2007 г
Архитектуры ООСУБД. Анализ реализаций
Роберт Грин, вице-президент компании Versant
Перевод: Сергей Кузнецов
Оригинал: OODBMS ARCHITECTURES. An examination of implementations
- 1. Аннотация
- 2. Введение
- 3. Основные факторы
- 3.1. Базовая архитектура
- 3.2. Архитектура, основанная на контейнерах
- 3.3. Архитектура, основанная на страницах
- 3.4. Архитектура, основанная на объектах
- 4. Модель параллельности
- 4.1. Параллельность в архитектуре, основанной на контейнерах
- 4.2. Параллельность в архитектуре, основанной на страницах
- 4.3. Параллельность в архитектуре, основанной на объектах
- 4.4. Следствия модели параллельности
- 5. Сетевая модель
- 5.1. Сетевая модель в архитектуре, основанной на контейнерах
- 5.2. Сетевая модель в архитектуре, основанной на страницах
- 5.3. Сетевая модель в архитектуре, основанной на объектах
- 5.4. Следствия сетевой модели
- 6. Реализация запросов
- 6.1. Реализация запросов в архитектуре, основанной на контейнерах
- 6.2. Реализация запросов в архитектуре, основанной на страницах
- 6.3. Реализация запросов в архитектуре, основанной на объектах
- 6.4. Следствия модели запросов
- 7. Управление идентификационной информацией
- 7.1. Физическая идентификационная информация
- 7.2. Логическая идентификационная информация
- 8. Заключение
- 9. Литература
1. Аннотация
Объектно-ориентированные системы управления базами данных (ООСУБД) существуют уже почти два десятилетия. Основные поставщики приступили к их реализации в конце 1980-х гг., приспосабливая для этого такие языки, как Smalltalk, C++ и Java, а в середине 1990-х начали поставлять коммерческие продукты. В начале имелась большая надежда на то, что ООСУБД заменят РСУБД для поддержки баз данных будущих приложений.
«Большая надежда» не оправдалась, и в этой статье утверждается, что ОДНА из основных причин этого кроется в архитектуре ООСУБД. То есть именно архитектура ООСУБД повлияла на ожидания первопроходцев. Многие успешно внедренные приложения продемонстрировали, что правильная архитектура ООСУБД позволяет создавать высокопроизводительные, многопользовательские, масштабируемые решения. В этой статье анализируется эти ожидания, а также обсуждаются различия между тремя типовыми архитектурами коммерческих ООСУБД.
2. Введение
Когда началось коммерческое использование ООСУБД, реляционная технология уже была хорошо укоренившейся, и, хотя о ней все еще продолжали спорить, все основные поставщики РСУБД заняли свое место на рынке баз данных. В то время компании переходили из стадии принятия решений относительно инфраструктурной технологии баз данных в стадию принятия решений о применении этой технологии для повышения эффективности бизнеса. Были произведены и опубликованы почти все сравнения СУБД на основе эталонных тестовых наборов, таких как TPC. Комплекты приложений с желательными возможностями повышения эффективности бизнеса либо поступали от выбранного поставщика реляционных баз данных, либо разрабатывались с целью поддержки любой реляционной базы данных на основе стандартов SQL. Характеристики баз данных были достаточно близкими, так что трудно было рассчитывать на особые преимущества при выборе какого-нибудь одного поставщика. Поэтому решение об использовании какой-то определенной базы данных часто являлось скорее политическим, а не техническим, способствуя укреплению бизнес-связей, но не обязательно означая выбор «наилучшего» решения получателем приложения. Все действительно понимали, что между РСУБД разных поставщиков имеются лишь незначительные различия, и показатели производительности и масштабируемости отличаются на проценты, а не на порядки величин.
Вот здесь-то и сочетаются архитектура ООСУБД и ожидания пользователей. В то время как архитектуры РСУБД очень похожи (ориентация на клиент-серверную организацию, опора на индексы, процессор выполнения выражений реляционной алгебры) и обладают характеристиками производительности и масштабируемости, отличающимися на небольшие проценты, архитектуры ООСУБД значительно различаются и демонстрируют совершенно разные характеристики. После столь многих лет, в течение которых людей приучали, что все РСУБД ведут себя практически одинаково, было довольно естественно применить эти выводы к ООСУБД и объявить, что и они являются почти одинаковыми. При использовании этого предположения, если какой-либо первопроходец выбирал некоторую ООСУБД, которая плохо соответствовала потребностям его приложений, можно было легко придти к заключению, что никакая ООСУБД не сможет удовлетворить эти потребности. Эти нелогичные рассуждения привели к возникновению неправильных представлений об ООСУБД: они являются слишком медленными, не обеспечивают высокий уровень параллелизма, не масштабируются для работы с большими объемами данных и т.д., и т.п. Все это неправильно, а реальность состоит в том, что требуется внимательно проанализировать характеристики приложения и понять, какая архитектура ООСУБД им более всего соответствует. При выборе правильной архитектуры СУБД показатели производительности и масштабируемости могут повышаться на порядки величин, а не на проценты, как в случае реляционных реализаций. Разобравшись в этом, проанализируем различия в архитектуре ООСУБД, чтобы помочь пользователям принимать решения, ведущие к успешному выбору технологии.
3. Основные факторы
Имеется несколько ключевых реализационных различий, которые приводят к существенно разным характеристикам систем во время выполнения. Задачей этой статьи является обсуждение не всех функциональных возможностей, а только тех основных областей, которые влияют на производительность и масштабируемость при разных характеристиках приложений. В число этих областей входят базовая архитектура, модель параллелизма, реализация запросов, сетевая модель и управление идентификационной информацией.
3.1. Базовая архитектура
Здесь представлены три известные архитектурные реализации ООСУБД. В каждой из реализаций ООСУБД обеспечивают распределенность, параллельную обработку и удаленный доступ, используемые для создания развитых конструкций на уровне системы, но эти системы основываются на разной базовой архитектуре. В этой статье мы будем называть эти три архитектуры основанной на контейнерах (container based), основанной на страницах (page based) и основанной на объектах (object based), что соответствует как единице передачи по сети, так и наиболее низкому уровню гранулированности блокировок. В каждой из архитектур поддерживается кэширование, обработка запросов, управление транзакциями и жизненным циклом объектов (отслеживание новых, недействительных и удаленных объектов). Взглянем на эти архитектуры более внимательно.
3.2. Архитектура, основанная на контейнерах
Архитектура, «основанная на контейнерах», ориентирована на использование на стороне клиентов. В ней используется стандартная или проприетарная реализация NFS для доставки по сети сегментов диска, называемых контейнерами, клиентам, в которых реализуется большинство функциональных возможностей ООСУБД. Пользовательское приложение компонуется с клиентской библиотекой ООСУБД, которая обеспечивает кэширование контейнеров, обработку запросов, управление транзакциями и жизненным циклом объектов. Каждый объект должен содержаться внутри некоторого контейнера, и любой контейнер может содержать много объектов; может использоваться несколько контейнеров. В этой архитектуре разработчики приложений для обеспечения доступа к объектам базы данных должны основывать модели прикладного уровня на модели контейнеров.
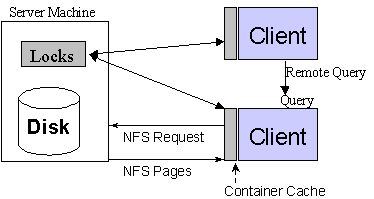
Рис. 1. Архитектура, основанная на контейнерах
3.3. Архитектура, основанная на страницах
Архитектура, «основанная на страницах», ориентирована на использование на стороне клиентов; в этой архитектуре выполняется серверный процесс, обрабатывающий запросы страниц в модели отображения распределенной виртуальной памяти. Серверный процесс используется для доставки по сети страниц диска, которые отображаются в виртуальную память приложения, где реализуется основная часть функциональных возможностей ООСУБД. Код пользовательского приложения компонуется с клиентской библиотекой ООСУБД, обеспечивающей кэширование страниц, обработку запросов, управление транзакциями и жизненным циклом объектов. Требуется реализация специальных стратегий размещения объектов.
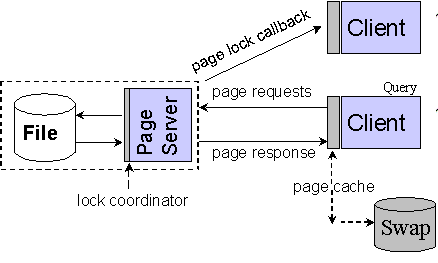
Рис. 2. Архитектура, основанная на страницах
3.4. Архитектура, основанная на объектах
Архитектура, «основанная на объектах», является сбалансированной конструкцией, в которой кэширование и поддержка функционирования осуществляется как в процессах приложений, так и в серверных процессах. Серверный процесс кэшируют страницы диска и управляет индексами, блокировками, запросам и транзакциями. Код пользовательского приложения компонуется с клиентскими библиотеками ООСУБД, обеспечивающими кэширование объектов, локальные блокировки и управление жизненным циклом объектов. Не требуется реализация каких-либо стратегий размещения объектов.
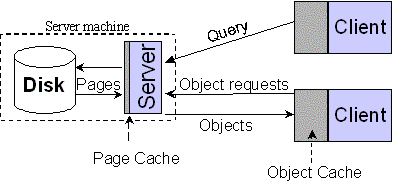
Рис. 3. Архитектура, основанная на объектах
4. Модель параллельности
Как описывается ниже, у этих трех базовых архитектур имеются разные модели управления параллельным доступом. Модели управления параллельным доступом решают проблему изоляции транзакций и тесно связаны с поведенческими характеристиками сети. В любой архитектуре имеются способы ослабления блокировок для некоторых типов приложений, для которых не требуется полный набор свойств ACID (Atomicy – атомарность, Consistency – согласованность, Isolation – изоляция, Durability – долговечность). Дальнейшая часть этого раздела фокусируется на поведении, требуемом для поддержания корректными транзакциями строгих ACID-свойств согласованности и изоляции. Во всех реализациях блокировки могут локально кэшироваться на клиенте за пределами границ транзакций во избежание избыточных запросов блокировки. Однако обновления всегда приводят к выполнению операций координации блокировок и согласования кэшей. При использовании архитектур, основанных на контейнерах и страницах, размещение объектов и блокировки тесно связаны, а архитектура, основанная на объектах, позволяет ортогонализировать эти аспекты. Взглянем более пристально на эти аспекты каждой из архитектур.
4.1. Параллельность в архитектуре, основанной на контейнерах
В этой архитектуре параллельный доступ к информации одного контейнера координируется отдельным серверным процессом блокировок. Клиенты взаимодействуют с централизованным процессом блокировок для запросов блокировок контейнеров в каждой базе данных серверной машины до того, как кэшировать контейнер на клиенте путем обращения к серверу страниц NFS. Запрос на обновление ставится в очередь запросов блокировок контейнера, если к этому времени имеются удовлетворенные блокировки контейнера по чтению. Этот запрос либо отвергается по причине превышения максимального интервала времени ожидания, либо удовлетворяется, когда существующие клиенты освобождают свои блокировки. Как правило, блокировки удерживаются в пределах транзакции. После образования очереди по причине поступления запроса блокировки на обновление все последующие запросы блокировок ставятся в очередь вслед за этим запросом. После того, как выполняется обновление, удовлетворяются все стоящие в очереди запросы блокировки на чтение, и, если нет других обновлений, очередь исчезает. Клиенты, кэшировавшие обновленный контейнер, должны при последующем чтении обновить свой кэш. В контейнерах может содержаться много объектов, поэтому возможны ложные ожидания и ложные синхронизационные тупики.
4.2. Параллельность в архитектуре, основанной на страницах
В этой архитектуре сервер страниц координирует параллельный доступ путем отслеживания того, какие приложения обращаются к каждой странице, предоставления прав на локальную блокировку страниц и использования возвратных вызовов блокировок. Запрос страницы для обновления вынуждает сервер страниц использовать возвратные вызовы, предлагающие другим клиентам освободить свои блокировки этой страницы и отказаться от права на локальную блокировку этой страницы. Либо все клиенты снимают свою блокировку и отказываются от права на локальную блокировку, и запрос блокировки для обновления удовлетворяется, либо этот запрос блокируется на заданный промежуток времени. Каждый клиент, отказавшийся от своих прав, обновляет страницу в кэше и запрашивает новые права и блокировки для следующего доступа к информации на данной странице. Блокировки и права получаются на уровне страниц, и в каждой странице может содержаться много объектов, так что возможны ложные ожидания и ложные синхронизационные тупики.
4.3. Параллельность в архитектуре, основанной на объектах
В этой архитектуре процесс сервера поддерживает очереди запросов блокировок на уровне объектов для управления параллельным доступом к одному и тому же объекту. Запрос блокировки для обновления образует очередь, если имеются читатели объекта. Этот запрос либо удовлетворяется, когда все читатели освобождают свои блокировки, либо отвергается по истечению предельно допустимого интервала времени. После образования очереди запросом блокировки для обновления все последующие запросы попадают в очередь за этим запросом для обновления. После выполнения обновления и снятия соответствующей блокировки с объекта все запросы блокировок для чтения удовлетворяются, и, если больше нет обновлений, очередь исчезает. Клиенты, кэшировавшие обновленный объект, должны обновить его в кэше при последующем чтении. В этой архитектуре блокировки устанавливаются на уровне объектов, поэтому ложные ожидания и ложные синхронизационные тупики не возникают.
4.4. Следствия модели параллельности
Различные модели параллельности могут влиять на производительность приложений в многопользовательских средах, если эти приложения производят много обновлений. Приложения, в которых имеется много конфликтующих обновлений, потенциально тормозятся всеми моделями параллельности, но на то они и модели параллельности. Но в архитектурах, основанных на контейнерах и страницах, потенциально тормозятся и приложения, в которых имеется много не обязательно конфликтующих обновлений, поскольку блокировки производятся таким образом, что могут заблокировать доступ к другим объектам, не используемым в транзакции, что приводит к ложным ожиданиям и синхронизационным тупикам.
Кроме потенциальных ловушек ложных ожиданий и тупиков, гранулированность объектов, вовлекаемых в транзакции приложений, может оказывать в одной архитектуре большее влияние, чем в другой. В архитектуре, основанной на страницах, из-за возвратных вызовов по поводу блокировок при работе сильно гранулированной обновляющей системы требуется намного больше сетевых взаимодействий.
Приложения, у которых имеются относительно фиксированные модели с редко конфликтующими обновлениями, хорошо сегментирующиеся в независимый кластер, обычно ведут себя наилучшим образом в архитектурах, основанных на контейнерах и страницах. Так получается, потому что требуется только высокоуровневая блокировка, а почти не конфликтующие обновления позволяют минимизировать работу по координации блокировок. Одним из примеров, хорошо соответствующих этим характеристикам, являются приложения САПР (системы автоматизированного проектирования). Для приложений этого типа использование ООСУБД может обеспечить повышение производительности на порядки величин по сравнению с традиционными реляционными базами данных. Приложения с более высоким уровнем конфликтов по обновлению и большей гранулированностью моделей обычно лучше всего себя ведут на архитектуре, основанной на объектах.
Уровень влияния параллельного доступа на производительность обычно связан с числом одновременно работающих пользователей или процессов. Упомянутые выше проблемы усиливаются при увеличении числа пользователей или процессов, взаимодействующих с базой данных. В большинстве случаев архитектура, основанная на объектах, лучше всего подходит при большом числе одновременно работающих пользователей и/или процессов, особенно в системах, которые не могут быть хорошо сегментированы для изоляции.
К другим проблемам, окружающим модели параллельного доступа, относится долговременное будущее использование данных, включая эволюцию и сопровождение приложений. Во многих системах для конкретного приложения и его паттернов доступа к данным можно обеспечить фиксированные, хорошо сегментированные данные. Важный вопрос касается введения новых приложений или расширения возможностей существующих приложений над исходными данными. Для новых приложений и возможностей часто требуются другие паттерны доступа. По мере увеличения числа паттернов доступа становиться более трудно обеспечить фиксированные и хорошо сегментированные схемы, и основной мерой является изменение размещения объектов. В действительности, в процессе выбора архитектуры приверженцу объектной технологии следует тщательно проанализировать будущее использование данных.
Как обсуждается ниже, подход к координации блокировок оказывает огромное влияние на сетевую модель, поскольку при обновлении базы данных требуется сетевая активность для обновления кэшей клиентов.
5. Сетевая модель
У трех рассматриваемых архитектур имеются разные сетевые модели, влияющие на использование пропускной способности и производительность распределенной системы. Каждая сетевая модель тесно связана с моделью блокировок, поскольку после получения блокировки требуется пересылка информации, если только она уже не находится в локальном кэше. Низший уровень гранулированности передачи по сети связывается с низшим уровнем гранулированности блокировок.
5.1. Сетевая модель в архитектуре, основанной на контейнерах
Для этой архитектуры единицей пересылки при запросе объекта является контейнер. Все объекты должны располагаться в контейнере, и клиентский запрос объекта разрешается на сервере NFS, посылающем по сети страницы контейнера клиенту, в котором контейнер кэшируются, и обеспечивается последующий доступ к объекту. При пересылке контейнера пересылаются все содержащиеся в нем объекты, независимо от того, требуется ли к ним доступ. Блокировка устанавливается на весь контейнер, независимо от того, к каким объектам требуется доступ запросившей транзакции.
5.2. Сетевая модель в архитектуре, основанной на страницах
Для этой архитектуры единицей пересылки при запросе объекта является страница. Все объекты должны располагаться в страницах, и клиентский запрос разрешается на сервере страниц, посылающем страницу по сети клиенту, где происходит трансляция ее адреса и кэширование для последующего доступа к объекту. При пересылке страницы пересылаются все располагающиеся в ней объекты, независимо от того, требуется ли к ним доступ. Блокировка устанавливается на всю страницу, независимо от того, к каким объектам требуется доступ запросившей транзакции.
5.3. Сетевая модель в архитектуре, основанной на объектах
Для этой архитектуры единицей пересылки при запросе объекта являются объект или группа объектов в зависимости от заданной глубины связей, как проиллюстрировано ниже. Объект может являться коллекцией, и в этом случае при одном сетевом взаимодействии пересылается много объектов. В запросе объекта или коллекции может указываться глубина связей; тогда при одном сетевом взаимодействии вместе с указанным объектом будут пересылаться связанные с ним объекты в пределах указанной глубины связей. При пересылке объекта на него устанавливается блокировка. В случае коллекции или при указании глубины связей блокируются все объекты, посылаемые клиенту. Например, для загрузки в клиента всех объектов, показанных на приведенной ниже иллюстрации, потребовалось бы три сетевых запроса. Если запрашивались бы только служащие или какой-то отдельный служащий, понадобилось бы только одно сетевое взаимодействие. Возможны специальные запросы с указанием глубины связей, позволяющие устранить загрузку избыточных объектов с одновременной минимизацией числа сетевых взаимодействий.
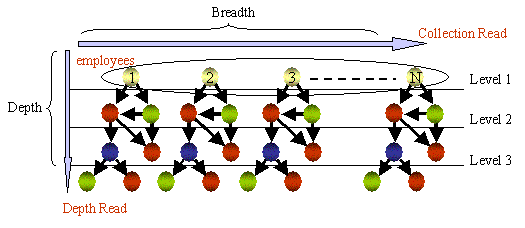
5.4. Следствия сетевой модели
Различные сетевые модели могут влиять на производительность приложений за счет воздействия на число сетевых взаимодействий и коэффициент полезного использования пропускной способности сети, на который влияет объем значимых данных, пересылаемых по сети. Поведение в сетевой среде тесно связано с моделями приложений и характеристиками доступа.
Приложение с почти фиксированной моделью доступа, хорошо сегментируемой в независимый кластер с не конфликтующими обновлениями и/или не слишком большим числом транзакционных обновлений, как правило, хорошо выполняется в архитектуре, основанной на контейнерах или страницах. Это связано с ограниченным числом сетевых взаимодействий, поскольку фиксированный контейнер связанных объектов захватывается и перемещается в кэш клиента за одно сетевое взаимодействие. Фиксированные модели, относящиеся к сценарию, в котором доступ к логически связанным объектам производится одновременно в одной транзакции, хорошо работают в этих архитектурах, поскольку все логически связанные объекты попадут в клиентский кэш сразу после первого доступа к объекту, и сетевые взаимодействия минимизируются с высоким коэффициентом полезного использования пропускной способности сети. Архитектура, основанная на объектах, обычно приводит к большему числу сетевых взаимодействий, по одному обмену по сети на каждый уровень глубины связей в модели. Например, для модели на приведенном выше рисунке могло бы потребоваться в три раза большее число сетевых взаимодействий. Однако так произойдет, если все объекты, показанные на этом рисунке, находятся в одном и том же контейнере или в одной и той же странице. Если они сегментированы (физически кластеризованы) по-другому, то в архитектуре, основанной на контейнерах или страницах, может потребоваться даже большее число сетевых взаимодействий, чем в архитектуре, основанной на объектах. По этой причине для архитектур, основанных на контейнерах и страницах, сетевая производительность, а фактически, и производительность в условиях параллельного доступа существенно связана с физическим размещением объектов на диске. В приложении с такими характеристиками коэффициент полезного использования пропускной способности будет достаточно высоким во всех архитектурах, поскольку будут пересылаться группы логически связанных объектов, и избыточные объекты пересылаться по сети не будут.
При возрастании числа конфликтующих обновлений производительность систем с архитектурами, основанными на контейнерах и страницах, уменьшается, и преимущество получают архитектуры, основанные на объектах. Это связано с тем, что конфликтующие обновления вызывают необходимость обновления кэшей конфликтующих клиентов. Для архитектур, основанных на контейнерах и объектах, это означает, что для поддержания согласованности кэшей по сети требуется пересылать страницы или контейнеры. Наибольшей потерей здесь является пропускная способность сети, поскольку при обновлении единственного объекта из нескольких байт потребуется обновить в кэше потенциально большого числа клиентов несколько тысяч байт – страницу или контейнер. Требуется полное обновление страницы или контейнера, поскольку в соответствующей сетевой модели они являются наименьшими единицами гранулированности.
Поясним, что здесь имеется в виду под конфликтующими обновлениями. Это не обязательно означает обновление одного и того же объекта. Конфликтуют обновления объектов, которые находятся в одной и той же странице или одном и том же контейнере. Поэтому в архитектурах, основанных на контейнерах и страницах, требуется хорошая сегментация модели в физическом кластере, поскольку, если модель не является хорошо сегментированной, при обновлении даже не связанных объектов может возникнуть конфликт на уровне страницы или контейнера, который приведет к ожиданию блокировке и нагрузке на сеть для обеспечения согласованности кэшей. Причина, по которой в архитектурах, основанных на контейнерах и страницах, требуется избегать небольших транзакционных обновлений, кроется в том, что при обновлении требуется произвести запись по сети в долговременное хранилище наименьшей единицы передачи данных – страницы или контейнера. Если обновления хорошо группируются в одну транзакцию, затрагивающую единственный контейнер или страницу, то производительность в таких архитектурах не падает, и в действительности производительность приложения будет намного выше, чем при использовании традиционной реляционной системы.
При возрастании числа конфликтующих обновлений сетевая модель, основанная на объектах, демонстрирует преимущества, поскольку гранулированность пересылок гораздо меньше. Если обновляется объект размером всего в несколько байт, и требуется обновление кэшей клиентов для поддержания их согласованности, то по сети передается всего несколько байтов. Кроме того, немного изменяется понятие конфликтующих обновлений. Во всех архитектурах обновления вынуждают работать механизм согласования кэшей. Поэтому, если модели являются фиксированными и хорошо сегментированными, то архитектуры, основанные на объектах, страницах и контейнерах, ведут себя почти одинаково, если не считать того, что различается объем данных, пересылаемых по сети. Однако если модели не являются хорошо сегментированными, и/или связи между объектами соединяют страницы или контейнеры, которые содержат всего несколько объектов, участвующих в связи, то потенциально потребуется обновлять в кэше многие страницы или контейнеры, содержащие многочисленные избыточные объекты. Это означает, что пропускная способность сети будет использоваться для пересылки избыточных объектов наряду с теми, которые действительно должны быть обновлены в кэше.
Еще одним следствием механизма параллельного доступа и сетевой модели для каждой архитектуры является то, как они ведут себя в трехзвенной архитектуре, будучи встроенными в промежуточное программное обеспечение сервера приложений. Здесь применимы все отмеченные выше аспекты, поскольку кэширование производится локально на серверах приложений, и поэтому для поддержания согласованности кэшей в кластере серверов приложений, который, по существу, является кластером клиентов ООСУБД, требуется обсуждавшееся ранее поведение.
Конечно, на все упомянутое выше влияет увеличение числа пользователей или процессов, получающих доступ к базе данных. Рассмотренные проблемы усложняются при возрастании числа пользователей или процессов. Вообще говоря, архитектура, основанная на объектах, лучше всего подходит для обслуживания большого количества пользователей или процессов, особенно в системах, которые не являются хорошо сегментированными для изоляции, или в которых требуется гибкость для обеспечения в будущем новых паттернов доступа.
Надеюсь, что из приведенного обсуждения стало ясно, что у сетевой модели каждой архитектуры имеются свои преимущества и недостатки. В архитектурах, основанных на страницах и контейнерах, для достижения оптимальной производительности требуется тщательное физическое планирование моделей приложений. В правильно сегментированной фиксированной модели это способствует эффективному использованию пропускной возможности сети. В архитектуре, основанной на объектах, для достижения оптимальной производительности требуется понимание логических сценариев использования. В отличие от архитектур, основанных на страницах и контейнерах, в которых требуется понимание физического моделирования, в архитектуре, основанной на объектах, требуется понимание логики, так что в каждом приложении могут использоваться специальное кодирование или метаданные для определения загрузки модели на основе сценариев использования. Эта работа способствует достижению высокого уровня параллелизма и масштабируемости для исключительного большого числа транзакций, одновременно повышая уровень гибкости для обеспечения возможности перекрывающихся паттернов доступа при будущем использовании данных.
6. Реализация запросов
Реализации ООСУБД фокусируются на обеспечении возможности бесшовной навигации между связанными объектами с использованием языковых конструкций. Прирожденная поддержка паттернов навигационного доступа является ключевым преимуществом ООСУБД над сложным понятием соединения, применяемого в РСУБД. По существу, связи являются статической, а не вычисляемой во время выполнения частью системы, что существенно убыстряет их использование. В каждой реализации теоретически возможно определить один главный объект, выборка которого обеспечивает навигационный доступ ко всем другим объектам базы данных. Однако по практическим соображениям реализации приложений обычно управляются сценариями использования. Нет смысла без нужды затрагивать объекты, не соответствующие сценарию использования. Кроме того, из требований масштабируемости больших баз данных следует потребность в эффективном использовании дисков, сети и основной памяти. Поэтому в ООСУБД обеспечиваются средства запроса запросов на выборку объектов первого уровня, соответствующих сценарию использования, и допускается последующая навигация от этих стартовых объектов. Здесь мы снова не преследуем цели детального объяснения поведения каждого процессора запросов, а обсуждаем основные моменты реализаций. За пределами статьи остаются такие подробности, как возврат идентификаторов для отложенной загрузки, а не реальных объектов, и т.д.
6.1. Реализация запросов в архитектуре, основанной на контейнерах
В реализации архитектуры, основанной на контейнерах, используется обработка запросов на стороне клиента. «Клиент» является некоторым процессом, отличным от серверного процесса страниц NFS. Можно сопоставить это с традиционной РСУБД, архитектура которой имеет противоположную природу. В РСУБД все сосредоточено в серверном процессе: обработка запросов, индексация, блокировки и управление страницами, что делает ее реализацию сервер-ориентированной, а не клиент-ориентированной. В реализации архитектуры, основанной на контейнерах, все объекты базы данных, которые затрагиваются запросом, должны идентифицироваться некоторым контейнером базы данных. Этот контейнер содержит все потенциально полезные индексы и загружается в клиентский процесс для выполнения запроса. После загрузки всех потенциально требуемых объектов или индексов и выполнения запроса возвращаемые результаты являются контейнерами, содержащими результирующие объекты, которые удовлетворяют запросу. Тем самым, с точки зрения передачи по сети и блокировки результат может содержать много объектов, которые в действительности не удовлетворяют предикату запроса. Если клиент является удаленным, то результаты попадают в исходные запрашивающий пользовательский процесс через несколько звеньев. Эффективность выполнения запросов может обеспечиваться путем использования общесистемных идентификаторов, многопотоковой, удаленной и распределенной обработки, агрегирования.
6.2. Реализация запросов в архитектуре, основанной на страницах
В реализации архитектуры, основанной на страницах, используется обработка запросов на стороне клиента. При этой реализации все объекты базы данных, которые затрагиваются запросом, должны содержаться в коллекциях, загружаемых в клиентский процесс для выполнения запроса. Запросы и индексация могут срабатывать только над этими коллекциями. После загрузки коллекции объектов и выполнения запросов результатом являются ссылки на объекты, удовлетворяющие предикату запроса, и неявно уже загруженные по сети и подсоединенные к виртуальной памяти клиента страницы, которые содержат эти объекты. Тем самым, с точки зрения передачи по сети и блокировки результат может содержать много объектов, которые в действительности не удовлетворяют предикату запроса.
6.3. Реализация запросов в архитектуре, основанной на объектах
В реализации архитектуры, основанной на объектах, используется процессор выполнения запросов, который выполняется в процессе сервера баз данных. Любой объект базы данных достижим через запрос, даже если у него отсутствует связь с другими объектами. Атрибуты объектов могут индексироваться при поддержке сервера баз данных. Запрос производится путем посылки серверу некоторого оператора, который выполняется на сервере с использованием оптимизатора и механизма индексации, и клиенту возвращается результирующий набор объектов. По сети передаются только оператор, который будет выполняться на сервере, и коллекция объектов, удовлетворяющих предикату, в качестве результата запроса. Эффективность выполнения запросов может обеспечиваться путем использования общесистемных идентификаторов, многопотоковой, удаленной и распределенной обработки, агрегирования.
6.4. Следствия модели запросов
Разные модели запросов могут существенно влиять на эффективность приложения. Основными факторами для достижения оптимальной производительности являются (1) место выполнения запросов, (2) гибкость при выборе того, что может запрашиваться, (3) возможности индексации.
Реализации ООСУБД всегда фокусируются на навигационном доступе, как основном способе выборки информации из базы данных. Здесь снова не ставится цель проанализировать все возможности механизма запросов, такие как проецирование, агрегация, представления, математические вычисления, курсоры, составные индексы и т.д., и т.п. Целью является обеспечение понимания основ реализации. Как правило, ни одна из реализаций не была настолько полной, как те, которые обеспечиваются в реляционном мире, где весь доступ к данным производится через запросы. К счастью, эта ситуация изменяется по мере того, как все поставщики приходят к новому пониманию взаимного дополнения ролей запросов и навигационного доступа. Можно достаточно уверенно сказать, что после почти двух десятилетий существования ООСУБД во всех реализациях имеются зрелые возможности, делающие их полезными, и реальные вопросы теперь затрагивают масштабируемость и производительность.
Эффективность операций запросов более всего страдает в тех ситуациях, когда объекты, потенциально удовлетворяющие запросу, требуется перемещать в адресное пространство другого запроса для оценки предиката. Эта проблема свойственна реализациям механизма запросов в архитектурах, основанных на страницах и контейнерах. В особенности в этом отношении уязвима архитектура, основанная на страницах, поскольку запросы могут адресоваться только к объектам, входящим в специальные коллекции, и индексы применимы только к этим коллекциям. Для выполнения запроса по сети должны загружаться все страницы, содержащие объекты в этих коллекциях или индексы для этих коллекций. Эти страницы, безусловно, будут содержать много лишних объектов, что приводит к неэффективному расходованию пропускной способности сети и падению производительности, поскольку на пересылку страниц может тратиться больше времени, чем на реальную обработку запроса. Можно представить себе ситуацию, в которой имеется миллион объектов Foo, среди которых ищется всего один объект. Вдобавок к этому при каждой вставке требуется поддержка индексов, а поскольку потенциально они могут быть распределены между многими клиентскими процессами, может возникнуть много недействительных страниц, и понадобятся сетевые обновления коллекций и индексов, дополнительно нагружающие сеть.
Архитектура, основанная на контейнерах, ведет себя таким же образом, что и архитектура, основанная на страницах. Однако запросы могут обрабатываться в удаленном режиме, могут расщепляться, и индексы поддерживаются в централизованном процессе. Поэтому, хотя контейнеры объектов и/или индексов должны загружаться для обработки в другой процесс, выполнение запроса может производиться в параллель, и по сети нужно пересылать в исходное звено обратившегося процесса только контейнеры, удовлетворяющие предикату. Хотя это решение не идеально, оно является более масштабируемым, чем механизм запросов в реализации архитектуры, основанной на страницах.
Реализация архитектуры, основанной на объектах, в которой, подобно РСУБД, индексирование и выполнение запросов происходит на стороне сервера, обеспечивает механизм запросов, наиболее близкий к оптимальному. Отсутствует потребность в пересылке между процессами каких-либо избыточных объектов, индексы управляются локально, и оптимизация запросов производится в процессе сервера баз данных, в результате чего возвращается только объект или набор объектов, удовлетворяющих предикату. Кроме того, многопотоковая организация клиентского процесса позволят выполнять запросы к нескольким физическим базам данных в параллель.
При использовании систем с архитектурой, основанной на страницах или контейнерах, управление индексами обычно интегрируется с кодом приложений. Это влияет на сопровождение приложений. При использовании систем с архитектурой, основанной на объектах, индексы управляются сервером. Новые индексы могут определяться без изменения приложений.
7. Управление идентификационной информацией
Во всех основных архитектурах различаются подходы к реализации управления идентификационной информацией, хотя принципиально эти подходы различаются одним аспектом. По своей природе идентификационная информация может быть физической или логической. В ООСУБД идентификационная информация используется для обеспечения уникальности и реализации связей. Упомянутое различие в реализации имеет глубокие последствия для долговременного функционирования и гибкости. Кроме того, детали реализации физической идентификационной информацией влияют на масштабируемость данных для систем, требующих хранения терабайт информации.
7.1. Физическая идентификационная информация
Смысл физической идентификации состоит в том, что у всех объектов в системе распределенных баз данных имеется уникальный идентификатор, зависящий от физического месторасположения объекта в системе. Характеристиками физической идентификации являются изменчивость, повторная используемость, стационарность, жесткость.
Одним из последствий является то, что объекты трудно перемещать в системе без влияния на другие объекты, с которыми они связаны. Причина этого состоит в том, что за связями объектов скрываются идентификаторы связанных объектов. Если некоторый объект перемещается в системе, то изменяется его физическое местоположение, и поэтому изменяется его идентификатор (изменчивость). Нужно найти все объекты, существующие в системе, которые содержат ссылку на данный объект, и сделать так, чтобы в полях связи скрывалось новое физическое местоположение (стационарность). По мере возрастания размеров базы данных эта операция становится все более дорогостоящей. Умышленного перемещения объектов можно избежать, хотя имеется много развитых архитектур систем, в которых можно было бы использовать перемещение объектов для управления активными наборами данных в высокопроизводительных крупномасштабных системах.
Но, к сожалению, перемещение объекта может происходить в качестве побочного эффекта других операций, не предусмотренных в архитектуре системы. Например, при эволюции схемы может измениться компоновка объекта, так что он перестанет помещаться в существующем месте. В таком случае эволюция схемы сделает необходимым перемещение объекта и в качестве побочного эффекта вызовет огромную нагрузку на систему, приведя ее в состояние неработоспособности на время изменения схемы. Такую же ситуацию может вызвать увеличение размеров объекта по причине наличия полей переменной длины. К подобной ситуации может привести и изменение схемы кластеризации.
К числу других последствий относится возможное падение производительности вследствие фрагментации. В реляционных базах данных это классическая проблема приложений, производящих большое число удалений, из-за чего производительность с течением времени постоянно деградирует. Большинство поставщиков РСУБД поставляет дополнительные инструментальные средства, выполняющие реорганизацию базы данных при достижении порогового значения требуемого времени отклика. В случае ООСУБД и физической идентификации, если удаляется объект, невозможно уплотнить объекты на странице и освободить память, поскольку это привело бы к изменению идентификаторов и недействительности существующих связей. Поэтому этим ООСУБД свойственна та же проблема, что и реляционным базам данных, в которых со временем порождается все больше и больше незанятой памяти, в результате чего время отклика все более и более возрастает.
Ключевое отличие в реализации систем с физической идентификационной информацией приводит к существенному отличию по части масштабируемости при управлении «сырыми» данными на дисках. Применение в архитектуре, основанной на страницах, подхода трансляции адресов делает невозможным истинно интегрированное распределение данных на диске. Можно сегментировать данные внутри одной базы данных, чтобы приложения работали с подобластями этой базы данных в адресных пространствах своих процессов, но невозможно обеспечить в дисковой подсистеме распределенную (федеративную) базу данных, доступную клиентам в виде логического источника данных. Это означает, что в реализации архитектуры, основанной на контейнерах, возможности масштабируемости распространяются до терабайтных и даже петабайтных диапазонов, но в реализации архитектуры, основанной на страницах, они ограничены диапазонами мегабайт или гигабайт.
7.2. Логическая идентификационная информация
Смысл логической идентификации состоит в том, что у каждого объекта распределенной базы данных имеется уникальный идентификатор, не зависящий от физического местоположения объекта в системе. Характеристиками логических идентификаторов являются неизменчивость, отсутствие повторного использования, мобильность, гибкость. Последствием является то, что объекты могут свободно перемещаться в системе без влияния на другие объекты, с которыми они связаны. Объект может перемещаться из одной физической базы данных в другую, и существующие связи от других объектов остаются работоспособными, а существующий код по-прежнему может выполняться, поскольку они основаны на логической идентификационной информации, а не на физических адресах. Возможны развитые разработки, такие как архивация данных с использованием активных наборов данных, без потребности наличия в приложениях кода, связанного с местоположением данных. Внутренние операции, подобные операциям эволюции схемы и уплотнения страниц, могут выполняться в режиме он-лайн без риска долговременной потери работоспособности системы. Кроме того, использование логических идентификаторов позволяет обеспечить прозрачную для приложений федерацию находящихся на дисках баз данных как логическую сущность, что дает возможность масштабирования в диапазонах терабайт или петабайт без потребности специального кодирования, связанного с распределенностью данных.
8. Заключение
Понимание основ архитектурной реализации ООСУБД и их сопоставление с характеристиками требуемого приложения может помощь успешному применению технологии объектно-ориентированных баз данных. В отличие от реляционной технологии, разные архитектуры ООСУБД в зависимости от характеристик приложения могут обеспечивать производительность и масштабируемость, различающиеся на порядки величин. Архитектуры, основанные на страницах и контейнерах, обеспечивают хорошее решение при наличии относительно фиксированных моделей, низкого или среднего уровня параллельного доступа и правильно сегментированных данных. В архитектуре, основанной на объектах, понятия блокировки, размещения и перемещения объектов являются независимыми, и эта архитектура обеспечивает наилучшее решение при наличии высокого уровня параллелизма, возрастании масштабности и изменчивости приложений и данных.
При выборе архитектуры ООСУБД следует тщательно проанализировать такие аспекты, как возрастание объема данных со временем, число параллельно работающих с базой данных пользователей или процессов, ожидаемые в будущем требования к изменению моделей предметной области, уровень гранулированности моделей и ожидаемые требования к сети. Снова и снова оказывается, что объектная база данных может быть более предпочтительным решением по сравнению с реляционной технологией при наличии сложных моделей предметной области, не укладывающихся должным образом в парадигму реляционного хранения данных. Выбор ООСУБД с архитектурой, соответствующей характеристикам приложения, является ключом для доступа ко всем возможностям технологии и достижения успеха.
9. Литература
- Versant Object Database Fundamental Manual - release 7.0.1.0, July 2005
- Objectivity Inc. Technical Overview, Release 9, January 2006
- Locking and Concurrency, Objectivity Inc, 1999
- ObjectStore Architecture Introductory, Dirk Butson.
См. также ответ на эту статью:

 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС

