|

2003 г
Объектно-ориентированная организация реляционных данных
(формальное обоснование объектно-ориентированных систем управления реляционными БД)
Евгений Григорьев (grg@comail.ru)
Одной из наиболее актуальных проблем, существующих в области хранения данных, является проблема объединения свойств, присущих объектно-ориентированным программам и реляционным системам хранения данных, в рамках единой универсальной системы обработки и хранения информации.
Обращает на себя степень единодушия в отношении желаемых возможностей такой системы [1,2,3].
Предлагаемое решение основывается на принципиальной возможности использования реляционной системы как в качестве единственного терминального механизма хранения данных, лежащего в основе объектно-ориентированной системы (метафора "реляционное
ОЗУ"). Предлагается формальное описание системы, основанной на этом подходе. Вводятся правила, позволяющие создать объектную схему данных на основании схемы данных, возникшей в процессе нормализации. Анализируются свойства системы, основанной на предлагаемом подходе.
Оглавление
Введение.
Формальное описание системы.
Стержневое отношение.
Ссылки.
Проектирование схемы данных.
Ортогональные типы данных.
Объектная привязка нормализованной схемы данных.
Свойства системы.
Групповые операции. Ненавигационный доступ к данным.
Групповые операции над ссылками.
Вычисляемые атрибуты объектов. Инкапсуляция.
Наследование.
Переопределение атрибутов.
Метаданные
Каталог.
Связь данных и метаданных.
Методы.
Заключение.
Также статья доступна в формате MS Word: OOORD.zip
Введение.
Современные информационные системы можно
рассматривать как многоуровневые
кибернетические1) системы,
в которых поступающие извне команды управления данными,
существующими в программных объектах
описывающих сущности моделируемой
предметной области [4], трансформируются в
команды, управляющие используемым
оперативным запоминающим устройством (ОЗУ) .
В свою очередь данные, существующие в ОЗУ, приводятся к виду, определяемому используемой абстракцией. Преобразования команд и данных, позволяющие реализовать используемую абстракцию, описываются программой. ОЗУ можно рассматривать как терминальный механизм2) хранения с неизвестным устройством, который определен только через способ обращения к нему и действия, которые он производит по отношению к другим частям системы.
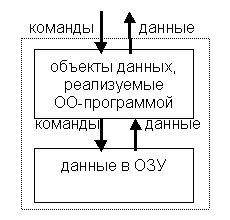
Для долговременного хранения данных программа должна обращается к внешним запоминающим устройствам. Такая организация является следствием ряда причин, среди которых можно выделить неспособность подавляющего большинства типов ОЗУ к постоянному хранению информации, а также ограничение размера адресуемого ОЗУ и его относительную дороговизну. Используемые в настоящее время СУБД представляют собой результат развития средств управления внешними запоминающими устройствами
(ВЗУ) [5]. С этой позиции объектная программа, которая работает с данными, находящимися в
линейной оперативной памяти (линейное ОЗУ), и использует для их постоянного хранения реляционную СУБД, будет выглядеть следующим образом.
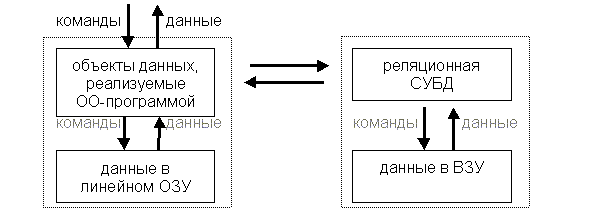
Отметим, что СУБД, используемую для долговременного хранения данных, тоже можно рассматривать как терминальное устройство, организующее эти данные в виде реляционной БД3). Фактически, программа осуществляет обмен данными межу двумя терминальными устройствами, одно из которых хранит данные в процессе обработки, а другое служит для их долговременного хранения.
Утверждая, что программы (в том числе и объектные) работают с данными, хранящимися в оперативной памяти, а СУБД являются средством управления внешних запоминающих устройств, необходимо обратить внимание на то, что
деление запоминающих устройств на оперативные и внешние с
развитием программных и аппаратных средств
смещается с физического уровня на логический. В самом деле, предоставляемый современными операционными системами логический ресурс, называемый "оперативная память", представляет собой виртуальную память, размеры которой могут многократно превосходить имеющееся в наличие физическое ОЗУ за счет использования дисковых подсистем (т.е. ВЗУ). Существуют ОС, позволяющие
сохранять на диске полный образ ОЗУ, что фактически делает хранящиеся в нем данные постоянными во времени. С другой стороны, организую эффективную работу с ВЗУ, современные СУБД используют огромные массивы физического ОЗУ
4).
Сравнивая линейное ОЗУ и реляционную СУБД как терминальные механизмы хранения данных, можно прийти к выводу, что наиболее важным логическим отличием между ними является отличие в организации доступа к данных. OЗУ предполагает адресный способ доступа. Отметим, что системы управления БД в процессе своего развития [5] отказались от такой организации. Реализуя принцип независимости данных [6], реляционные СУБД организует ассоциативный доступ к данным по явно заданному значению.
Реляционные системы обладают рядом неоспоримых преимуществ, существенных именно для систем хранения данных. Они являются реализациями математически строгой модели[7,8], дающей однозначные и строгие определения используемых структур и операций. Реляционная алгебра работает с множеством записей как с единым целым, применяя операцию к множеству записей целиком и производя множество записей в результате. Для доступа к данным реляционные системы используют непроцедурный высокоуровневой язык, реализующий ненавигационный доступ к данным [9,10].
Осознавая преимущества реляционного подхода, рассмотрим возможность создания объектной системы, базирующейся на одном, единственно-возможном терминальном механизме хранения информации, который описывается реляционной моделью данных. Предполагается, что этот это механизм позволяет хранить данные в процессе их обработки и, одновременно, осуществляет их долговременное хранение.
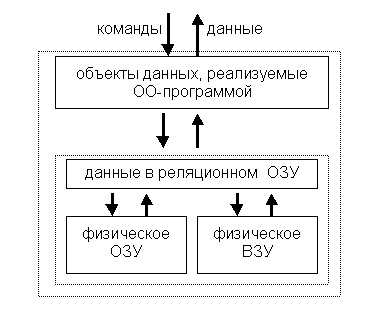
Оговоримся, что предлагаемый подход, рассматривающийся как основа для организации систем хранения данных, является исключительно логическим
и формальным построением, которое не имеет ничего общего с организацией аппаратных средств (используемый термин "реляционное ОЗУ" можно рассматривать как достаточно удачную метафору, отражающую тот факт, что
единственное терминальное устройство хранения данных может быть описано реляционной моделью).
Он может быть интересен по следующим причинам.
- Существующая реляционная модель данных не нуждается в каких-либо изменениях или дополнения.
- Отсутствует необходимость в организации обмена данных между разными терминальными механизмами хранения данных.
- Решается вопрос перманентности данных
Формальное описание системы
Сформулируем задачу.
В системе хранения данных, реализующей реляционную модель, необходимо сохранить информацию об объектах моделируемой предметной области. Информация о моделируемых объектах представляет собой набор сложных значений oV, хранящихся в идентифицируемых переменных (в дальнейшей – объекты данных). Объект данных o можно описать как {OID, S, oV}, где OID – уникальный идентификатор указанной переменной, S – информация, описывающая структуру указанной переменной (метаданные), где, в частности, перечисляются поименованные атрибуты объекта данных, oV - сложное значение, описывающее состояние объекта. Каким же образом эта информация может быть представлена в реляционном ОЗУ?
Теория реляционных БД предполагает, что
для обеспечения эффективного хранения
данных (что подразумевает их целостность и
непротиворечивость) , эти данные должны
быть нормализованы [8,9,10]. Процесс нормализации сложных значений является формальным методом, основанным на анализе зависимостей между значениями атрибутов этого сложного значения. В результате этого процесса информация, описывающая систему, состоящую из многих объектов, преобразуется к множеству значений разных отношений. Между исходным множеством объектов и результирующим множеством отношений существует отношение "многие ко многим": каждое отношение может состоять из кортежей, описывающих многие объекты, и, в свою очередь, каждый объект может описываться кортежами, входящими во многие отношения, причем в каждое отношение может входить любое число кортежей, описывающих данный объект. Каждому из исходных объектов в каждом их результирующих отношений будет соответствовать некоторое, возможно пустое подмножество кортежей. Поскольку любое подмножество кортежей отношения также является отношением, можно утверждать, что полное значение oV любого объекта o из исходного множества объектов можно представить в виде набора значений разных отношений.
Таким образом, объект o можно описать как {OID, S, {r1,r2….rn}} где ri – некоторое значение отношения Ri, возникшее в результате нормализации значения oV (в дальнейшем мы остановимся на процессе проектирования более подробно). Отметим, что на данном этапе мы никак не определяем возможные схемы отношений Ri. Предполагается, что возможность, позволяющая описать объектную переменную и задать множество значений отношений {r1,r2….rn}, не может быть выражена в терминах реляционной модели данных и, следовательно, ортогональна ей.
Будем рассматривать каждое из значений ri как значение именованного атрибута объекта о. Тогда атрибут
должен рассматриваться как переменная отношения, а схема объекта данных должна перечислять имена атрибутов. Соответственно, объект o будет описываться как
o = {OID,{oa1, oa2,…, oan},{r1,r2….rn}}, <0>
где ri – значение отношения Ri со схемой (ra1:D1, ra2:D2….), ri = relval(Ri), Dj, - не
обязательно разные домены из
множества D доменов. Заметим, что в системе O может одновременно существовать множество не обязательно разных значений r одного и того же отношения R, являющихся значениями атрибутов разных объектов или значениями разных атрибутов одного и того же объекта.
Покажем, что информация, представленная в виде множества объектов вида 0, может быть полностью сохранена в реляционной системе хранения данных.
Рассмотрим множество O всех входящих в в систему объектов о вида <0>. Мы можем говорить о существовании множества oa всех имен атрибутов oa этих объектов. Каждому объекту oi(oi
О O) ставиться в соответствие схема объекта Si = oSchema(oi), которая является собственным подмножеством множества oa , S Н oa . Одна и та же схема S может быть поставлена в соответствие многим объектам. Классом С, С Н O называют множество объектов с одинаковой схемой: объекты oi {OIDi, Si, oVi} и oj {OIDj, Sj, oVj} принадлежат одному и тому же класс С только тогда, когда oSchema(oi) = oSchema(oj). Таким образом, можно утверждать, что между множеством схем и множеством классов существует функциональное соответствие S= Schema(C)
Также мы можем говорить о существовании множества R всех определенных на множестве доменов D отношений R, значения которых являются значениями атрибутов oa объектов из множества O.
Каждому атрибуту oa ставиться в
соответствие одно и только одно отношение R из множества R, тем самым ограничивая множество возможных значений атрибута oa значениями этого отношения R. Поскольку речь идет о паре "множество - определенное на этом множестве значение " отношение R можно обозначить как домен атрибута oa. Однако, поскольку значение, определенное на этом домене, представляет собой значение отношения (relval) и также является множеством, будем называть отношение R реляционным доменом атрибута oa, R = rdom(oa). Возможен случай, что домены разных атрибутов совпадают rdom(oai) = rdom(oaj), ai№aj.
Таким образом, мы можем говорить о функциональном соответствии между множеством атрибутов oa и множеством отношений R,
R = rdom(oa) <2>
Это соответствие должно указываться в схеме объекта, которая будет перечислять пары oa : R, где R = rdom(oa)
o = {OID,{oa1:R1, oa2:R2,…, oan:Rn},{r1,r2….rn}}, <0'>
Собственное значение объекта o, принадлежащего классу С, можно представить как такое отображение oV из множества
oa в множество R (oa--Schema(C))-->R), что каждому oai принадлежащему Schema(C) (oai О Schema(C)) будет соответствовать значение отношения Rn, являющегося доменом oai oV(oai) = rval(Rn) , Rn = rdom(oai), а каждому oaj, не принадлежащему S (oaj П S), будет соответствовать пустое множество oV(oaj) = Ж.
Каждое такое отображение соответствует
уникальному значению, являющемуся идентификатором этого объекта. Тогда множество идентифицируемых объектов O есть
функциональное соответствие между множеством OID
уникальных идентификаторов OID объектов o, и множеством oV отображений (oa--Schema(C)-->R), формирующих собственные значения этих объектов.
O = (OID
-> oV). где oV = {oV| oV = oa--Schema(C)-->R} <3>
Крайне важен тот факт, что предлагаемая формализация однозначно определяет способ, позволяющий представить информацию, описывающую множество O объектов вида <0>, в терминах реляционной модели данных. В самом деле, исходя из <3>, множество объектов O можно представить как отношение, построенное на множествах OID, oa и R, то есть как подмножество декартового произведения множеств OID, oa и R.
O М OID ґ oa ґ R
<4>
Предположим, что значения уникальных идентификаторов объектов, входящих в множество
OID, определены на домене DOID (OID Н DOID), а имена их атрибутов, входящих в множество oa – на домене DA (oa Н DA), и рассмотрим множество доменов D', такое, что D' - D = {DOID,DA}. Можно показать, что
O М R' , R' = { R'i| R'i М DOID ґ DA ґ Ri, Ri О R}
<5>
Поскольку отношения Ri входящие в множество
R определены на множестве доменов D ( Ri (ra1:D1, ra2:D2….), D О D), то R'i является отношением, определенным на множестве доменов D'.
( Поскольку R = rdom(A), то <5> то более точным будет следующее
O М R' , R' = { R'i| R'i М DOID ґ rdom-1(Ri) ґ Ri, Ri О R },
<6>
Тем самым мы ограничили число возможных значений определенного на домене DA атрибута отношений R'i, именами только тех атрибутов объекта, для которых доменом является соответствующее отношению R'i отношение Ri. )
Таким образом, множество O объектов o вида <0> может быть однозначно преобразовано к множеству значений отношений R', входящих во множество R', причем между множеством R отношений, являющихся доменами атрибутов объектов o , и множеством R' существует такое взаимно-однозначное соответствие
R < --> R'
<7>
что для любого отношения Ri (ra1:D1, ra2:D2….), принадлежащему
R, во множестве R' будет существовать соответствующее отношение R'i (raOID: DOID, raoa:DA, ra1:D1, ra2:D2….), D О D'). В дальнейшем мы будем называть атрибуты raOID и raoa системными атрибутами.
Это можно проиллюстрировать следующим образом. Предположим, что в объекте o со схемой (… , oa:R , …), идентифицируемый уникальным значением OIDi, атрибут oa содержит значение r отношения R со схемой (ra1:D1, … , ran:Dn) o.oa = rval(R), состоящее из кортежей ti.
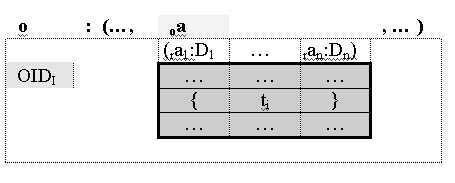
Значение r атрибута oa объекта o в множестве R' будет представлено в виде подмножества кортежей t'i отношение R' со схемой (raOID: DOID, raoa:DA, ra1:D1, … , ran:Dn), у которых атрибут raOID содержит значение OIDi и атрибут raoa содержит значение oa, t'i.raOID = OIDi, t'i.raoa = oa.
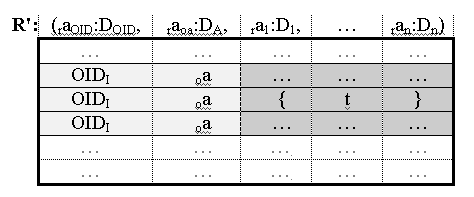
Реляционная переменная o.oa (атрибут oa объекта o) представлена в множестве R'
как следующее подмножество кортежей отношения R'
o.oa OєR' s(raOID=
OIDi, raoa = oa ) (R')
<8>
а собственное значение r указанной реляционной переменной вычисляется как
r = p!(raOID, raoa)(
s(raOID= OIDi, raoa = oa)(R'))
<8'>
где s(raOID= OIDi, raoa = oa ) - операция выборки по атрибутам raOID и raoa, а
p!(raOID, raoa) – операция проекции, отсекающая эти атрибуты.
Обозначение OєR' показывает, что выражению, обращающемуся к данным, представленным в виде объектов, входящих в множество
O (выражение слева от OєR'), соответствует выражение, управляющее данными, организованными в виде множества R'
отношений, существующих в терминальной систем хранения, т.е. реляционном ОЗУ (выражение справа).
Заметим, что на основании R
= rdom(oa) и R'« R, можно говорить о существовании между множествами R' и oa функционального соответствие rstorage, определяющего, какое из отношений R' будет служить для хранений значений атрибутов oa:
R' = rstorage(oa).
<9>
В отношении R' представлены значения всех определенных на реляционном домене R атрибутов, существующих во всех объектах о из множества O. Каждому имени атрибута oai соответствует подмножество Ai кортежей отношения R', A =
s( raoa = oai)(R'), где R' = rstorage(oai). Подмножество Ai по сути дела представляет собой объединение значений всех существующих атрибутов oai (o1.oai
И …И on.oai) где oi – объект содержащий атрибут oai. Поскольку атрибут oai, объявленный в некотором классе С (oai
О Schema(C) ), определен только в объектах этого класса С и в объектах классов С+, наследующих класс C, объединение (o1.oai
И …И on.oai) будем обозначать как С.ai ,
С.ai OєR A, A =
s( raoa = oai)(R'), где R' = rstorage(oai).
<10>
В дальнейшем множество O мы будем называть уровнем представления данных, а множество R' – уровнем хранения данных. На уровне представления данные существуют в виде объектов вида <0'>, причем
- объекты имеет уникальный идентификатор, и, следовательно, в системе могу существовать два объекта с абсолютно одинаковым собственным значением,
- значение атрибутов объектов есть значения отношений, представляющее собой множество кортежей – другими словами атрибут можно рассматривать как группу повторения.
На уровне хранения эта же информация представлена в виде множества значений отношений R' определенных на доменах из множества D'. Как мы уже сказали, что D' - D = {DOID, DA}, что, по сути дела, означает, что информация о уникальных идентификаторах объектов oi и о значениях, определяющих семантику атрибутов, на уровне хранения существует точно в таком же виде, как и информация о собственных значениях этих объектов, а именно в виде явно заданных значений атрибутов кортежей отношений R'. Таким образом, уровень хранения полностью описывается в терминах реляционной модели данных, что говорит о принципиальной возможности реализации метафоры "реляционное ОЗУ". С практической точки зрения этот факт интересен тем, что он позволяет реализовать уровень хранения, используя существующие реляционные СУБД. В наших дальнейших построениях мы будем исходить из того, что уровень хранения должен описываться только в терминах реляционной модели данных.
Стержневое отношение.
Говоря об образующем собственное значение объекта множестве {r1,r2….rn} значений отношений Ri, мы предположили, что возможность, позволяющая организовать такое множество, не может быть описана в терминах реляционной модели и, следовательно, ортогональна ей. С другой стороны данные на уровне хранения полностью описываются в терминах реляционной модели данных. Можно предположить, что механизм, организующий такое множество (в дальнейшем O-механизм), на уровне хранения
R' должен использовать атрибуты raOID и raoa, которые определены на доменах DOID и DA, не заданных на уровне представления
O.
Из соответствию <7> R« R', следует, что на уровне хранения может существовать отношению R'0(raOID: DOID, raoa:DA), для которого на уровне представления соответствующий реляционный домен R0(Ж) фактически отсутствует. Поскольку имя атрибута не определено, это отношение сводиться к отношению R'0(raOID: DOID), где поле raOID будет являться первичным ключом . Главная цель указанного отношения R'0 – перечислять объектные идентификаторы всех существующих в системе объектов. По сути дела, отношения R'0 (в дальнейшем мы будем называть его стержневым) организует адресное пространство системы. Поле raOID других отношений R'i, существующих на уровне хранения , должно быть внешним ключом связанный с R'0. raOID. Эта связь гарантирует, что любой кортеж любого отношения R'i содержит информацию об адресуемом объекте.
Отметим, что в стержневое отношение R'0 могут входить другие атрибуты, содержащие системную информацию, в частности информация о классе объекта (см. далее "Связь данных и метаданных"). В любом случае существенны два условия: 1) отношение R'0 должно быть скрыто от пользователя 2) поле raOID должно являться первичным ключом.
Ссылки.
На домене DOID может быть определен не только атрибут raOID, но и любой другой атрибут rai отношения R'. Этот факт важен, поскольку между множеством
OID определенных на DOID значений объектных идентификаторов (на уровень хранения), и множеством O объектов данных вида <0'> (уровень представления), существует взаимно-однозначное соответствие (OID «
O). Это позволяет рассматривать множество объектов как множество, на которых может быть определен любой атрибут rai отношения R, входящего во множество R, и говорить о существования домена DO (DO О
D) однозначно соответствующего домену объектных идентификаторов DO.
« DOID, существующему на уровню хранения (DOID
О D').
Таким образом некоторые объекты из множества
O могут входить в отношения Rref (RrefО
R) со схемой (… , raref : DO, …), которые будут являться реляционными доменами атрибутами других объектов из этого же множества. На уровне хранения отношению Rref соответствует отношение R'ref (R'refО
R') со схемой (raOID: DOID, raoa:DA,… , raref : DOID, …). Рассмотрим объект oi с атрибутом oa определенным на реляционном домене Rref (oi ) и кортеж t (… , oref , …) этого атрибута, поле raref содержит ссылку на объект oref . Используя точечную нотацию можно сказать, что выражение oi.oa.raref определяет существование множества, содержащее объект oref. На уровне хранения кортежу t соответствует кортеж t' (OIDi, oa, … , OIDref , …) отношения R'ref.
Предлагаемый подход позволяет реализовать принцип целостности ссылок, используя реляционные механизмы обеспечения целостности данных. Для этого поле raref должно быть объявлено как внешний ключ, связанный с полем raOID стержневого отношения R0, что является гарантией того, что объект с идентификатором OIDref не может быть удален, пока в системе существует хоть одна ссылка на него.
Отметим, что информация о связи, являющаяся на уровне представления данных направленной ссылкой (объект oi ссылается на объект oref) на уровне хранения преобразуется в симметричную ассоциацию, представленную в виде пары объектных идентификаторов (OIDi, OIDref), являющихся равнозначными атрибутами кортежа. Это позволяет легко реализовать обращение к данным не только по ссылке (результатом являются объекты, на которые ссылается данный объект), но и в обратном направлении (результатом являются объекты, которые ссылаются на данный объект).
Проектирование схемы данных.
Ортогональные типы.
Как мы сказали, значение объекта является совокупностью значений отношений, принадлежащих множеству
R, а возможность, позволяющая организовать множество {r1,r2….rn} этих значений в виде объекта, не может быть описана в терминах реляционной модели и, следовательно, ортогональна ей. С другой стороны, множество объектов
O можно рассматривать как домен DO, на котором может быть определен атрибут отношения из множества
R.
Тем самым предполагается, что система типов, служащих для описания информация, состоит из двух ортогональных компонент. Каждая из компонент системы типов обладает присущей только ей свойствами, которые не могут быть выражены в ортогональной компоненте. Первая компонента (классы), включая ограниченный набор предопределенных примитивных типов, описывающих объекты системы хранения, может расширяться за счет классов, определяемых пользователем. Вторая компонента состоит из определяемых пользователем отношений. Любой тип, определенный в одной из компонент может рассматриваться в другой компоненте только как базовый тип: любой класс может (примитивный класс должен) являться доменом атрибута отношения, любое отношений определяется нами как реляционный домен (rdom) на котором определен атрибут класса. Следствием этого является то, что, создавая систему, состоящую из множества объектов, принадлежащих определяемым пользователем классам, мы должны описать моделируемые данные одновременно в обеих компонентах, что позволяет предположить, что системе, основанной на предлагаемом подходе, будут присущи свойства как объектных, так и реляционных систем (далее мы это продемонстрируем).
Деление системы типов на две ортогональные компоненты, реализующие разные свойства, может представлять интерес еще и в связи с тем, что схема данных, созданная в такой системе типов, по всей видимости, будет более точно соответствовать моделируемой предметной области, чем аналогичная схема, созданные в терминах, предлагаемых объектно-ориентированным подходом[12]. Очевидно, что эта мысль нуждается в детальном обсуждении, однако, ограничиваясь рамками статьи, мы приведем лишь некоторыми соображениями по этому поводу.
Рассмотрим весьма простую ситуацию. Создавая схему данных, позволяющую описывать предметы, имеющие определенный вес, мы должны определить тип "вес", переменные (возможно сложные) которого будут атрибутами сложных переменных типа "предмет". Предположим, что типы "предмет" и "вес" являются классами, а их переменные объектами. Тогда каждому объекту моделируемой предметной области (т.е. описываемому предмету) в системе хранения будет соответствовать два разных объекта с, соответственно, разными OID: объект класса "предмет" и являющийся его атрибутом объект класса "вес". Адекватна ли эта схема данных описываемой предметной области?
Не вызывает сомнения, что сущность "предмет" должна описываться идентифицируемой переменной. Необходимость идентификации обусловлена тем, тем, что в реальном мире вполне могут существовать два разных предмета, которые на заданном уровне абстракции описываются одинаковой информацией (например, могут существовать два разных предмета имеющие одинаковый вес). Можно утверждать, что для сущности "предмет" объектный идентификатор существенен[11], поскольку именно он идентифицирует эту сущность в рамках информационной системы.
Однако необходимость обязательной уникальной идентификации переменных, содержащих информацию о сущности "вес", выглядит избыточной (повторим, что мы оцениваем соответствие между схемой данных и предметной областью, которая этой схемой описывается). В самом деле, факт, что значения веса описывают разные предметы, выражается уже в том, что переменная типа "вес" является атрибутом разных объектов класса "предмет". Сама же сущность "вес" полностью описывается ее значением, даже если это значение является сложным. В разных объектах системы хранения может храниться информация об одном и том же весе, и то, что информации, описывающей одну и ту же сущность, соответствуют разные OID, не имеет смысла с позиции адекватного представления моделируемой предметной области (хотя не исключено, что это необходимо для функционирования системы). Другими словами, поскольку сущность "вес" полностью идентифицируется собственным значением, объектный идентификатор является несущественным.
Эти рассуждения позволяют предположить, что для описания сущности "вес" необходимо использовать типовая абстракция, которая отличалась бы от абстракции "класс", позволяя выражать существенность явно заданных значений. Этими свойствами обладает абстракция "отношение", которая в рамках нашего построения рассматривается как реляционный домен (rdom), на котором определяются значения атрибутов объекта.
Объектная привязка нормализованной схемы данных.
Целью процесса проектирования является создание схемы данных, описывающей моделируемую область в терминах абстракции, реализуемой используемой системой хранения данных. Предлагаемый подход предполагает использование приемов, использующихся в процессе проектирования как объектно-ориентированных систем, что позволяет достичь присущего объектным системам уровня адекватности представления предметной области, так и реляционных баз данных, что предполагает достаточно высокую степень формализма при проектирования схемы данных.
Будем рассматривать процесс проектирования на примере создания схемы данных, описывающих отгрузки товара со склада. Имеется следующая информация
|
NoS |
Уникальный номер отгрузки |
|
Date |
Дата отгрузки |
|
EmpID |
Идентификатор ответственного сотрудника |
|
EmpName |
Имя сотрудника |
|
GoodsID |
Уникальный артикул товара |
|
СoodsName |
Наименование товара |
|
Pieces |
Количество отгруженного товара (штуки) |
На начальном этапе мы должны
1) определить границы предметной области, выявив в ней возможные классы и объекты, для чего можно использовать существующие методы объектно-ориентированного анализа. В нашем примере такими классами могут быть классы, описывающие товары (cGoods), служащих (cEmployees) и отгрузки (cShipments).
2) нормализовать имеющуюся схему данных. В процессе нормализации мы получили несколько 3НФ отношений (первый столбец содержит имя атрибута, второй – накладываемые на него ограничения)
rStaff (информация о сотрудниках)
|
StaffID |
Primary key |
|
StaffName |
|
rGoods (информация о товарах)
|
GoodsID |
Primary key |
|
GoodsName |
|
rShipments (общие данные об отгрузках)
|
NoS |
Primary key |
|
Sdate |
|
|
StaffID |
|
rShipmentComments (необязательные комментарии об отгрузках)
|
NoS |
Primary key, Foreign key on rShipments.NoS |
|
Comments |
|
rShipmentItems(детальные данные об отгрузках)
|
NoS |
Primary key, Foreign key on rShipments.NoS |
|
GoodsID |
Primary key, Foreign key on rGoods.GoodsID |
|
Pieces |
|
Дальнейшие шаги по созданию схемы данных основаны на выявлении функциональных зависимостей С->R.ra между классами и ключевыми атрибутами отношений, возникших в процессе нормализации данных. Атрибут функционально зависит от класса в том случае, когда каждому объекту этого класса может соответствовать одно единственное значение атрибута. Интуитивно понятно, что подобные зависимости говорят о том, что информация в кортежах, ключи которых зависят от объекта, характеризуют этот объект и, следовательно, должна быть представлена в виде атрибутов этого объекта.
Существование таких зависимостей, однако, позволяет утверждать, что отношения в том виде, в котором они существуют после процедуры нормализации, требуют дальнейших преобразований. Суть проблемы становиться понятной, когда мы рассмотрим отношений R, атрибут rai которого функционально зависит от класса С (каждому объекту класса C соответствует одно значение атрибута rai , С->R.rai). При переходе на уровень представления эта зависимость трансформируется в существующую в соответствующем отношении R' зависимость атрибута rai от системного атрибута raOID, raOID -> rai . И в случае, если атрибут rai входит в состав ключа отношения R, можно утверждать, что соответствующее ему на уровне хранения отношение R' содержит нежелательные функциональные зависимости, что говорит о неоптимальной организации хранящихся данных.
Для оптимизации уровня хранения предлагается процедура объектной привязки, в процессе которой мы изменяем схему отношений, возникших в процессе нормализации данных. В процессе этих изменений мы минимизируем количества ключей и связей, явно задаваемых на уровне представления данных, предполагая, что соответствующие ограничения целостности данных могут реализовываться на уровне хранения О-механизмом, использующим, в частности, связанное со стержневым отношением системное поле raOID.
Описывающая предметную область схема данных, возникшая в результате объектной привязки, будет представлять собой набор классов и свойств. Заметим, что с формальной стороны "свойства" определяют существование реляционных доменов (rdom), то есть отношений. Значение "свойства" представляет собой кортеж отношения, а множество таких значений (возможно пустое или единичное), является значением отношения.
Окончательная структура данных, которая возникнет в процессе объектной привязки, выйдет за рамки реляционной модели данных (собственно, это и является целью наших построений). Однако крайне важно понимать, что структура и свойств и классов полностью определяется структурой отношений, возникших в процессе нормализации и, в свою очередь полностью определяет структуру отношений, существующих на уровне хранения. В свете этого, термины "класс" и "свойство" по сути дела вводят на уровне хранения определенные ограничения целостности данных.
Объектная привязка использует нескольких простых правил. Основное правило звучит так: если ключ отношения, возникшего в результате нормализации, полностью зависит от класса, то схема этого отношение может определять структуру объектов этого класса. Можно выделить случай, когда ключ, полностью зависящий от класса, не является внешним ключом, и не содержит поля, являющиеся внешними ключами. Будем называть такое отношение сильным (другие отношения, соответственно, являются слабыми). В качестве примера можно рассмотреть функциональную зависимоcть, сушествующую между классом cStaff и полем StaffID отношения rStaff (служащему присвоен номер).
На уровне хранения в отношении rStaff' (raOID, StaffID, StaffName) присутствует транзитивная зависимость raOID -> StaffID, StaffID -> StaffName.С другой стороны, поскольку StaffID является ключом (служащему присвоен уникальный номер), можно утверждать, что существует обратная зависимость StaffID -> raOID. По сути дела поле StaffID можно рассматривать как явно заданный ключ класса cStaff (не путать с OID!).
Обратим внимание на то, что в случае, когда ключ отношения R полностью зависит от класса, каждому объекту этого класса соответствует в точности один кортеж отношения R (служащему не может соответствовать несколько номеров). Таким образом, если рассматривать сильное отношение R как реляционный домен, на котором определены значения атрибутов класса, можно утверждать, что эти значения не могут быть группой повторения.
Учитывая то, что каждому объекту класса соответствует в точности один кортеж сильного отношения, схема сильного отношения должна использоваться как основа для описания схемы соответствующего класса (но только как основа – полная структура класса может быть гораздо сложнее, чем схема соответствующего ему сильного отношения). В нашем примере отношение rStaff является основой для класса cStaff, который может быть описан следующим образом
CLASS cStaff{
StaffID AS INT GLOBAL UNIQUE;
StaffName AS STRING;
}
Тем самым неявно определено свойство одноименное классу и являющее для этого класса главным, корневым. Модификатор GLOBAL UNIQUE, определяющий уникальность значение поля StaffID в объектах класса cStaff, позволяет рассматривать это поле как явно заданный ключ класса cStaff. Существование этого ключа определяется тем, что поле StaffID является ключом сильного отношения. Такому описанию класса (и корневого свойства) на уровне хранение будет соответствовать следующее отношение rStaff'
|
r aOID |
Primary key, Foreign key on R0. raOID |
|
r aoa |
|
|
r StaffID |
Unique |
|
r StaffName |
|
Аналогичные рассуждения верны для отношений rGoods, которое является основой для класса cStaff. со следующей схемой
CLASS cGoods{
GoodsID AS INT GLOBAL UNIQUE;
GoodsName AS STRING;
}
который будет представлен на уровне хранения отношением
rGoods'
|
r aOID |
Primary key, Foreign key on R0. raOID |
|
r aoa |
|
|
r GoodsID |
Unique |
|
r GoodsName |
|
Схема же класса, базирующегося на сильном отношении rShipments, будет гораздо сложнее схемы этого отношения. Конечно, отношение rShipments является основой схемы класса и определяет существование неявно заданного корневого свойства одноименного этому классу. Однако, и это следует из основного правила, схема отношение rShipmentComments также может определять структуру объектов класса cShipments. В данном случае полностью зависящий от класса ключ отношения является к тому же и внешним ключом. Атрибут, определенный на таком отношении, не может являться повторяющейся группой и не должен содержать более одного кортежа.
Этот случай подразумевает, что в множестве отношений, возникших после нормализации, для этого класса уже существует сильное отношение. В нашем примере атрибут NoS отношения rShipmentComments является внешним ключом, явно связывающим это отношение с первичным ключом отношения rShipments. Принимая во внимание, что отношение rShipmentComments описывает те же объекты, что и отношение rShipment, можно утверждать, что явно заданная связь rShipments.NoS <-> rShipmentComments.NoS при переходе на уровень хранения станет избыточной (избыточной в объекте), поскольку она будет дублироваться связью rShipment'. raOID <-> R0'. raOID <-> rShipmentComments'. raOID между системными атрибутами raOID стержневого отношения R0' и отношений rShipmentComments' и rShipment'. Последняя связь является системной. Она существует только на уровне хранения, на уровне же представления она задается тем, что отношения rShipment и rShipmentComments определяются как отношения, описывающие объекты одного и того же класса. Следовательно, если поля (поле) слабого отношения, описывающего некоторый класс, являются внешним ключом, связанным с ключом сильного отношения, описывающего тот же класс, то эти поля (поле) должны должно быть исключено из схемы свойства, основанного на этом отношении.
Таким образом, для оптимальной организации уровня хранения следует изменить схему отношения rShipmentComments, исключив из него атрибут NoS. Результатом этого станет свойство
PROPERTY pShipmentComments{
Comments AS STRING;
}
которое должно рассматриваться как домен атрибута класса. На уровне хранения этому свойству будет соответствовать отношение
rShipmentComments'
|
r aOID |
Primary key, Foreign key on R0. raOID |
|
r aoa |
|
|
r Comment |
|
Существуют другой случай, когда явно задаваемая связь является избыточной в объекте. Рассмотрим случай, когда ключ частично зависит от класса (т.е. от класса зависят не все поля, входящие в ключ). Будет утверждать, что в том случае, если ключ отношения, возникшего в результате нормализации, частично зависит от класса, то схема это отношение также может определять структуру объектов этого класса (подразумевается, что схема отношения, ключ которого частично зависит от класса, может и не определять структуру этого класса).
В качестве примера рассмотрим отношение rShipmentItems. Первичный ключ этого отношения входят два поля, одно из которых, NoS, зависит от класса cShipments, а другое, CoodsID – от класса cGoogs. Исходя из только что сформулированного принципа, мы должны выбрать класс, схему которого должно определять рассматриваемое отношение. Целью этого выбора является адекватное представление сущностей реального мира. В нашем случае естественно предположить (поскольку мы говорим про данные, означенные как "элемент отгрузки") что схема отношение rShipmentItems должна послужить основой для определения структуры класса cShipments.
Из этого следует, что связь rShipments.NoS <->rShipmentItems.NoS является избыточной в объекте. Для оптимальной организации уровня хранения следует изменить схему отношения rShipmentItems, исключив из него атрибут NoS. Однако это изменение не будет единственным.
Поле GoodsID отношения rShipmentItems связано с первичным ключом возникшего в результате нормализации отношения rGoogs. В процессе анализа мы пришли к выводу, что rGoogs является сильным отношением, определяющем класс сGoogs. Однако, поскольку отношения rShipmentItems и rGoogs описывают объекты разных классов, эта связь не является избыточной в объекте.
В таком случае процедура объектной привязки предполагает, что если поля (поле) слабого отношения, описывающего некоторый класс, являются внешним ключом, связанным с ключом сильного отношения, описывающего другой класс, то эти поля (поле) должны быть заменены ссылкой на класс сильного отношения. Возможность такой замены обусловлено тем, что между множеством значений ключа сильного отношения и множеством уникальных идентификаторов объектов класса этого отношения, существует взаимно-однозначное соответствие. Значение явно заданного поля GoodsID (ключ класса) в объектах класса cGoods точно так же уникально, как и скрытое значение уникального объектного идентификатора и, следовательно, поле rShipmentItems.GoodsID должно быть заменено ссылкой на класс cGoods (то же самое относится и к полю StaffID отношения rShipment, которое должно быть заменено на ссылку на класс cStaff ).
Учитывая сказанное, схема отношения rShipmentItems преобразуется в следующую схему свойства ShipmentItems
PROPERTY pShipmentItems{
Good As cGoods UNIQUE;
Pieces AS INT;
}
Модификатор UNIQUE определяет, что поле Good будет уникальным в группе повторения. Поскольку группа повторения свойства представляет собой значение отношения, указанный модификатор фактически определяет первичный ключа атрибута объекта. Существование такого первичного ключа следует из того, что поле rShipmentItems.GoodsID входит в состав первичного ключа отношения rShipmentItems, схема которого послужила основой схемы свойства pShipmentItems. Наличие первичного ключа в свойстве определяет, что значения этого свойства могут образовывать группу повторения, элементы которой (кортежи) должны содержать ссылки на различные объекты класса cGoods. Под "различными" здесь подразумеваются объекты, имеющие разные OID (можно предположить, что возможно переопределение операции сравнения, применимой к объектам данного класса). Свойству ShipmentItems на уровне хранения будет соответствовать отношение rShipmentItems' (отметим наличие симметричной ассоциации (raOID, …, rGoodsref, …) )
rShipmentItems'
|
r aOID |
Primary key, Foreign key on R0. raOID |
|
r aoa |
|
|
r Goodsref |
Primary key, Foreign key on R0. raOID |
|
r Pieces |
|
С учетом всего вышесказанного схема класса cShipments на уровне представления будет выглядеть следующим образом
Class cShipment{
NoS AS LONG GLOBAL UNIQUE;
SDate As DATE;
Staff AS cStaff;
ShipmentItems AS SET OF pShipmentItems;
Comment pShipmentComments;
}
Поля NoS, SDate и Staff являются полями неявно заданного корневого свойства класса cShipment. На уровне представления ему будет соответствовать отношение.
rShipments'
|
r aOID |
Primary key, Foreign key on R0. raOID |
|
r aoa |
|
|
NoS |
UNIQUE |
|
r SDate |
|
|
r Staffref |
Foreign key on R0. raOID |
Таким образом, на уровне хранения объект класса cShipment будет представлен одним кортежем отношения rShipments' (обязательно), одним кортежем отношения rShipmentComments' (возможно), и множеством (возможно пустым) уникальных кортежей отношения rShipmentItems', причем все указанные кортежи будут связаны системным полем raOID с одноименным полем стержневого отношения R0, содержащим уникальный идентификатор этого объекта.
Еще раз подчеркнем, что схема данных, возникающая в процессе объектной привязки, определяется как анализом предметной области, так и множеством отношений, возникших в результате нормализации описывающих ее данных. В качестве иллюстрации к этой мысли рассмотрим еще один случай, когда атрибуты, входящие в ключ отношения и зависящие от класса, не являются внешним ключом. Продолжая наш пример, создадим схему данных, описывающих поставки товара на склад. Предположим, что в результате нормализации данных мы получили следующее простое отношение
rSupplyItems
|
SupplyDate |
Primary key |
Дата поставки |
|
GoodsID |
Primary key, Foreign key on rGoods.GoodsID |
Уникальный артикул товара |
|
Pieces |
|
Штуки, поставленные за день |
Первичный ключ этого отношения содержит поле GoodsID а, следовательно, это можно было бы предполагать, что это отношение должно определять структуру класса сGoods. Следуя этому предположению, мы должны создать свойство
PROPERTY pGoodsSupply{
SupplyDate As DATE UNIQUE;
Pieces AS INT;
}
которое в дальнейшем будет рассматриваться как домен (rdom) входящего в класс cGoods атрибута, который содержит информацию о поставках описываемого этим классом товара.
Однако предположим, что анализ предметной области показал необходимость создать класс cSuppliesPerDate, описывающий поставки товара за день. Следуя этому определению, можно говорить о существовании зависимости cSuppliesPerDate ->rSupplyItems.SupplyDate. Зависимый атрибут SupplyDate не является внешним ключом (хотя и входит в его состав). Отношение, являющееся сильным для класса cDaySupply, отсутствует. В таких случай процедура объектной привязки предполагает, что зависящие от класса поля, не являющиеся ни первичным, ни внешним ключом, должны быть выделены в отдельное отношения, которое и станет сильным для этого класса. В нашем случае схем должна быть изменена следующим образом
rSupplyDates
rSupplyItems
|
SupplyDate |
Primary key, Foreign key on rSupplyDates. SupplyDate |
|
GoodsID |
Primary key, Foreign key on rGoods.GoodsID |
|
Pieces |
|
Далее мы действуем ранее описанным способом. Поскольку связь rSupplyItems.SupplyDate -> rSupplyDates.SupplyDate является избыточной в объекте, а поле GoodsID является внешним ключом, связанным с отношением, относящимся к другому классу, окончательная схема данных, описывающая поставки должна выглядеть следующим образом
PROPERTY pSupplyItems{
Good As cGoods UNIQUE;
Pieces AS INT;
}
CLASS cSuppliesPerDate {
SupplyDate AS DATE GLOBAL UNIQUE;
SupplyItems AS SET OF pSupplyItems;
}
Итак, процедура объектной привязки выполняется на основании следующих правил (порядок нестрогий). Если зависимые от класса Сi атрибуты ra отношения Rk
1) являются ключом и не являются внешним ключом, то отношение Rk является сильным и его схема может служить основой для структуры класса Сi.
2) являются внешним ключом и определяют связь с отношением описывающим…
… тот же класс Ci , то эта связь является избыточной в объекте класса Ci, поэтому атрибуты ra надо исключить из схемы Rk
… другой класс Cj , то речь идет о связи между объектами классов Ci и Cj, поэтому атрибуты ra надо заменить ссылкой на класс Cj
3) не являются ни первичным, ни внешним ключом (класс Сi не имеет сильного отношения), то атрибуты ra могут быть вычленены в отдельное отношение, являющееся для класса Ci сильным (далее как в 2).
Схема данных, возникшая в процессе объектной привязки, еще не является окончательной. Обратим внимание на то, что схема свойств pSupplyItems и pShipmentItems являются абсолютно идентичными. Этот факт соответствует мысли, что информация, описываемая этими свойствами, имеет в общем-то одинаковый смысл, а именно "количество товара". Поэтому они могут быть заменены общим свойством pGoodsItems. Соответствующее этому свойству отношение уровня хранения
rGoodsItems'
|
r aOID |
Primary key, Foreign key on R0. raOID |
|
r aoa |
|
|
r Goodsref |
Primary key, Foreign key on R0. raOID |
|
r Pieces |
|
будет содержать детальные данные и по отгрузкам и по поставкам. Смысловая разница между ними будет обуславливаться значением атрибута raoa: данным об отгрузках будет соответствовать атрибут ShipmentItems класса cShipments, а данным о поставках – атрибут SupplyItems класса cSuppliesPerDate. С учетом этого изменения схема данных должна будет выглядеть следующим образом.
CLASS cStaff
StaffID AS INT GLOBAL UNIQUE;
StaffName AS STRING;
GoodsID AS INT GLOBAL UNIQUE;
GoodsName AS STRING;
}
PROPERTY pShipmentComments{
Comments AS STRING;
}
PROPERTY pGoodsItems {
Good As cGoods PRIMARY KEY;
Pieces AS INT;
}
CLASS cShipments{
NoS AS LONG GLOBAL UNIQUE;
SDate As DATE;
Staff AS cStaff;
ShipmentItems AS SET OF pGoodsItems;
Comment AS pShipmentComments;
}
CLASS cSuppliesPerDate{
SupplyDate AS DATE GLOBAL UNIQUE;
SupplyItems AS SET OF pGoodsItems;
}
В дальнейшем эта схема будет использоваться в примерах, демонстрирующих возможностей подхода. Оговоримся, что описание управляющего языка не является целью данной статьи. Стремясь сделать примеры наглядными, мы не использовали синтаксис какого-либо конкретного языка программирования: конструкции связанные с объектами близки объектным языкам, синтаксис языка запросов близок к SQL, хотя нельзя не отметить, что возможностей последнего явно недостаточно для того, что бы обращаться к сложно организованным данным.
Свойства системы.
Групповые операции. Ненавигационный доступ к данным.
Рассмотрим класс С со схемой (oa1:R1, …, oan:Rn) содержащий объекты {o1 , … ,om}. Предположим, что существует реляционный оператор
calcR = E( R1, … , Rn), <11>
где Ri – отношения (rdom), на которых определены атрибуты объектов класса С,
calcR - отношение (rdom), на котором определен результат. Применим оператор E к объекту oi класса С и рассмотрим выражение oi.E(oa1, … , oan), которое, исходя из значений атрибутов {oa1, … , oan} этого объекта, вычисляет некоторое значение
calcr
calcri = oi.E(oa1, … , oan)
<12>
Как мы уже показали, атрибут oa объекта o на уровне
хранения представлен как
s(raOID= OID, raoa = oa)(R') , где R' = rstorage(oa),
<13>
или
s(raOID= OID)(A), где A =
s(raoa = oa)(R').
<13'>
В последнем случае мы рассматриваем подмножество A отношения R', содержащее все значения атрибута oa всех объектов класса с. Исходя из этого,
перепишем правую часть выражение <12> как
oi.E(oa1, … , oan)
OєR'
E( s(raOID=
OIDi)(A1), … , s(raOID=
OIDi)(An))
<14>
Для перечисленных далее операторов реляционной алгебры[8,10] справедливы следующие равенства:
-для объединения
s( raOID= OID)(Ak)
И s( raOID= OID)(Am) =
s( raOID= OID)(Ak И Am),
-для пересечения
s( raOID= OID)(Ak)
З s( raOID= OID)(Am) =
s( raOID= OID)(Ak З Am),
-для декартова произведения
s( raOID= OID)(Ak)
ґ s( raOID= OID)(Am) =
s( raOID= OID)(Ak ><( raOID)
Am),
-для вычитания
s( raOID= OID)(Ak) - s( raOID= OID)(Am) =
s( raOID= OID)(Ak - Am),
-для проекции
p(rai) (s( raOID= OID)Ak) ) =
s( raOID= OID)(
p(rai) (Ak) ),
-для выборки
s(q)(
s( raOID= OID)(Ak)) =
s( raOID= OID)(
s(q)(Ak) ), где
q - предикат ,
-для соединения
s( raOID= OID)(Ak) ><F
s( raOID= OID)(Am) =
s( raOID= OID)(Ak ><(raOID and F) Am), где F – предикат,
-для деления
s( raOID= OID)(Ak)
ё s( raOID= OID)(Am) =
s( raOID=
OID)(Ak ё Am).
Исходя из этого, можно утверждать, что для любого выражения E (уровень представления данных) найдется такое выражение E' (уровень хранения данных), что
oi.E(oa1, … , oan)
OєR' s(
raOID= OIDi)( E' (A1, … , An))
<15>
Рассмотрим объединение результатов применение оператора E к объектам из множества gC = {o1 , … ,ok} , gC Н С
o1.E(oa1, … , oan)
И … И ok.E(oa1, … , oan)
OєR'
s(
raOID= OID1)( E' (A1, … , An))
И … И s(
raOID= OIDk) ( E' (A1, … , An))
<16>
из чего следует, что
o1.E(oa1, … , oan)
И … И ok.E(oa1, … , oan)
OєR' s(raOID
О {OID1, … , OIDk}) ( E' (A1, … , An))
<17>
Это позволяет утверждать, что реляционный оператор E применим и к множеству gC объектов класса С
gC.E(oa1, … , oan). <18>
Рассмотрим класс C ={o1 , … ,om} со схемой (oa1:R1, …, oan:Rn) целиком. Поскольку речь идет о всех объектах, входящих в класс, можно утверждать, что множество их идентификаторов {OID1, … , OIDm} равно множеству
p(raOID) Ai для любого атрибута oai класса C ( Ai =
s(
raOID= OIDi)(R'), где R' = rstorage(oai), oai
О Schema(С). Исходя из этого, можно показать, что
С.E(oa1, … , oan)
OєR' E' (A1, … , An)
<19>
Таким образом, предлагаемый подход допускает использование основанных на реляционной алгебре групповых операций, которые могут применяться к множествам объектов одного класса. Важнейшим следствием этого является то, что классы можно рассматривать как интенсиональные множества [1] объектов, причем принадлежность объектов к этим множествам однозначно определяется уже в момент создания объекта.
Это свойство важно по нескольким причинам. Очевидно, что оно делает необязательным использование разного рода коллекций, наборов и т.п. объектов, предназначенных для явного (т.е. требующего каких-либо действий со стороны программиста) задания множеств объектов, а также итераторов, служащих для последовательного просмотра этих множеств. Не столь очевиден, но ничуть не менее важен тот факт, что ссылки перестают быть единственным способом доступа к данным, хранящимся в объекте.
Последнее утверждение требует некоторого разъяснения. В традиционных объектных системах единственным средством доступа к данным, представленным в виде объектов данных, является использование ссылки на эти объекты - такой способ доступа называется навигационным. Как только утеряна ссылка, то утерян и объект. Система хранения данных, основанная на этом принципе, должна хранить не только объекты, но и (в том или ином виде) ссылки на эти объекты, с момента их создания до момента уничтожения. Поскольку
такие ссылки (в отличии от ссылок,
описывающих связи между объектами
моделируемой предметной области) не несут какой-либо полезной информации, такую систему охарактеризовать как избыточную, и, как следствие, более сложную в управлении и использовании.
Предлагаемая альтернатива основана на том, что на уровне хранения информация об объектных идентификаторах существует точно в таком же виде, как и информация о собственных значениях этих объектов, а именно в виде явно заданных значений атрибутов кортежей отношений. В самом деле, любое отношения Ai ( Ai = (
s(
raOID= OIDi) (R'), где R' = rstorage(oa)) входящее в состав выражения E' (…,Ai ,…) содержит атрибут raOID определенный на домене DOID и, следовательно, указанный атрибут может являться атрибутом отношения, являющегося результатом вычисление выражения E'. Рассмотрим оператор E' (A1, … , An), результатом которой является отношение calcR' со схемой {… , raOID : DOID, …}. Поскольку значения атрибута raOID любого из исходных отношений Ai ограничены классом C, в котором определен атрибут ai, а также с учетом взаимно-однозначного соответствия
OID « O, можно предполагать, что результатом соответствующей ей на уровне представления операции E(С) будет являться отношение calcR со схемой {… , rao : C, …}.
Это позволяет утверждать, что на уровне представления возможна такая операция над классом, что ее результатом будет подмножество удовлетворяющих определенному условию объектов этого класса, или значение (значение отношения), содержащее информацию об объектах из этого подмножества. Таким образом, в предлагаемом подходе вместе с навигацией по ссылкам возможен и ненавигационный доступ к объектам и к данным, хранящихся в этих объектах.
Примером может служить запрос, который будет возвращать количество товара, отгруженного сотрудником сегодня
SELECT Sum(ShipmetItems.Pieces)
FROM cShipment
WHERE cShipment.Date = Today() <П.1>
Групповые операции над ссылками.
Поскольку отношение Rref'(см. раздел "Ссылки") содержит значения всех определенных на реляционном домене Rref атрибутов всех существующих в системе объектов, можно утверждать, что это отношение R' содержит все пары (OIDi OIDref) описываемые ссылкой oa.raref. Это позволяет говорить о возможности групповых операций над ссылками. Рассмотрим множество gс = (o1 , … ,on) объектов класса c, содержащего атрибут oa определенный на ранее описанном реляционном домене Rref. Можно говорить о том, что на уровне представления данных возможна операция
gref = p(raref)(gc.oa.raref)
<20>
которая возвращает множество объектов gref, на которые ссылаются объекты, входящие в множество gc. На уровне хранения она будет реализовываться следующим образом
p(raref)(gc.oa.raref)
OєR p(raref) (
s(raOID О
{OID1, … ,OIDn}, raoa = oa)(R')) , где R' = rstorage(oa)
<21>
Так же возможна операция, разрешающая обратную ссылку. Например, для объекта oref можно найти множество gbackref объектов класса c, которые ссылаются на него по ссылке oa.raref:
gbackref = p(с) (s(raref = oref)(с.oa.raref))
<22>
На уровне хранения данной операции соответствует следующее выражение:
p(с) (s(raref = oref)(с.oa.raref)) OєR
p(raOID) ( s(raref = OIDrefi, raoa = oa)(R')), где
R' = rstorage(oa) <23>
Примером может служить запрос, который будет возвращать количество товара, отгруженного сотрудником с именем Вася Петров
SELECT Sum(ShipmetItems.Pieces)
FROM cShipment
WHERE cShipment.Staff.StaffName = ' Вася Петров ' <П.2>
Вычисляемые атрибуты объектов. Инкапсуляция.
Рассматривая атрибут oa объекта oi, до сих пор мы предполагали, что на уровне хранения он представлен как подмножество кортежей отношения R', oi.oa
OєR' s(raOID= OIDi, raoa = oa)
(R') где R' = rstorage(oa). Будем называть такой атрибут хранимым. Однако возможен и другой случай, когда значение атрибута объекта вычисляется исходя из значений других атрибутов данного объекта. Будем называть такие атрибуты вычисляемыми.
Рассмотрим реляционный оператор Ea
R1 = Ea( R2, … , Rn),
где Ri – отношения, являющиеся реляционными доменами (rdom), на которых определены атрибуты объектов класса С. Применим оператор E к объекту oi класса С и рассмотрим выражение
oi. oa1 = oi.E(oa2, … , oan),
которое, исходя из значений атрибутов oa2, … , oan, вычисляет значение атрибута a1.
Применяя уже использованные преобразования, можно показать, что при переходе на уровень хранения это выражение может быть представлено как
o. oa1 = oi.E(oa2, … , oan)
OєR' s(raOID= OIDi)( E'a (A2, … , An))
ґ {a1}
<24>
, где {a1} - 1-арное отношение, единственный кортеж которого содержит имя вычисляемого атрибута { a1 }. Рассмотрим класс C и значение C.a1 = {o1. oa1
И … И ok.a1}. Можно показать, что
С. oa1 OєR' A1 , A1 = E'a (A2, … , An)
ґ {a1}
<25>
Выражение Ea , вычисляющее значение атрибута, должно входить в метаданные, описывающие структуру объекта. Таким образом, схема S содержащего вычисляемые атрибуты объекта класса С
(S = Schema(C) ), будет выглядеть следующим образом:
S = {oa1:R1:Ea (oa2, … , oan), oa2:R2,…, oan:Rn}
<26>
Интересно то, что, благодаря замкнутости реляционной алгебры (результатом любого алгебраического выражения над множеством отношений является отношение), вычисляемые атрибуты могут являться атрибутами в реляционных операциях над объектами наравне с хранимыми. Корректность выражения
calcri =С.E(oa1, … , oan)
OєR' E' (A1 , … , An)
<27>
зависит исключительно от типов (rdom) использующихся в ней атрибутов ai, и не зависит от того, является эти атрибуты хранимыми или вычисляемыми. Оператор Е может быть определен на основании схемы
publicS = {oa1:R1, oa2:R2,…, oan:Rn}, которую можно рассматривать как спецификацию схемы объектов класса С. Информация же об ассоциированных с атрибутами операторах Еа, служащих для вычисления значений этих атрибутов, не является необходимой для использования объектов класса С (естественно, речь идет об использовании в операциях, основанных на реляционной алгебре), и, фактически, описывает некоторую реализацию схемы объектов класса . Это позволяет утверждать, что предлагаемый подход позволяет реализовать принцип инкапсуляции [4,1] - один из основных принципов объектно-ориентированного программирования, предполагающий разделения спецификации и реализации объекта.
Наследование.
Еще одним важным принципом, составляющим объектно-ориентированную парадигму, является принцип наследования [4], позволяющий определять новые классы на основе уже существующих. Отношение между классами, возникающее в процессе наследования, описывают существующую между ними связь "обобщение-специализация", причем класс-наследник является специализацией родительского класса, который, в свою очередь, обобщает все свои классы-наследники.
Рассмотрим класс С со спецификацией
publicSC = {oa1:R1, oa2:R2,…, oan:Rn}. Предположим, что для этого класса определен реляционный оператор E
С.E(oa1, … , oan)
Рассмотрим класс Сi, являющийся наследником класса
C. Спецификация класса Сi определяется как publicSCi = SC
И {oan+1:Rn+1,…, oap:Rp } = {oa1:R1, oa2:R2,…, oan:Rn, oan+1:Rn+1,…, oap:Rp }. Поскольку объекты класса Ci содержат те же атрибуты, определенные на тех же реляционных доменах
(rdom), что и в объекты класса С, то можно утверждать, что оператор Е применим и к объектам любых классов Ci являющихся наследниками класса
C. Это позволяет рассматривать объекты классов-наследников как объекты родительского класса С.
В свете этого имеет смысл более подробно рассмотреть отношения, существующих между множеством
O объектов и множеством C классов. Можно выделить два типа отношений. Первое, традиционно обозначаемое как отношение
ISA, характеризуется фразой "объект oi является объектом класса
C". Эта связь учитывает существующую между классами связь "обобщение-специализация", которая определяет иерархию наследования. Отношение ISA описывает связь типа "многие ко многим" – один класс может содержать множество объектов и, поскольку объекты класса-наследника считаются объектами родительского класса, одному объекту может соответствовать несколько классов. Если объект oi связан с классом C связью
ISA, можно утверждать, что спецификация этого объекта содержит атрибуты, определенные в спецификации класса, ISA
(oi,C) => publicSchema(C) Н
publicoSchema
(oi)
Второе отношение, которое в
дальнейшем мы будем обозначать как
отношение OFA, описывает связь,
характеризующуюся фразой "объект oi
создан как объект класса C". Эта связь не
учитывает наследования и является связью
типа "многие к одному", из чего следует,
что отношение OFA является функциональным, O
–OFA-> C.
Для объектов и связанных с ними связью OFA
классов существует точное соответствие
схемы объекта и схемы класса, OFA (oi,C)
=> oSchema (oi) = Schema(C).Обратное отношение
OFA-1 ,для каждого класса C будет
формировать множество объектов DC,
созданных как объекты класса C,
DC = OFA-1(C). Заметим, что
множества объектов DC
являются непересекающимися DCi
З DCi
= Ж если Сi №
Сj.
Рассмотрим множество IC0
классов Сi содержащий атрибут
oa, oa О publicSchema
(Ci). Эти классы образуют иерархию
наследования, где и один из них - класс С0
, в котором атрибут oa объявлен впервые
- является родительским для остальных
классов Ci (i > 0), наследующих этот
атрибут. Множество объектов, входящих в
класс С0, является объединением всех
объектов, созданных как объекты классов,
входящих в иерархию IC0,
C0 = И DCi
, где Ci О IC0.
Таким образом, значение C0.oa,
представляющее собой объединение значений
атрибутов oa объектов, принадлежащих
классу C0, является объединением
значений DCi
. oa,
представляющих собой объединения значений
атрибутов oa объектов, созданных как
объекты класса, входящих в иерархию I, С0.oa
= 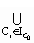 DCi
. oa, где DCi
. oa = DCi
. oa, где DCi
. oa = 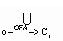 o.oa. o.oa.
Переопределение атрибутов.
Значение вычисляемого атрибута oa
определяется оператором Ea,
ассоциированным с этой переменной.
Поскольку этот оператор определен только в
реализации схемы объектов класса C, можно
предположить, что он может
переопределяться в процессе наследования.
Отметим, что переопределение,
подразумевающее изменение реализации
схемы объектов при неизменной спецификации,
является одним из способов создания
полиморфных[4] систем.
Рассмотрим класс С0 со
схемой SC0 =
{oa1: R1: C0Ea
, oa2:R2,…, oan:Rn}.
Атрибут oa1 вычисляется исходя
из значений других атрибутов выражением C0Ea,
oa1 = C0Ea
(oa2, … , oan).
Предположим, что для этого класса определен
реляционный оператор E
С0.E(oa1, … , oan)
Рассмотрим иерархию IC0
и входящие в нее классы Сi (i >
0), которые являются наследником класса C0
и имеют схему SCi =
{ oa1:R1:CiEa,
oa2:R2,…, oan:Rn,
oa2:R2,…, oan:Rn,
oan+1:Rn+1,…, oap:Rp
}. В процессе наследования, выражение,
вычисляющее значение атрибута oa1,
может быть переопределено, причем, возможно,
оно будет учитывать значения атрибутов oan+1,…,
oap, отсутствующих в
родительском класса C0
oa1 = CiEa
(oa2, … , oap).
Рассмотрим значение С0.oa1
представляющее собой объединение значений
атрибутов oa1 объектов класса С0,
o О C0
С0.oa1 =
DCi .
oa1 , где DCi.oa
=
o.oa.
<28>
Как мы ранее показывали, значение
переопределяемого атрибута oa объекта
ok любого из классов Ci на уровне
хранения будет вычисляться следующим
выражением
ok.oa1 = ok.
CiE(oa2,
… , oa n, …) OєR'
s(raOID=
OIDk) (CiE'a
(A2, … , An, … )) ґ
{a1}
<29>
Выражение, объединяющее значения
атрибутов oa всех объектов, созданных
как объекты класса Сi, будет выглядеть
как
DCi oa1 =
DCi .
CiE(oa2,
… , oa n, …) OєR'
s(raOID
OFA Ci )( CiE'a
(A2, … , A n, …)) ґ
{a1}
<30>
(реализация предикатов OFA и ISA на
уровне хранения будет рассмотрена далее –
см. "Связь данных и метаданных").
Следовательно, значение С0.oa1
представляющее собой объединение значений
атрибутов oa1 полиморфных
объектов класса С0, на уровне хранения
будет вычисляться как
C0.a1 OєR'
(s(raOID
OFA Ci )( CiE'a
(A2, … , A n, …)) ) ґ
{a1}
<31>
Случай, когда переопределяемый
атрибут a1 в процессе наследования
становиться или, наоборот, перестает быть
хранимым, выглядит немного сложнее:
C0.a1 OєR'
( (s(raOID
OFA Ci )( CiE'a
(A2, … , A n, …)) ) ґ
{a1} ) И A1
<32>
Отметим, что в любом случае
вычисляющее выражение не выходит за рамки
реляционной алгебры.
Возможность переопределение атрибутов заслуживает внимания, поскольку позволяет создавать гибкие расширяемые системы. Рассмотрим групповой реляционный оператор С0.E(oa1, … , oan), который может применяться к множеству объектов класса C0. Принимая во внимание тот факт, что он определен на основании спецификации схемы объектов этого класса, можно утверждать, что его можно применять к объектам, принадлежащим любым классам Ci, наследующим класс С0, в том числе и классам с переопределенными атрибутами.
Вернемся к примеру. Предположим, что наряду с отгрузками склад стал заниматься продажами товар. В связи с этим создадим класс cSales, объекты которого описывают продажи. Поскольку продажа подразумевает отгрузку, естественно предполагать, что этот класс должен рассматриваться как наследник класса cShipment. В процессе проектирования схемы данных было выделено свойство(rdom) pSalesGoods, значения которого содержат информацию о количестве и цене продаваемого товара.
PROPERTY pSaledGoods{
Good As cGoods PRIMARY KEY;
Price As DOUBLE;
Pieces AS INT;
}
С учетом всего сказанного, схема класса cSales должна содержать выражение, переопределяющее описанный в классе cShipment аргумент ShipmentItems таким образом, что бы он вычислялся на основании данных о продажах, хранящихся в атрибуте, определенным на свойстве pSaledGoods
CLASS cSales EXTENDS cShipment {
…;
SalesItems AS pSaledItems; //Теперь данные хранятся здесь.
REDEFINE ShipmentItems //Этот аргумент вычисляется на основании данных…
AS SELECT Good, Pieces FROM SalesItems; // …хранящихся в SalesItems.
…;
} <П.4>
Поскольку такая схема реализует спецификацию класса cShipment, можно утверждать, что объекты класса cSales являются один из вариантов объектов полиморфного класса cShipment. Особо отметим, что созданные ранее (см. <П.1> и <П.2>) запросы, возвращающие информацию об отгруженном товаре, останутся корректными, и по-прежнему будут возвращать информацию обо всем отгруженном товаре, включая информацию о товаре, отгруженном в рамках продаж.
Метаданные.
Схема данных, описывающая предметную область в терминах классов и свойств, определяет существование множества
C классов, множества
oa их атрибутов, множества
R отношений (свойств), являющихся реляционными доменами этих атрибутов, а также ряда отношений между указанными множествами. Совокупность перечисленных множеств и отношений представляет собой метаданные (данные о данных), позволяющие представить данные, хранящиеся в терминальном механизме хранения данных (реляционное ОЗУ), в терминах используемой абстракции (свойства и классы).
Предполагая, что единственно возможный терминальный механизм хранения данных основан на реляционной модели данных, можно утверждать, что и сами метаданные должны храниться в виде набора отношений, совокупность которых образует каталог системы. Таким образом, перманентное реляционное ОЗУ используется для совместного хранения данных и метаданных,
Каталог.
Следующие отношения образуют структуру каталога (первый столбец содержит имя атрибута, второй – накладываемые на него ограничения):
1)RDOMENSs - перечисляет существующие реляционные домены - отношения из множества
R (rdom)
|
IDR |
Primary key |
Уникальный идентификатор реляционного домена. |
Для любого реляционного домена R, отношение RDOMENSs должно содержать единственный кортеж, ключевое поле IDR которого содержит значение idR , идентифицирующее этот домен.
Ограничившись отношением, перечисляющим реляционные домены R, мы не будем останавливаться на подробном описании их структуры. Отметим, что это описание однозначно соответствует хранящемуся в каталоге базовой реляционной системы хранения данных описанию существующего на уровне хранения отношения
R'.
2) CLASSES - перечисляет существующие классы.
|
IDC |
Primary key |
Уникальный идентификатор класса (например имя класса). |
Для любого класса С, отношение CLASSES должно содержать единственный кортеж, поле IDC которого содержит значение idC , идентифицирующее этот класс.
3) ISA – определяет отношение ISA, существующее между классами (множествами объектов)
|
IDC |
Primary key, Foreign key on CLASSES.IDC |
Идентификатор класса. |
|
ISAС |
Primary key, Foreign key on CLASSES.IDC |
Идентификатор класса с которым класс IDC связан отношением ISA. |
Это отношение содержит информацию о классах, связанных отношением ISA. Например для класса С'' , являющегося наследником С', который в свою очередь наследует базовый класс C, отношение ISA должно содержать кортежи {idC'', idC''}(класс С'' является сам собой), {idC'', idC'} (класс С'' является наследником класса C'), и {idC'', idC} (класс С'' является наследником базового класса C). Таким образом, отношение ISA содержит полную информацию о иерархии наследования. Применяя к нему оператор выборки, для любого класса С' можно найти все его классы наследники, или все классы, для которых он является наследником.
4) ATTRspecification –перечисляет существующие атрибуты, определяет, в каких классах они впервые объявлены, определяет реляционный домен (rdom) каждого атрибута
|
o a |
Primary key |
Уникальный идентификатор объектного атрибута (например имя атрибута). |
|
IDC |
Foreign key on CLASSES.IDC |
Идентификатор класса, где этот атрибут впервые объявлен. |
|
IDR |
|
Уникальный идентификатор отношения, являющегося реляционным доменом (rdom) этого атрибута. |
Если в классе C впервые объявлен атрибут oai, определенный на реляционном домене R, то это отношение будет содержать кортеж { oai, idC, idR}.
5) ATTRrealization – описывает реализацию атрибутов в классах и в наследуемых классах, содержит данные, которые могут быть переопределены в процессе наследования
|
o a |
Primary key, Foreign key on ATTRspecification.oa |
Иденитфиткатор объектного атрибута. |
|
IDC |
Primary key, Foreign key on CLASSES.IDC |
Идентификатор класса, содержащего этот атрибут (из-за наследования таких классов может быть много). |
|
Expr |
|
Выражение, вычисляющее значение атрибута (может переопределяться в процессе наследования классов, отсутствует для хранимых атрибутов). |
Если атрибут oai базового класса С переопределен в классе-наследнике C', то это отношение должно содержать кортежи { oai, idC, CE} и { oai, idC', C'E}, где CE и C'E –определенные в классах C и C' выражения, вычисляющие значение атрибута oai. Для хранимых атрибутов выражение CE может отсутствовать.
Связь данных и метаданных.
Еще раз отметим, что на уровне хранения данные и метаданные существуют совместно и представлены в одном и том же виде, а именно как множество значений отношений. Этот факт позволяет использовать присущие реляционным системам механизмы контроля целостности данных для поддержки взаимного соответствия между данными и метаданными.
Описывая стержневое отношение R'0, существующее на уровне хранения, мы сказали, что в него могут входить атрибуты, характеризующие объекты данных, входящие в состав системы. Важнейшей характеристикой всех без исключения объектов данных является класс этих объектов, поэтому в стержневое отношение должно входить поле IDC связанное с первичным ключом отношения CLASSES. Таким образом, каждому объекту данных ставиться в соответствие схема данных класса, который указан в выражении, которым этот объект был создан. Система должна контролировать, что структура объекта на протяжении всей его соответствует схеме данных, определенной для объектов этого класса.
Таким образом, схема стержневого отношения должна выглядеть следующим образом:
R'0
|
r aOID |
Primary key |
|
|
IDC |
Foreign key on CLASSES.IDC |
|
Рассмотрим выражение
new cShipment;
создающее объект класса cShipment. В результате его обработки система должна добавить в стержневое отношение новый кортеж, поле которого будет содержать уникальный идентификатор созданного объекта, а поле IDC будет определять, что этому объекту соответствует схема класса cShipment. Дальнейшие действия, сводящиеся к операциям над кортежами отношений R', содержащими данные об объектах класса cShipment, должны выполняться в соответствии с этой схемой.
Еще раз вернемся к тому факту, что выражение, создающее объект, может не возвращать указатель на него. Предположим, что в классе cShipment определено инициализирующее выражение (конструктор) принимающее в качестве параметра номер отгрузки. Тогда команда
new cShipment(123);
создаст объект данных описывающих отгрузку под номером 123. В дальнейшем мы можем обращаться к этому объекту как к экземпляру класса cShipment. Например, выражение, изменяющее дату отгрузки, может выглядеть следующим образом.
UPDATE cShipment SET cShipment.SDate = "…" WHERE cShipment.NoS = 123
Отметим следующее. Поскольку для каждого объекта данных на всем протяжении его жизни в стержневом отношении хранится информация о том, что этот объект создан как объект определенного класса, то можно утверждать, что стержневое отношение R'0 и отношение OFA суть одно и тоже. Введенный ранее предикат OFA реализуется на уровне хранения простой выборкой кортежей этого отношения по атрибуту IDC. Например следующая часть выражение <30>
s(raOID OFA Ci )( CiE'a (A2, … , A n, …)) будет реализована как
s(IDC = Ci )(
R'0 ><(raOID) ( CiE'a (A2, … , A n, …)) )
<30'>
Релизация предиката ISA немногим более сложна. В этом случае мы должны использовать отношение ISA существующее в каталоге системы.
s(raOID ISA Ci )( E'a ( … , A n, …)) =
s(ISAIDC = Ci) (ISA ><IDC ( R'0 ><(raOID) ( CiE'a (A2, … , A n, …)) ) )
Должен существовать и обратный контроль. Речь идет о случае, когда в процессе эксплуатации системы меняется схема данных. В этом случае должен существовать механизм, контролирующий, насколько вносимые изменения соответствуют уже существующим данным и позволяющий, при необходимости, преобразовывать уже существующие данные. Возможны два случая
1) Изменение схемы свойства R, определенного на уровне представления, сводится к изменению схемы отношения R', которое существует на уровне хранения.
2) Изменения схемы класса (например: добавление или удаление атрибутов класса, изменение вычисляющих выражений и т.п.), на уровне хранения сводится к кортежным операциям над отношениями ISA, ATTRspecification и ATTRrealisation, входящим в каталог системы.
Во втором случае, для контроля корректности изменения схемы класса, можно использовать связь между атрибутом raoa, каждого из отношений R'i, и атрибутом oa отношения ATTRspecification, являющегося первичным ключом этого отношения. Существование такой связи позволяет гарантировать, что для всех кортежей всех отношений R'i в каталоге существуют ассоциированные с ними описания атрибутов, позволяющие привести хранящиеся в них данные к виду, определяемому используемой абстракцией, т.е. представить эти данные как значения атрибутов объектов данных.
Указанные связи между данными и метаданными (уровень хранения), а также связь между отношениями R'i и стержневым отношением R'0, определяют целостность объектов данных o (уровень представления), описываемых как {OID, S, oV}, где OID – уникальный идентификатор указанной переменной, S – метаданные, описывающая структуру указанной переменной, oV - сложное значение, описывающее состояние объекта.
Методы.
Одно из наиболее важных свойств объектно-ориентированных систем определяется тем, что объект характеризуется не только состоянием (набор значений атрибутов) но и поведением [4], выраженным через множество методов, применимых к объекту и инкапсулированных в нем. Методы позволяют управлять состоянием объекта и, следовательно, системы в которую он входит. Таким образом, системы, реализующие объектно-ориентированный подход, объединяют структурные и поведенческие аспекты описания и использования данных.
Предлагаемый подход не содержит каких-либо принципиальных ограничений на определение и использование методов, которые, подобно атрибутам, могут наследоваться и переопределяться. Если предположить, что уровень хранения основан на существующих реляционных СУБД, то метод класса может быть реализован в виде ассоциированной с классом хранимой процедуры, получающей в качестве параметра объектный идентификатор объекта, для которого он вызван. Отметим, что этот идентификатор может быть получен в результате выполнения групповой операции над классом (см. "Групповые операции. Ненавигационный доступ к данным"). Таким образом, возможны вызовы методов из непроцедурных языков высокого уровня. Например, следующее выражение вызовет метод DoShip для объекта класса cShipment, который содержит данные об отгрузке с номер 123
EXEC cShipment.DoShip() WHERE cShipment.NoS = 123.
Можно предположить, что метод может быть вызван и для группы объектов.
EXEC cShippment.DoShip() WHERE cShipment.sDate = Today() <П.5>
Естественно, что возможен вариант, когда к методу неприменимо преобразование, описанное в главе "Групповые операции. Ненавигационный доступ к данным" (например, это будет верно для методов, выполняющих покортежную обработку атрибутов объекта). В этом случае выражение <П.5> может быть реализовано только в виде итератора, последовательно обращающегося к каждому из объектов входящих в обрабатываемую группу. Однако сама группа будет формироваться в результате групповой операции над классом.
В заключение отметим, что для хранения методов можно использовать уже описанный каталог системы, где организация описывающих их метаданных не будет принципиально отличаться от организации метаданных, описывающих вычисляемые атрибуты объектов.
Заключение.
В статье предлагается подход, позволяющий создать объектно–ориентированную информационную систему на основе терминального механизма хранения данных, описываемого реляционной моделью. Вводятся правила, позволяющие преобразовать схему данных, возникшую в результате нормализации, к объектной схеме данных. Исследуются свойства, которыми может обладать система, основанная на предлагаемом подходе. Показано, что такая система
- позволяет описывать перманентно хранящиеся данные в виде сложных идентифицируемых объектов, инкапсулирующих состояние и поведение,
- реализует концепции наследования и полиморфизма,
- позволяет организовать как навигационный, так и ненавигационный доступ к данным,
- позволяет организовать групповой доступ к данным, в основе которого лежат операции реляционной алгебры.
Конечно, в небольшой статье
невозможно предусмотреть все вопросы,
которые могут возникнуть при знакомстве c
предложенным подходом. Однако предлагаемые
решения могут быть вполне достаточными для
практической реализации в виде системы,
которая может представлять определенный
интерес для широкого круга пользователей.
Автор благодарит участников
форума "Проектирование БД",
расположенного на сайте www.sql.ru,
принявших активное участие в обсуждении
статьи, за их ценные замечание и
предложения.
Используемая литература:
-
Системы баз данных третьего поколения: Манифест. Комитет по развитию функциональных возможностей СУБД СУБД №02/95
- Х.Дарвин, К.Дэйт. Третий манифест. СУБД № 1/1996
- М. Аткинсон, Ф. Бансилон, Д. ДеВитт, К. Диттрих, Д. Майер, С. Здоник. Манифест систем объектно-ориентированных баз данных. СУБД № 4/1995
- Гради Буч Объектно-ориентированое Проектирование с примерами применений 1992 Диалектика(Киев) & И.В.К. (Москва)
- Дж.Мартин. Организация баз данных в вычислительных системах. Изд. 2-е 1980 Мир (Москва)
- C.J. Date. The relational model will stand the test of time. Intelligent Enterprise, 1999, Vol. 2, No 8
- Codd E.F. “A relational model for large shared data banks”. Commun. ACM 13, 6, June, 1970, 377-387
- Д. Мейер. Теория реляционных баз данных. 1984 Мир (Москва)
- Крис Дейт. Введение в базы данных. Изд. 6-е. Киев, Диалектика, 1998.
- Конноли, Томас и др. Базы данных: Проектирование, реализация и сопровождение. Теория и практика: 2-е изд., испр. и доп.Москва. Изд.дом "Вильямс",2000.
- An Analysis of Codd's Contribution to the Great Debate C.J. Date Intelligent Enterprise, May 11, 1999, Volume 2,
№ 7
- Модель "Объект-качество".
Евгений Григорьев. http://www.citforum.ru/database/articles/moq.shtml
1) Определение "кибернетические"
в данном случае означает "управляемые".
При определенных внешних
воздействиях (в ответ на определенную
команду) такая система определенным
образом меняет свое состояние. (назад
к тексту)
2) Фактически,
терминальная система хранения данных
предопределяет существующий в языках
программирования набор "базовых"
типов (например, целочисленный тип). Она
представляет собой среду существование
переменных базовых типов и реализует
операции над этими переменными. Говоря
про "базовые типы", нельзя не обратить
внимание на то, что это понятие обычно
ассоциируется с набором простейших типов,
реализуемых аппаратной частью компьютера (например,
byte, char, int, float и т.п.). Однако отметим, что
терминальный механизм не обязательно
реализуется аппаратно (в качестве примера
можно привести виртуальную Java-машину).
Можно предположить, что базовые типы могут
быть произвольно сложными - при условии, что
эта сложность полностью реализована на
уровне терминальной системы. (назад
к тексту)
3) Единственным типом,
реализуемым реляционными системами
хранения данных, является тип "отношение".
Переменными этого типа являются переменные
отношения "relvar" ( или, в терминах SQL-систем,
таблицы) служащие для хранения значений
отношений "relval". Реляционная БД - это БД
в которой все данные представлены в виде
набора значений отношений [9]. (назад
к тексту)
4) С учетом сказанного схема,
описывающая потоки команд и данных, еще
более усложнится и будет выглядеть
приблизительно так. (назад к
тексту)
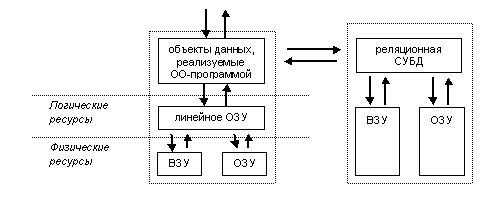
Евгений Григорьев (С) 2003.
Некоторые идеи, изложенные в статье, имеют
патентную защиту.
|
|


 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС