения общих проблем на основе сравнительно конкретных технологий. Следует заметить, что первые два манифеста оказали существенное воздействие на современный облик технологии баз данных, а третий манифест, с моей точки, зрения весьма способствует пониманию достоинств и недостатков этой технологии.
Асиломарский отчет не привел к появлению подобных документов, хотя под его влиянием был выполнен ряд известных исследовательских работ, облегчающих доступ к данным в Web. До конца 2005 г. не были заметны какие-либо попытки обобщенной конкретизации* подходов и к решению проблем, перечисленных в Лоуэллском отчете. Однако в декабрьском номере журнала ACM SIGMOD Record за 2005 г. появились две статьи, обладающими, на мой взгляд, некоторыми свойствами манифестов. В [12] Майкл Стоунбрейкер и Стенли Здоник формируют технологический облик типичной системы управления потоковыми данными. В [13] Майкл Франклин и Дэвид Майер предлагают концепцию пространства данных как обобщение систем баз данных, систем интеграции данных, файловых систем и т.д. Формулируются конкретные требования и задачи, предлагаются конкретные пути к решению этих задач.
Обе статьи явно или неявно опирается на идеи Лоуэллского отчета. В каждой из них предлагается некоторая стратегическая линия развития технологии управления данными. Эти предложения носят не столь глобальный характер, как предложения трех классических манифестов конца прошлого века. Тем не менее, обе статьи представляются мне как предшественники будущих манифестов, которые будут определять развитие технологии управления данными.
Для удобства чтения в следующем разделе я приведу краткую классификацию основных положений Лоуэллского отчета, а в последующих разделах проанализирую в контексте этой классификации каждую из двух статей.
2. Структуризация положений Лоуэллского отчета
Одним из важных отличий Лоуэллского отчета от предшествовавшего ему Асиломарского отчета является то, что участники собрания в Лоуэлле сочли нецелесообразным выдвижение очередной "сверхзадачи" (Grand Challenge) в области управления данными. В Асиломаре в качестве такой сверхзадачи ставилось "превращение Web в следующем десятилетии в более полезную информационную службу" [
3]. На самом деле, можно спорить относительно того, произошли ли за прошедшие после Асиломарского собрания реальные подвижки по направлению к решению этой сверхзадачи. Можно спорить даже по поводу самой постановки такой сверхзадачи. Действительно, что означает словосочетание "более полезный"? Полезный для кого? Можно ли сделать Всемирную Паутину одинаково полезной для всех отдельных людей, разнообразных коммерческих, государственных и научных организаций, для разных областей науки?
По здравому мнению участников собрания в Лоуэлле, область управления данными должна способствовать решению "сверхзадач", выдвигаемых в других областях человеческой деятельности, которые ориентируются на достижение результатов, непосредственно влияющих на жизнь людей. Сама же область управления данными должна способствовать развитию новой инфраструктуры управления данными, облегчающих решение проблем в различных прикладных областях. В Лоуэллском отчете перечисляется ряд компонентов этой инфраструктуры, для создания которых требуются дополнительные исследования и опытные разработки, но порядок их перечисления достаточно произволен, а в обоснованиях их потребности и предложениях возможных подходов к реализации имеется ряд повторов. Попытаемся ввести некоторую более строгую структуризацию и классификацию предложений Лоуэллского отчета.
2.1 Различные аспекты интеграции данных
Так или иначе к тематике оперативной интеграции огромного числа распределенных и разнородных источников данных относятся все положения Лоуэллского отчета. Но многие из них применимы не только в этом контексте. В данном подразделе мы перечислим и кратко прокомментируем предложения Лоуэллского отчета, имеющие непосредственное отношение к интеграции данных.
2.1.1 Интеграция текста, данных, кода и потоков
"Нужно переосмыслить базовую архитектуру СУБД с целью поддержки структурированных данных; текстовых, пространственных, темпоральных и мультимедийных данных; процедурных данных, т.е. типов данных и инкапсулирующих их методов; триггеров; потоков и очередей данных как равноправных компонентов первого сорта внутри архитектуры СУБД (как на уровне интерфейсов, так и на уровне реализации)." Это одна из наиболее глобальных задач, ставящихся в Лоуэллском отчете. Идея состоит в том, что в сегодняшних СУБД (как SQL-ориентированных, так и рассчитанных изначально на поддержку XML) поддержка данных иной природы, нежели та, на которую они исходно ориентированы, неизбежно носит вторичный характер. Это делает данные неравноправными как в отношении интерфейсов доступа, так и в эффективности средств управления. Нужно устранить это неравноправие. До конца 2005 года эта идея казалось мне крайне утопической, однако подход, предлагаемый в [
13], как кажется, может послужить основой в некоторой ее реализации (за счет, в частности, пересмотра базовой концепции интеграции данных).
2.1.2 Слияние информации
"Типичным подходом к интеграции информации в масштабах предприятия является построение хранилищ (DataWarehouse) и витрин (data mart) данных на основе извлечения операционных данных, их трансформации к единой схеме и загрузки данных в хранилище (процедура ETL - extraction, transformation, loading). Этот подход пригоден для использования на предприятии с несколькими десятками операционных баз данных, находящихся под единым контролем. В Internet парадигма ETL не приемлема." Очевидно, что в этом пункте речь идет о возможности использования оперативно интегрируемых многочисленных и многообразных источников данных в целях оперативного анализа данных. Авторы отмечают, что "в связи с этим существует множество нерешенных проблем: семантическая неоднородность; неполнота и неточность данных; ограниченность доступа к конфиденциальным данным и т.д.". Безусловно, это справедливо, но, как мне кажется, существуют еще два более общих вопроса:
- При каком качестве интегрируемых данных можно обеспечить удовлетворительные результаты анализа данных?
- Будет ли этот подход воспринят в сообществе аналитиков данных? По крайней мере, основоположник хранилищ данных Билл Иннмон крайне скептически ответил на этот вопрос, заданный ему мною.
2.1.3 Сенсорные данные и сенсорные сети
"… при запросе данных у сенсорной сети часто более выгодным является полное распределение вычислений по отдельным узлам: сеть становится своего рода машиной баз данных. При вычислении запроса необходимо уметь изменять план запроса при изменении сети по причине выхода из строя сенсора или его отключения от сети." В связи с возрастающим распространением беспроводных сенсорных сетей необходима эффективная поддержка выполнения запросов к данным, вырабатываемым сенсорами. Одна из пионерских работ TinyDB в этом направлении была начата в университете Беркли [
14] и продолжается теперь в
лаборатории Intel в Беркли). В этом же университете под руководством Майкла Франклина сейчас выполняется интересный проект
Hi-Fi). С моей точки зрения, при таком подходе к управлению сенсорными данными это направление плотно примыкает к тематике интеграции данных, поскольку, во-первых, сенсорная сеть представляется как беспроводная распределенная "база данных", а во-вторых, источники сенсорных данных становятся полноправными членами более масштабных систем интеграции данных.
2.1.4 Мультимедийные запросы
"Очевидно, что объем мультимедийных данных (изображения, аудио, видео и т.д.) значительно возрастает. Проблемой сообщества баз данных является создание простых способов анализа, обобщения, поиска и обозрения электронных подборок мультимедийной информации, относящейся к некоторому человеку." В Лоуэллском отчете этот пункт подан без дополнительных комментариев, но мне кажется, что это частный аспект интеграции данных. Для выполнения требуемых действий с мультимедийными данными требуется, прежде всего, унифицированное представление метаданных на этими данными.
2.2 Новые черты обработки запросов
Некоторые положения Лоуэллского отчета относятся к обработке запросов вообще, независимо от того, направляются ли они к централизованной базе данных, или же к системе интеграции данных.
2.2.1 Использование неточных данных
"За пределами мира бизнеса все данные, подлежащие обработке, являются неполными и неточными. … Для успешного использования в подобных областях СУБД должны обеспечивать встроенную поддержку неточных данных. Обработка запросов должна базироваться на вероятностной, недетерминированной модели; процессор запросов должен накапливать факты, чтобы обеспечивать все лучшие и лучшие ответы на запросы пользователей. У пользователей должна иметься возможность задания неточных запросов, и процессор запросов должен относиться к этому как к дополнительному источнику неполноты и неточности." Здесь следует отметить сочетание двух возможностей: точные запросы над неточными данными и неточные запросы над точными данными. Понятно, что возможны разнообразные промежуточные варианты в зависимости от уровня точности данных и запросов. В последние годы достаточно интенсивно исследуется частный случай этой проблемы, так называемые
top-K-запросы (см. например, [
15]), когда системе подается некоторый точный запрос к точным данным, а она стремится обеспечить
K ответов, максимально близких к точному ответу. Конечно, в общей постановке проблема более интересна и полезна, но и менее понятна.
2.2.2 Персонализация
"… ответы на запросы должны зависеть от профиля пользователя, от имени которого поступают запросы. Ответ на запрос эксперта в данной предметной области должен отличаться от ответа на запрос новичка. Релевантность ответа тоже должна зависеть от пользователя и от контекста. Для подобной персонализации требуется среда для накопления и использования соответствующих метаданных." В некотором смысле, этот пункт близок к предыдущему. В ответ на запрос "новичка" должны выдаваться не обязательно абсолютно точные данные, а те, которые, по мнению системы, в наибольшей степени соответствуют его профилю.
2.2.3 Конфиденциальность
"Сообщество баз данных может заняться системами безопасности, включающими компонент, который имеет дело с ожидаемым использованием данных. Решения о правомерности доступа должны основываться не только на том, кто запрашивает данные, но и на том, что он собирается с ними делать." Хотя формально в этом пункте речь идет об обеспечении безопасности данных, фактически в нем развивается тема персонализации доступа к данным. Решение о правомерности доступа (а может быть, и о виде ответа на запрос) должно решаться в зависимости не только от профиля пользователя, но и от его текущей роли в сценарии использования запрашиваемых данных.
2.2.4 Системы, заслуживающие доверия
"Очень важно обеспечивать корректность результатов запросов и вычислений над большими объемами данных, в особенности во встроенных, например, медицинских приложениях. Для подтверждения корректности может оказаться полезной технология логического вывода, например, методы доказательства теорем или верификации моделей." Это другая сторона той же проблемы. При том, что система может решать, какую точность ответов на запросы можно и нужно предоставлять разным категориям пользователей и приложений, необходимо научиться доказывать, что соответствующее качество данных является достаточным в каждом конкретном случае. И здесь мне видится близость с проблемой, отмеченной в п.
2.1.2, о качестве интегрированных данных, достаточном для целей оперативного анализа.
2.3 Совершенствование технологии
В этот подраздел я объединил предложения Лоуэллского отчета, относящиеся к совершенствованию технических средств СУБД. Эти предложения затрагивают как внутренние, так и интерфейсные компоненты систем. В некоторых направлениях ведется активная работа, в других пока незаметны существенные продвижения.
2.3.1 Самоадаптация
"Для многих новых приложений требуется необслуживаемое функционирование СУБД. СУБД должна сама распознавать внутренние неисправности и неисправности коммуникационных компонентов, находить поврежденные данные, обнаруживать сбои приложений и что-то делать по этому поводу." Многие годы о возможности использования своих систем без администрирования заявляли компании-производители средств управления данными "второго эшелона", позиционирующие свои продукты на рынке встроенных систем. Как кажется, эти заявления носили, главным образом, маркетинговый характер. Теперь проблема самоадаптации стала действительно очень актуальной. Попытками решения отдельных аспектов этой проблемы заняты все ведущие компании, производящие СУБД.
2.3.2 Оптимизация запросов
"Нужно продолжать работать в областях оптимизации средств интеграции информации, языков запросов полуструктурированных данных, таких как XQuery, процессоров потоков, сенсорных сетей и т.д." "Требуются исследования "межзапросной" оптимизации над большим числом традиционных, чисто реляционных запросов." Здесь трудно добавить какие-либо комментарии. Проблема оптимизации запросов будет существовать до тех пор, пока не перестанут разрабатываться и использоваться системы управления данными (т.е. вечно и бесконечно). Заметим только, что "межзапросная" оптимизация, по сути, очень близка к "самоадаптации" системы, поскольку при выполнении такой оптимизации система изменяет структуру базы данных, автоматически выполняя административные функции.
2.3.3 Data Mining
"Проблемой data mining в области баз данных является разработка алгоритмов и структур данных для просеивания базы данных в поисках "жемчужин". Такая обработка должна вестись в фоновом режиме с потреблением остаточных системных ресурсов. Другой важной проблемой является интеграция data mining с подсистемой поддержки запросов, оптимизацией и другими средствами базы данных, такими как триггеры." Первая часть этого положения является очень интересной и заманчивой. Однако, хотя в прошлом появлялись работы, посвященные интеграции средств управления базами данных и data miming (см. например, [
16]), мне пока не встречались статьи, посвященные методам "фонового" извлечения знаний. Что же касается второй части положения, то методы data mining активно используются в подходе Сураджита Чаудхари к "межзапросной" оптимизации запросов [
17].
2.3.4 Новые пользовательские интерфейсы
"…остается неясным, как наилучшим образом визуализировать информацию, поступающую из СУБД. Отличные системы визуализации информации - QBE и VisiCalc - были предложены еще в 80-е гг. прошлого века. За последние 15 лет не появилось ничего принципиально нового. Крайне необходимы свежие идеи." "Тридцать лет исследований в области языков запросов сводятся к тому, что "мы двигаемся от SQL к XQuery". В лучшем случае мы переходим от одного декларативного языка к другому, обладающему примерно тем же уровнем выразительности. Конечные пользователи не знают SQL, это язык профессиональных программистов." "Возможно, наиболее интересные возможности связаны с исследованиями, ассоциируемыми с термином "semantic Web"." "Работа над онтологиями может позволить пользователям баз данных задавать запросы в собственной терминологии с использованием естественного языка. Нужно учитывать эти возможности при разработке будущих СУБД." Лично у меня сложилось скептическое отношение к направлению использования естественных языков для запросов к базам данным. Многие исследователи занимаются этим уже много лет. Появлялись даже некоторые коммерческие продукты (например,
English Query компании Microsoft). Но особых достижений не видно. Хотелось бы получить какую-либо пользу для технологии баз данных от направления Semantic Web. Однако, как мне кажется, пока сообщество Semantic Web всячески дистанцируется от сообщества баз данных, и реальные точки соприкосновения интересов найти трудно.
2.4 Столетнее хранение
Один пункт Лоуэллского отчета не вписывается в мою классификацию. "...человечество нуждается в средствах хранения, поддерживающих неограниченный во времени доступ к данным в полезной форме. Эти средства должны, насколько это возможно, автоматизировать процесс миграции данных из одного формата в другой и/или поддерживать аппаратно-программные механизмы, требующиеся для доступа к данным. Вместе с хранимыми документами должны присутствовать описывающие их метаданные." Этот пункт, безусловно, очень важен. Каждый из нас неоднократно сталкивался с безвозвратной утратой данных по причине смены технологии хранения. Но, по моему мнению, решение этой проблемы выходит за пределы возможностей области управления данными (хотя ее невозможно решить без поддержки со стороны сообщества баз данных).
3. Управление потоковыми данными
Майкл Стоунбрейкер с конца 1990-х гг. является приглашенным профессором Массачусетского технологического института (MIT). В начале 2000-х гг. в качестве представителя MIT совместно с исследовательскими группами из Brandeis University и Brown University (на протяжении многих лет профессором этого университета является Стенли Здоник, а Угур Гетинтемел - доцент этого университета) он основал проект
Aurora), посвященный исследованиям методов управления потоковыми данными и разработке действующего прототипа. При этом в MIT выполнялся отдельный проект
Medusa), в котором исследовались проблемы распределенной обработки потоковых данных. В настоящее время на основе результатов проектов Aurora и Medusa выполняется новый совместный проект
Borealis.
Как это вообще свойственно Стоунбрейкеру (вспомним основанные им компании Ingres Corporation (1982 г., на основе университетского проекта Ingres) и Illustra (1992 г, на основе университетского проекта Postgres)), в 2003 г. он основал компанию StreamBase Systems для коммерциализации технологии, разработанной в проектах Aurora и Medusa. В настоящее время я не знаю других компаний, которые бы полностью специализировались на средствах управления потоками данных.
Хотя в исследовательском сообществе известно несколько успешно реализованных проектов в области управления потоковыми данными (см., например, [18]), Стоунбрейкер и Здоник являются наиболее авторитетными представителями этой части сообщества баз данных, наиболее активными и последовательными. Поэтому я имею основания считать их публикацию [12] "предманифестом" систем обработки потоковых данных. (В действительности, на манифест систем баз данных третьего поколения [9] также оказала сильнейшее влияние система Postgres Майкла Стоунбрейкера.)
3.1 Восемь требований Стоунбрейкера и Здоника
Архитектура и методы реализации системы управления потоковыми данными представляются авторами на основе восьми требований, каждое из которых подробно разъясняется. Затем обосновывается, почему удовлетворения этих естественных для потоковой обработки требований невозможно добиться путем применения более традиционных подходов. В целях дальнейшего обсуждения приведем эти требования.
- В системе потоковой обработки реального времени сообщения должны обрабатываться "в потоке", без потребности их сохранения до выполнения какой-либо операции или группы операций. В идеале в системе должна использоваться активная (т.е. не требующая опросов) модель обработки.
Система должна быть в состоянии выполнять обработку сообщений, не прибегая к дорогостоящим операциям с внешней памятью. Операции с внешней памятью существенно увеличивают задержки процесса (например, для фиксации записи в базе данных требуется запись на диск записи журнала). Существует дополнительная проблема задержек в пассивных системах, которые до начала обработки ждут, пока приложение скажет им, что нужно делать. Для пассивных систем требуется, чтобы приложения непрерывно опрашивали интересующие их условия.
- Должен поддерживаться высокоуровневый язык "StreamSQL" со встроенными ориентированными на потоки примитивами и операциями.
При наличии миллионов действующих серверов реляционных баз данных, поддерживающих SQL, имеет смысл взять на вооружение знакомые модель запросов и операции языка SQL и просто расширить их для выполнения запросов над непрерывными потоками данных. StreamSQL должен расширять семантику стандартного SQL путем добавления к нему мощных оконных конструкций и потоковых операций. Требуются новые, ориентированные на потоки операции, не представленные в стандартном SQL. Набор операций должен быть расширяемым, чтобы разработчики могли легко получить от системы новые функции.
- Должны иметься встроенные механизмы, обеспечивающие устойчивость к "дефектам" потоков, включая отсутствие и нарушение порядка данных, что обычно присутствует в реальных потоках данных.
В системах реального времени, в которых данные никогда не сохраняются, инфраструктура должна обеспечить управление данными, которые запаздывают или задерживаются, отсутствуют или поступают не в ожидаемом порядке. Любому вычислению, которое может блокироваться, должно быть разрешено устанавливать контрольный интервал времени, после истечения которого вычисление будет возобновлено над частично доступными данными. Для работы с данными, нарушающими порядок, должен обеспечиваться механизм, позволяющий окнам оставаться открытыми в течение дополнительного периода времени.
- Процессор обработки потоков должен гарантировать предсказуемые и повторяемые результаты.
Недостаточно просто упорядочивать сообщения до их ввода в систему - корректность можно гарантировать только в том случае, когда во всем обрабатывающем конвейере системы поддерживается упорядоченная по времени, детерминированная обработка. Возможность производить предсказуемые результаты также важна и с точки зрения отказоустойчивости и восстановления, поскольку воспроизведение и повторная обработка того же входного потока должны приводить к тем же результатам независимо от времени выполнения.
- У системы потоковой обработки должна иметься возможность эффективного хранения, доступа и модификации информации о состоянии, а также ее комбинирования с реальными потоковыми данными. Для бесшовной интеграции в системе должен использоваться единообразный язык для работы с обеими разновидностями данных.
Для многих приложений потоковой обработки распространенной задачей является сравнение "настоящего" с "прошлым". Поэтому система потоковой обработки должна также обеспечивать тщательное управление сохраненным состоянием. Для приложений потоковой обработки данных, которые должны гарантировать небольшую задержку, использование подключения к клиент-серверной базе данных будет увеличивать задержку и поэтому такой способ непригоден для эффективного долговременного хранения данных и доступа к ним. Следовательно, состояние должно сохраняться в адресном пространстве той же операционной системы, в среде которой работает приложение, с использованием встроенной системы баз данных. Областью видимости команды StreamSQL должен являться либо реальный поток, либо таблица, сохраняемая во встроенной системе баз данных.
- Приложения должны быть работоспособными и доступными, а данные всегда целостными независимо от наличия сбоев.
Для сохранения целостности критически важной информации и во избежание нарушений обработки в реальном времени система потоковой обработки должна основываться на решении с высоким уровнем доступности. Если происходит сбой, приложение должно переключиться на резервную аппаратуру и продолжить выполнение. Перезапуск операционной системы и восстановление приложения по журналу порождают слишком большие накладные расходы и поэтому неприемлемы для обработки в реальном времени.
- Система потоковой обработки должна быть в состоянии распределять свою обработку по нескольким процессорам и машинам для достижения инкрементной масштабируемости. В идеале это распределение должно быть автоматическим и прозрачным.
Должна иметься возможность расщепить приложение для выполнения на нескольких машинах для его масштабирования без потребности переписывания низкоуровневого кода его разработчиком. Для использования преимуществ современных многопотоковых архитектур процессоров в системах потоковой обработки должно также поддерживаться многопотоковое функционирование. Должна обеспечиваться автоматическая и прозрачная балансировка нагрузки результирующего приложения между доступными машинами, чтобы это приложение не тормозилось какой-либо одной перегруженной машиной.
- У системы потоковой обработки должен иметься высоко оптимизированный процессор поддержки выполнения с минимальными накладными расходами, обеспечивающий выработку результатов в реальном времени приложениями с большими объемами данных.
Важной проблемой является минимизация числа "пересечений границ" путем интеграции всех важнейших функций (например, обработки и сохранения) в одном системном процессе. Однако только этого недостаточно; все компоненты системы должны разрабатываться с учетом требования высокой производительности.
3.2 Связь восьми требований с Лоуэллским отчетом
Многие требования в [
12] обусловлены спецификой потоковой обработки данных в реальном времени, но часть из них, по моему мнению, непосредственно связана с положениями Лоуэллского отчета.
Например, требование iii (устойчивость к "дефектам" потоков) находится в явном родстве с п. 2.2.1 (в моей нумерации) Лоуэллского отчета (использование неточных данных) в контексте потоковых данных. В данном случае требуется, чтобы система выдавала предельно точные ответы на запросы при различных нарушениях потоков данных.
Требование v (бесшовная интеграция потоковых и хранимых данных) соответствует положению 2.1.1 (интеграция текста, данных, кода и потоков). Причем в данном случае соответствие является предельно точным: в модели системы потоковой обработки Стоунбрейкера и Здоника и потоки, и хранимые данные являются сущностями "первого класса"; ни одна из них не реализуется на основе другой.
Наконец, требование viii (высоко оптимизированный процессор) является уточнением п. 2.3.2 (оптимизация запросов). В случае потоковых систем, поддерживающих ответы на запросы в реальном времени, оптимизация запросов является одновременно критическим фактором приемлемости системы и новой, интересной и сложной задачей.
4. Пространства данных
Начну этот раздел с представления главных действующих лиц - авторов [
13]. Наверное, наиболее известным среди них в России является Дэвид Майер, благодаря изданию на русском языке его известнейшей книги [
19], являющейся, по сути, единственной монографией, которая охватывает все аспекты теории реляционных баз данных. Майер был также редактором (совместно с героем предыдущего раздела статьи Стенли Здоником) единственной хрестоматии по объектно-ориентированным базам данных [
20]. В настоящее время Дэвид Майер является профессором Portland State University (до этого он много лет работал в Oregon Health and Science University).
Майкл Франклин получил степень PhD в Висконсинском университете в 1993 г., с 1999 г. работает в университете Беркли, с 2004 г. - полный профессор. Один из наиболее активных исследователей среднего поколения в области баз данных. Алон Хэлеви получил степень PhD в Стэнфордском университете в 1993 г. С 1998 г. работает в University of Washington. В настоящее время профессор этого университета.
Похоже, что основным подвижником идеи пространств данных являлся именно Хэлеви. 2 сентября 2005 г. он вместе с Майклом Франклином выступил на семинаре группы баз данных университета Беркли. Интересно, что в опубликованной в Internet презентации этого доклада [21] соавторами числятся Дэвид Майер и Дженнифер Видем (профессор Стэндфордского университета, автор многочисленных статей и книг, в том числе, соавтор (вместе с Джеффри Ульманом и Гектором Гарсиа-Молина) популярной книги [22]). В октябре 2005 г. появилась самостоятельная публикация Хэлеви [23] и, наконец, в декабре вышла статья [13].
К настоящему времени мне удалось обнаружить два ведущихся проекта, ориентированных на поддержку пространств индивидуальных данных. Первый из них (проект SEMEX - SEMantic EXplorer, выполняется в University of Washington под руководством Хэлеви. Второй, называемый iMeMex, выполняется с 1 апреля 2006 г. под руководством Йенса-Петера Диттриха в ETH Zurich. Может показаться интересной статья [24], написанная Дитрихом совместно с Дональдом Коссманом специально к началу проекта.
Таким образом, вокруг идей, выказанных в [13] сплачивается значительная часть сообщества баз данных, что также дает возможность рассматривать этот документ как предвестник манифеста.
4.1 Свойства и возможная архитектура систем пространств данных
Существующие решения управления данными могут быть представлены в виде точек двумерного пространства (рис. 1). Измерение "административной близости" показывает, насколько
близки различные источники данных с точки зрения административного управления. Чем ближе административное управление группы источников данных, тем сильнее гарантии (например, согласованность, стабильность), которые могут быть предоставлены системой управления данными. Измерение "семантической интеграции" является мерой того, насколько близко могут быть сопоставлены схемы различных источников данных, т.е. насколько хорошо соответствуют типы, имена, единицы измерения, смысл данных в источниках. Это измерение показывает уровень, на котором могут быть обеспечены семантически развитые средства запрашивания данных и манипулирования данными над группой источников данных: более высокий уровень интеграции обеспечивает более развитые функциональные возможности.
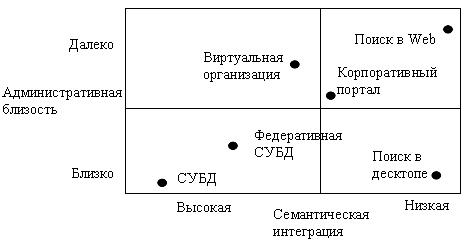
Рис. 1. Пространство решений управления данными
4.1.1 Требуемые свойства платформ поддержки пространств данных
Традиционные СУБД представляют только одну точку (хотя и очень важную) в пространстве решений управления данными. СУБД требуют, чтобы все данные находились под единым административным управлением и соответствовали единой схеме. В ответ на удовлетворение этих ограничений СУБД могут обеспечить развитые средства манипулирования данными и обработки запросов с понятной и строгой семантикой, а также строгие транзакционные гарантии обновлений, параллельного доступа и долговременного хранения (так называемые свойства "ACID"). Важной точкой пространства решений являются "системы интеграции данных". На самом деле, системы интеграции данных и обмена данными традиционно предназначаются для поддержки многих других осмысленных служб в системах пространств данных. Особенность состоит в том, что в системах интеграции данных требуется
семантическая интеграция до того, как могут быть обеспечены какие-либо прочие услуги. Поэтому, хотя и отсутствует единая схема, которой соответствуют все данные, система должна знать точные взаимосвязи между элементами, используемыми в каждой схеме. В результате для создания системы интеграции данных требуется существенная предварительная работа.
Пространства данных не являются подходом к интеграции данных; скорее, это подход сосуществования данных. Цель поддержки пространства данных состоит в обеспечении базового набора функций надо всеми источниками данных, а не в их интеграции. Например, DSSP (DataSpace Support Platform) может обеспечить надо всеми своими источниками данных поиск по ключевым словам, аналогично тому, что обеспечивают существующие поисковые системы в десктопах. При потребности в более сложных операциях, таких как запросы в реляционном стиле, анализ данных (data mining) или мониторинг каких-либо источников, можно приложить дополнительные усилия к более тесной интеграции этих источников в инкрементной манере.
Аналогичная гибкость имеется и в измерении административной близости. Если желательно наличие административной автономии, то DSSP не сможет гарантировать согласованность, устойчивость результатов операций обновления и т.д. Для удовлетворения потребности в более строгих гарантиях нужны дополнительные усилия для достижения соглашений между владельцами источников данных и открытия некоторых интерфейсов (например, для протоколов фиксации транзакций).
На основе этих рассуждений авторы делают вывод, что отличительными свойствами систем пространств данных является следующее:
- DSSP должны работать с данными и приложениями в разнообразных форматах, доступных от многих систем через различные интерфейсы. От DSSP требуется поддержка всех данных пространства данных, без каких-либо исключений.
- Хотя DSSP обеспечивает средства интегрированного поиска, запрашивания, обновления и администрирования пространств данных; те же самые данные часто могут быть доступны для чтения и обновления через собственный интерфейс системы, непосредственно управляющей данными. Поэтому, в отличие от СУБД, DSSP не имеет полного контроля над своими данными.
- Могут обеспечиваться разные уровни услуг по обработке запросов к DSSP, и в некоторых случаях они могут возвращать наилучшие из возможных приблизительные ответы. Например, если некоторые источники данных становятся недоступными, DSSP может обеспечить наилучший из возможных результат на основе данных, доступных во время выполнения запроса.
- DSSP должны поддерживать средства для обеспечения более тесной интеграции данных пространства, если это становится необходимо.
4.1.2 Логическая организация и службы DSSP
В пространстве данных должна содержаться вся информация, уместная для конкретной организации, несмотря на формат и местоположение этой информации, а также моделироваться развитый набор связей между репозиториями данных. Поэтому на логическом уровне пространство данных представляется как набор
участников и
связей.
Участниками пространства данных являются индивидуальные источники данных: они могут быть реляционными базами данных, репозиториями XML, текстовыми базами данных, Web-сервисами и пакетами программного обеспечения. Они могут храниться или быть потоками данных (локально управляемыми системами потоков данных), или даже сенсорными установками. Некоторые участники могут поддерживать выразительные языки запросов, а другие - быть неинтеллектуальными и поддерживающими лишь ограниченные интерфейсы для формулировки запросов (например, структурированные файлы, Web-сервисы или другие софтверные пакеты). Участники могут быть очень структурированными (например, реляционными базами данных), полуструктурированными (XML, коллекции кода) или полностью неструктурированными. Некоторые источники могут поддерживать традиционные операции обновления, другие - допускать только добавления (в целях архивации), а третьи могут быть полностью неизменчивыми.
В пространстве данных должна иметься возможность моделирования любого вида связи между двумя (или несколькими) участниками. Нужно уметь представлять в виде связей традиционные ситуации, когда один участник является представлением или репликой другого участника, или когда схемы двух участников отображаются одна на другую. Однако желательно уметь моделировать намного более широкий набор связей, например, что источник A был вручную произведен из источников B и C, или что источники E и F создавались независимо, но отражают одну и ту же физическую систему. Связи могут быть даже менее конкретными, например, отражающими ту ситуацию, что два набора данных образованы из одного источника данных в одно и то же время. Пространства данных могут вкладываться одно в другое, и они могут перекрываться. Поэтому в пространстве данных должны содержаться правила разграничения доступа. Вообще говоря, в некоторых случаях границы между пространствами данных могут быть плавающими, но в большинстве случаев эти границы будут определяться естественным образом.
Вместе с неоднородностью содержимого пространства данных возникает потребность в поддержке нескольких стилей доступа к данным. По всей видимости, DSSP будут допускать много разных режимов взаимодействия, и требуется предельная общность, чтобы допустить применение различных служб к различным типам содержимого.
Базовой службой пространства данных является каталогизация элементов данных от участников. Каталог - это реестр ресурсов данных, содержащий наиболее общую информацию о каждом из них: источник, имя, местоположение в источнике, размер, дата создания и владелец и т.д. Каталог является инфраструктурой для большинства других сервисов пространства данных, но он также может поддерживать базовый пользовательский интерфейс просмотра пространства данных.
Двумя основными службами, которые будут поддерживаться в DSSP, являются поиск и запрашивание данных. Поиск является основным механизмом работы конечных пользователей с большими коллекциями незнакомых данных. Поиск менее требователен, чем запрашивание данных, поскольку он основан на сходстве, предоставлении конечным пользователям ранжированных результатов и поддержке интерактивного совершенствования. DSSP должны позволять пользователям задавать поисковый запрос и итерационно его совершенствовать, если это уместно, до вида запроса в стиле базы данных. Ключевой принцип пространств данных состоит в том, что поиск должен быть применим ко всему содержимому пространства данных, независимо от форматов данных. Универсальные возможности поиска и запросов должны распространяться на метаданные. У пользователей должны иметься возможности нахождения требуемых источников данных и получения информации об их сложности, корректности и актуальности.
DSSP будут также поддерживать и обновления данных. Очевидно, что эффекты обновлений будут определяться уровнем изменчивости соответствующих источников данных. Одной из основных исследовательских проблем пространств данных является разработка и обеспечение гарантированной семантики обновлений в разнородной среде с высоким уровнем автономности компонентов.
Другие ключевые сервисы DSSP включают мониторинг, обнаружение событий и поддержку сложных потоков работ. Например, мы можем захотеть произвести вычисление при поступлении новой части данных и распространить результаты этого вычисления в набор приемных источников данных. Аналогично, в DSSP должны поддерживаться различные формы анализа данных.
Не каждый участник пространства данных будет обязательно обеспечивать интерфейсы, требуемые для поддержки всех функций DSSP. Поэтому появится потребность в различных расширениях источников данных. Источник не обязательно будет хранить свои собственные метаданные, поэтому для таких источников нам потребуется независимый репозиторий метаданных. Может потребоваться облечение информации во внешнюю форму на основе источника или его контекста. Для источников, в которых отсутствует собственная служба нотификации, может потребоваться поддержка соответствующего мониторинга.
4.1.3 Архитектурные компоненты
В соответствии с перечисленными в предыдущем пункте службами, выделяются следующие архитектурные компоненты DSSP.
Каталог и просмотр. Каталог содержит информацию обо всех участниках пространства данных и о связях между ними. Для каждого участника каталог должен включать схему источника, статистические данные, скорость изменения, точность, возможности ответов на запросы, информацию о владельце и данные о политике доступа и поддержке конфиденциальности. Связи могут сохраняться в виде преобразований запросов, графов зависимости, а иногда даже в виде текстовых описаний.
При наличии возможности в каталоге должен содержаться базовый реестр элементов данных в каждом участнике: идентификатор, тип, дата создания и т.д. Тогда в нем можно поддерживать базовую возможность просмотра объединенного реестра всех участников. Интерфейс просмотра можно использовать для ответов на вопросы пользователей о наличии или отсутствии элемента данных или определения того, какие участники хранят документы данного типа.
Поверх каталога DSSP должна поддерживаться среда управления моделями, позволяющая создавать новые связи и манипулировать существующими связями (например, объединять или инвертировать отображения, сливать схемы и создавать единые представления нескольких источников).
Поиск и запрашивание. У пользователей должна иметься возможность запроса любого элемента данных, независимо от его формата и модели данных. В начале работы с пространством данным DSSP должна поддерживать для каждого участника запросы по ключевым словам. По мере получения большей информации об участнике, DSSP должна постепенно начать поддерживать более сложные запросы. Должно поддерживаться плавное переключение между запросами по ключевым словам, просмотром и структурированными запросами.
Структурированные запросы могут поддерживаться на основе общих интерфейсов (схем-посредников), обеспечивающих доступ к нескольким источникам, или же они могут адресоваться к конкретному источнику данных (с использованием его собственной схемы) с намерением получения ответов и от других источников. Запросы могут формулироваться на разнообразных языках (и на основе разных моделей данных), и они должны, по возможности, наилучшим образом переформулироваться на другие модели данных и схемы, обеспечивая точные и приближенные семантические отображения.
В системе должен поддерживаться широкий спектр запросов к метаданным. Должны обеспечиваться возможности получения данных об источнике ответа или о том, как этот ответ был выведен или вычислен; обеспечения временных меток на элементах данных, которые участвовали в вычислении ответа; указания того, какие другие элементы данных в пространстве данных могут зависеть от заданного элемента данных; запрашивания источников и уровня недостоверности ответа. DSSP должны также поддерживать запросы на установление местоположения данных, ответами на которые являются источники данных, а не конкретные элементы данных. При наличии XML-документа должна иметься возможность запросить XML-документы с похожей структурой и получить соответствующие XML-преобразования. При наличии фрагмента схемы или описания Web-сервиса должно быть возможно найти в пространстве данных похожие фрагменты.
Все перечисленные службы поиска и запрашивания данных должны также поддерживаться в инкрементной форме, применимой в реальном времени к потоковым или изменяемым источникам данных. Мониторинг может быть организован в виде процесса без состояния, в котором элементы данных рассматриваются по отдельности, или в виде процесса с состоянием, в котором анализируется несколько элементов данных. Служба инкрементного мониторинга может обеспечить дополнительные функции обнаружения сложных событий и генерации сигналов.
Локальное хранение и индексирование. В DSSP должен иметься компонент хранения и индексирования, обеспечивающий следующие возможности: создание запрашиваемых ассоциаций между объектами данных от разных участников; совершенствование доступа к источникам с ограниченными собственными средствами доступа; обеспечение возможности выполнения некоторых запросов без доступа к реальному источнику данных; поддержку высокого уровня доступности и восстановления.
Средства индексирования должны обладать высоким уровнем адаптивности к неоднородным средам. В качестве входных данных должно приниматься любое элементарное значение, встречающееся в пространстве данных, и должны выдаваться координаты всех объектов данных, в которых имеется такое значение, и роли каждого его вхождения. Важными аспектами индекса является то, что, во-первых, он определяет информацию для всех участников, когда некоторые значения входят в несколько источников данных. Во-вторых, индекс должен справляться с разнообразием ссылок на объекты реального мира.
Может потребоваться кэшировать некоторые фрагменты пространства данных (вертикальные или горизонтальные), чтобы строить на них дополнительные индексы для поддержки более эффективного доступа; повышать уровень доступности данных, хранимых в ненадежных участниках и уменьшать нагрузку на участников.
Компонент раскрытия. Назначение этого компонента состоит в обнаружении участников в пространстве данных, создании связей между ними и оказании помощи администраторам при совершенствовании и усилении этих связей. Обнаружение участников может происходить в нескольких формах, например, в форме обхода справочной структуры, начиная от корня, или форме поиска координат всех баз данных в корпоративной сети. Компонент должен выполнять начальную классификацию участников на основе их типов и содержимого.
После раскрытия участников система должна обеспечить среду для полуавтоматического создания связей между участниками и совершенствования и поддержки существующих связей. Этот процесс включает нахождение пар участников, которые, вероятно, должны быть связаны один с другим, и предложение связей, которые потом проверяются и уточняются человеком. Компонент раскрытия должен осуществлять мониторинг содержимого пространства данных, чтобы можно было со временем предложить новые связи.
Компонент расширения источников. У некоторых участников могут отсутствовать существенные функции управления данными. У DSSP должны иметься средства наполнения такого участника дополнительными возможностями, такими как схема, каталог, поиск по ключевым словами и мониторинг обновлений. Может оказаться необходимо обеспечивать эти расширения "по месту", поскольку могут иметься существующие приложения или потоки данных, рассчитанные на имеющиеся форматы или справочные структуры.
Этот компонент также должен поддерживать информацию с "добавленной стоимостью", сохраняемую DSSP, но не присутствующую в исходных участниках. Такая информация может включать "лексические переходы" между словарями, таблицы трансляции закодированных значений, классификаторы и рейтинги документов, а также аннотации или ссылки, привязанные к наборам данных или содержимому документов. Должна иметься возможность распространения такой информации на несколько участников.
Хотя DSSP с полным набором служб должны содержать все эти компоненты, многие из них могли бы использоваться независимо для достижения некоторого компромисса между расходами и получаемыми преимуществами. Важно, что DSSP допускает инкрементное инвестирование, а не представляет собой только монолитное решение.
4.1.4 Новые исследовательские проблемы
В последнем разделе [
13] авторы приводят ряд проблем, решение которых требуется для полноценной реализации концепции пространства данных.
Моделирование данных и базовые возможности запросов. В отличие от СУБД, в ядре DSSP требуется поддержка нескольких моделей данных, чтобы естественным образом поддерживалось как можно больше типов участников. Модели данных, поддерживаемые DSSP, будут образовывать иерархию в соответствии с их выразительной мощностью. Каждый участник пространства данных поддерживает некоторую модель данных и некоторый язык запросов, соответствующий этой модели.
На самом верхнем уровне иерархии находятся коллекции именованных ресурсов, возможно, с базовыми свойствами - размер, дата создания и тип. "Запрос" к такой модели данных соответствует тому, что обычно поддерживается в файловых системах по отношению к их директориям: сопоставление имен, поиск в диапазоне дат, сортировка по размеру файла и т.д. На следующем уровне DSSP должны поддерживать модель данных мультимножества слов, обеспечивающую возможность формулировки запросов по ключевым словам для любого участника пространства данных. Ниже уровня модели мультимножества слов в иерархии может располагаться модель полуструктурированных данных, основанная на помеченных графах. Если участник поддерживает некоторую структуру, то должна иметься возможность формулировки простых путевых запросов или запросов по включению, а может быть, и более сложных запросов, основанных на модели полуструктурированных данных. В иерархии будут присутствовать и другие модели данных: реляционная модель, XML со схемой, RDF, OWL (Web Ontology Language).
Проблема состоит в переформулировании запроса, представленного на сложном языке, для источника, который поддерживает более слабую модель данных, и наоборот, переформулировании запроса, представленного на простом языке, для источника, который поддерживает более выразительные модель данных и язык запросов (например, запрос по ключевым словам к реляционной базе данных).
Более широкое представление запрашивания. Ключевой проблемой является обеспечение интуитивных средств поиска и запрашивания всего, что угодно. С точки зрения пользователя различие между поиском и запрашиванием должно исчезнуть. Пользователи должны начинать с простейших способов поиска, а затем, по мере потребности, направляться к более специальным интерфейсам поиска и запросов. На основе имеющегося запроса система должна обеспечивать для пользователя полезные советы относительно других тем, которые могут быть ему интересны, и возможностей соответствующего поиска. Нужно также разработать интуитивную визуализацию результатов, направляющую пользователей в правильном направлении.
Раскрытие пространства данных. Распространенной проблемой сегодняшних крупных предприятий состоит в том, что они даже не знают, какие источники данных имеются в организации. Окончательной целью раскрытия пространства данных является обнаружение участников пространства данных, создание связей между ними и повышение точности существующих связей между участниками. Исследовательской проблемой является создание системы раскрытия пространства данных, обеспечивающей обнаружение участников в организации; кластеризацию участников и нахождения связей между ними в полуавтоматическом режиме; создание более точных связей между участниками (в пределе, отображений схем).
Повторное использование человеческого труда. Важно, чтобы DSSP знали, как повторно использовать работу, проделанную людьми, обобщать ее результаты и повторно их использовать для решения других задач. Задача состоит в том, чтобы предыдущая работа запоминалась в системе, и ее результаты могли использоваться при попытках создания дополнительных связей между участниками пространства данных или ответов на запросы к этому пространству. По мнению авторов, при решении этой проблемы будут полезными методы машинного обучения (Machine Learning).
Хранение и индексирование пространств данных. Ключевые проблемы, возникающие при создании компонента DSSP локального хранения и индексации, связаны с неоднородностью индекса. Индекс должен единообразно индексировать все возможные элементы данных, являются ли они словами, встречающимися в тексте, значениями, встречающимися в базе данных, или элементом схемы одного из источников. Кроме того, в индексе должна предусматриваться возможность наличия нескольких способов ссылки на один и тот же объект реального мира. Сложно будет поддерживать индекс в актуальном состоянии, особенно для участников, не имеющих механизмов извещения об обновлениях. Кроме того, несколько интересных проблем автоматической настройки следуют из потребности решать, какие части пространства данных следует кэшировать в локальном хранилище, и какие индексы следует создавать и поддерживать
Гарантии корректности. Исследовательская проблема состоит в определении реализуемых, практичных и осмысленных уровней гарантий обслуживания, которые могут быть обеспечены в области пространств данных. Для решения этой проблемы потребуется переосмыслить многие фундаментальные принципы управления данными и ввести новые абстракции. Также потребуются инструментальные средства, помогающие разработчикам и пользователям понимать неустранимые компромиссы в терминах качества, эффективности и контроля.
Теоретические основы. Имеется несколько вопросов относительно теоретических обоснований пространств данных. Требуется формальное понимание различных моделей данных, связей и ответов на запросы в пространстве данных. Требует изучения выразительная мощность языка запросов над множеством участников с использованием определенных свойств связей, специфицированных между ними: Какие запросы могут быть выражены над пространством данных? Как распознать семантически эквивалентные, но синтаксически различные способы ответов на запросы?
4.2 Пространства данных и Лоуэллский отчет
В заключение [
13] авторы говорят: "Пространства данных можно считать "зонтиком" для большей части исследований, которые уже активно ведутся в сообществе баз данных; на самом деле, в этом и состояла одна из исходных целей. Однако мы также попытались очертить несколько новых исследовательских возможностей, которые происходят из более целостного представления возникающих проблем "данных повсюду". Исследовательское сообщество баз данных однозначно решило заняться решением этих проблем, и мы предвидим непрерывный прогресс в расширении области применения технологии управления данными". В действительности, это утверждение полностью подтверждается при сопоставлении идей и предложений [
13] с положениями Лоуэллского отчета.
Пункт 2.1.1 (интеграция текста, данных, кода и потоков) в [13] развивается и обогащается на основе идеи иерархии моделей данных. В данном случае говорится не об однородной интеграции в пределах одной базы данных, а об организации однородного доступа к разнородным источникам данных. Но цель преследуется та же, и мне кажется заманчивой перенести идею иерархии моделей на локальную СУБД.
Пункт 2.1.2 (слияние информации) в контексте [13] получает оригинальную и, как мне кажется, предельно ясную трактовку. С использованием предусматриваемых в [13] компонентов DSSP и зависящего от конкретной ситуации объема человеческого труда можно обеспечить интеграцию любого числа источников данных любой природы с требуемым уровнем качества (в зависимости, конечно, от качества исходных данных в источниках). Возможность внешнего индексирования и кэширования позволяет добиться компромисса между виртуальной интеграцией данных и построением физически отдельного хранилища данных. Весь вопрос в том, сколько это будет стоить.
Что касается пункта 2.2.1 (неточные данные), то при работе с пространствами данных придется сталкиваться и неполнотой данных (вследствие, например, недоступности некоторых источников или устареванием данных в кэше), и с неточностью запросов (в связи, например, с возможностью сочетания поисковых и структурированных запросов). И снова авторы предлагают прагматичный подход, позволяющий пользователям итеративным образом совершенствовать результаты своих запросов путем сочетания различных стилей доступа к данным.
Пункт 2.3.1 (самоадаптация) трансформируется в [13] в "повторное использование человеческого труда". И снова это кажется очень здравой идеей, поскольку первичным источником знаний, которыми должна руководствоваться программная система, является человек.
Наконец, целый ряд идей [13] можно соотнести с пунктом 2.3.4 (пользовательские интерфейсы). Здесь и комбинирование средств контекстного поиска и структурированных запросов, и итерационное совершенствование формы запроса под руководством системы, и т.д.
5. Заключение
Большая часть публикаций, относящихся к области управления данными, носит чрезвычайно конкретный характер, описывая новые или усовершенствованные методы и алгоритмы решения некоторых частных задач. Эти задачи кажутся авторам публикаций настолько привычными и естественными, что обычно они даже и не пытаются объяснить читателям их происхождение и актуальность. В Асиломарском отчете [
2] такого рода исследовательские работы относились к категории "delta-X". "Исследования "delta-X" отличаются тем, что сосредотачиваются на сиюминутной цели, "улучшении" некоторой уже широко известной идеи X."
Для реального развития области управления данными необходимы работы, выходящие за пределы этой категории, и их появление стимулируется отчетами регулярных собраний ведущих исследователей. Одним из результатов собрания в Лагуна-Бич [1] стало появление Манифеста систем объектно-ориентированных баз данных [8] и Манифеста систем баз данных третьего поколения [9], за которыми последовал Третий манифест Криса Дейта и Хью Дарвена [10]. Эти документы во многом определили развитие технологии баз данных в конце прошлого столетия.
Публикации [12] и [13], последовавшие за официальным опубликованием Лоуэллского отчета [7], кажутся мне продолжением этой традиции в новом столетии. Отличаясь по духу и форме от классических манифестов, эти работы обеспечивают основу нового этапа развития технологии управления данными.
Литература
| [1] | Philip A. Bernstein, Umeshwar Dayal, David J. DeWitt, Dieter Gawlick, Jim Gray, Matthias Jarke, Bruce G. Lindsay, Pete C. Lockemann, David Maier, Erich J. Neuhold, Andreas Reuter, Lawrence A. Rowe, Hans-Jörg Schek, Joachim W. Schmidt, Michael Schrefl, and Michael Stonebraker. Future Directions in DBMS Research - The Laguna Beach Participants. SIGMOD Record 18(1): 17-26 (1989) |
| [2] | Philip A. Bernstein, Michael L. Brodie, Stefano Ceri, David J. DeWitt, Michael J. Franklin, Hector Garcia-Molina, Jim Gray, Gerald Held, Joseph M. Hellerstein, H. V. Jagadish, Michael Lesk, David Maier, Jeffrey F. Naughton, Hamid Pirahesh, Michael Stonebraker, and Jeffrey D. Ullman. The Asilomar Report on Database Research. SIGMOD Record 27(4): 74-80 (1998). |
| [3] | Сергей Кузнецов. Направления исследований в области баз данных: десять лет спустя. Открытые системы, N 1, 1999 |
| [4] | The Lowell Database Research Self-Assessment Meeting. |
| [5] | Jim Gray, Hans Schek, Michael Stonebraker, Jeff Ullman. The Lowell Report. Proceedings of the 2003 ACM SIGMOD International Conference on Management Of Data. http://www.sigmod.org/sigmod03/eproceedings/papers/panel2.pdf |
| [6] | Сергей Кузнецов. Крупные проблемы и текущие задачи исследований в области баз данных. |
| [7] | Serge Abiteboul, Rakesh Agrawal, Phil Bernstein, Mike Carey, Stefano Ceri, Bruce Croft, David DeWitt, Mike Franklin, Hector Garcia Molina, Dieter Gawlick, Jim Gray, Laura Haas, Alon Halevy, Joe Hellerstein, Yannis Ioannidis, Martin Kersten, Michael Pazzani, Mike Lesk, David Maier, Jeff Naughton, Hans Schek, Timos Sellis, Avi Silberschatz, Mike Stonebraker, Rick Snodgrass, Jeff Ullman, Gerhard Weikum, Jennifer Widom, and Stan Zdonik. The Lowell Database Research Self-Assessment. Commun. ACM, 48(5):111-118, 2005. |
| [8] | Malcolm Atkinson, Francois Bancilhon, David DeWitt, Klaus Dittrich, David Maier, and Stanley Zdonik: "The Object-Oriented Database System Manifesto", Proc. 1st International Conference on Deductive and Object-Oriented Databases, Kyoto, Japan (1989). New York, N.Y.: Elsevier Science (1990), http://www.cl.cam.ac.uk/Teaching/2003/Databases/oo-manifesto.pdf. (Имеется русский перевод: М. Аткинсон и др. "Манифест систем объектно-ориентированных баз данных", СУБД, No. 4, 1995.) |
| [9] | M. Stonebraker, L. Rowe, B. Lindsay, J. Gray, M. Carey, M. Brodie, Ph. Bernstein, D. Beech. "Third-Generation Data Base System Manifesto" Proc. IFIP WG 2.6 Conf. on Object-Oriented Databases, July 1990, ACM SIGMOD Record 19, No. 3 (September 1990). http://www.cl.cam.ac.uk/Teaching/2003/DBaseThy/or-manifesto.pdf. (Имеется русский перевод: Стоунбрейкер М. и др. "Системы баз данных третьего поколения: Манифест", СУБД, No. 2, 1996) |
| [10] | Hugh Darwen and C. J. Date: The Third Manifesto. ACM SIGMOD Record 24, No. 1 (March 1995), http://www.sigmod.org/sigmod/record/issues/9503/manifesto.ps. (Имеется русский перевод: Х. Дарвин, К. Дейт. "Третий манифест", СУБД, No. 1, 1996) |
| [11] | Сергей Кузнецов. Три манифеста баз данных: ретроспектива и перспективы. Базы данных и информационные технологии XXI века. Материалы международной научной конференции. Москва, 29-30 сентября 2003 г. Москва, РГГУ, 2004, стр. 52-229. |
| [12] | M. Stonebraker, U. Cetintemel, and S. Zdonik: The 8 Requirements of Real-Time Stream Processing. ACM SIGMOD Record 34, No. 4 (December 2006), http://www.sigmod.org/sigmod/record/issues/0512/p42-article-stonebraker.pdf. (Имеется русский перевод: Майкл Стоунбрейкер, Угур Гетинтемел, Стэн Здоник. "Восемь требований к системе потоковой обработки в реальном времени") |
| [13] | M. Franklin, A. Halevy and D. Maier: From Databases to Dataspaces: A New Abstraction for Information Management. ACM SIGMOD Record 34, No. 4 (December 2006), http://www.sigmod.org/sigmod/record/issues/0512/p27-article-franklin.pdf. (Имеется русский перевод: Майкл Франклин, Элон Хэлеви, Дэвид Майер. "От баз данных к пространствам данных:новая абстракция управления информацией".) |
| [14] | Samuel Madden, Michael J. Franklin, Joseph M. Hellerstein, Wei Hong. TinyDB: An Acquisitional Query Processing System for Sensor Networks. ACM TODS, 30, No. 1 (March 2005), http://db.csail.mit.edu/madden/html/tinydb_tods_final.pdf |
| [15] | C. Li, K. C.-C. Chang, I. F. Ilyas, and S. Song: RankSQL: Query Algebra and Optimization for Relational Top-k Queries. In Proceedings of the 2005 ACM SIGMOD Conference (SIGMOD 2005), Baltimore, Maryland, June 2005, http://eagle.cs.uiuc.edu/pubs/2005/ranksql-sigmod05-lcis-mar05.pdf |
| [16] | Ganesh Ramesh, William A. Maniatty. Mohammed J. Zaki. Indexing and Data Access Methods for Database Mining: 7th ACM SIGMOD Workshop on Research Issues in Data Mining and Knowledge Discovery (DMKD'2002), Madison, WI, June 2002, www.bell-labs.com/user/minos/DMKD02/Papers/ramesh.pdf |
| [17] | Surajit Chaudhuri, Vivek R. Narasayya, Sunita Sarawagi. Extracting predicates from mining models for efficient query evaluation. ACM Trans. Database Syst. 29(3): 508-544 (2004), http://hwanjoyu.org/teaching/dmml-s06/lecture-note/extracting-predicate.pdf |
| [18] | Special Issue on Data Stream Processing. Bulletin of the Technical Committee on Data Engineering, Vol. 26 No. 1 (March 2003) |
| [19] | David Maier. The Theory of Relational Databases. Computer Science Press, 1983. (Русский перевод: Мейер М. Теория реляционных баз данных. - М.: Мир, 1987.) |
| [20] | Stanley B. Zdonik, David Maier. Readings in Object-Oriented Database Systems, Morgan Kaufmann, 1990 |
| [21] | Mike Franklin, Alon Halevy, David Maier, Jennifer Widom. Dataspaces: A New Abstraction for Data Management. http://db.cs.berkeley.edu/dblunch-fa2005/alon.pdf |
| [22] | H. Garcia-Molina, J.D. Ullman, and J. Widom. Database Systems - The Complete Book. Prentice Hall, 2002. (Русский перевод: Гектор Гарсиа-Молина, Дженнифер Уидом, Джеффри Ульман. Системы баз данных. Полный курс. Изд. "Вильямс", 2003 г.) |
| [23] | Alon Halevy. Why Your Data Won't Mix. ACM Queue, 3, No. 8 (October 2005) |
| [24] | Donald Kossmann, Jens-Peter Dittrich. Personal Data Spaces. |
*обратно к тексту Под "обобщенной конкретизацией" я понимаю здесь публично опубликованную точку зрения нескольких авторитетных исследователей из разных организаций относительно конкретных путей решения достаточно общей проблемы.

 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС

