2009 г.
МОГучие способности: новые приемы анализа больших данных
Джеффри Коэн, Брайен Долэн, Марк Данлэп, Джозеф Хеллерстейн, Кейлэб Велтон.
Перевод: Сергей Кузнецов
Назад Содержание Вперёд
5. Статистика, параллельная по данным
Аналитики и статистики являются наиболее ухищренными в данных сотрудниками организации, и поэтому от них зависит МОГущество организации. В этом разделе мы сосредотачиваемся на мощных и общих статистических методах, которые делают хранилище данных более "магнетичным" и "гибким" для анализа, стимулируют аналитиков производить "основательные" исследования и значительно повышать уровень сложности и масштабности анализа данных.
Наш общий подход заключается в том, чтобы разработать иерархию математических понятий на SQL и инкапсулировать их таким образом, чтобы позволить аналитикам работать с использованием сравнительно знакомой статистической терминологии без потребности разработки статистических методов на SQL с самого начала при каждом вычислении. Аналогичную функциональность можно закодировать с использованием синтаксиса MapReduce.
В традиционных SQL-ориентированных базах данных обеспечиваются типы данных и функции для простой (скалярной) арифметики. Следующим уровнем абстракции является векторная арифметика со своим набором операций. Векторные объекты совместно с векторными операциями приводят нас к языку линейной алгебры. В подразделе 5.1 мы предлагаем методы для этих операций. На этом уровне мы можем говорит на языке машинного обучения, математического моделирования и статистики. Следующий уровень абстракции – это уровень функций; плотности вероятностей являются специализированными функциями. С интуитивных позиций, имеется и еще один уровень абстракции, на котором функции являются базовыми объектами, и алгебры создаются с использованием операций, называемых "функционалами", которые действуют над функциями. Это область функционального анализа. Методы типа t-тестов или отношений правдоподобия (likelihood ratio) являются функционалами. В A/B-тестировании функционалы обрабатывают одновременно два математических объекта: функции плотности распределений f1(·) и f2(·).
Тем самым, наша задача состоит в том, чтобы развить методы баз данных от скалярных до векторных, потом до методов над функциями, и потом до методов над функционалами. Кроме того, мы должны сделать это в массивно параллельной среде. Это не тривиально. Даже у "простой" на вид проблемы представления матриц нет одного оптимального решения. В нескольких следующих подразделах мы описываем методы, используемые нами для превращения параллельной базы данных в сильно масштабируемый статистический пакет. Мы начинаем с векторной арифметики и продвигаемся по направлению к функционалам, обсуждая попутно мощные статистические методы.
5.1. Векторы и матрицы
Реляционные базы данных разрабатываются в расчете на масштабирование при росте объема данных. Здесь описывается, как мы представляем крупные "векторные" и "матричные" объекты в виде отношений и реализуем над ними логические операции. Это дает нам векторную арифметику.
До построение операций нам нужно определить, что означает "вектор" (часто в форме матрицы) в контексте базы данных. Имеется много способов разделения таких матриц ("блоками", "порциями" ("chunk")) по узлам параллельной системы (см., например, [2], гл. 4). Простой способ, хорошо подходящий для параллельных баз данных, состоит в представлении матрицы в виде отношения со схемой (row number integer, vector numeric[]) и разрешении СУБД разделять строки между процессорами произвольным образом – например, на основе хэширования или циклической схемы. На практике мы часто материализуем и A, и A´, чтобы этот метод построчного представления работал более эффективно.
Для матриц, представляемых подобным образом в виде горизонтально разделенных отношений, нам нужно реализовать базовую матричную арифметику в виде запросов над этими отношениями, чтобы эти запросы могли выполняться параллельно.
Рассмотрим две матрицы A и B одной и той же размерности. На SQL легко выражается сложение матриц:
SELECT A.row_number, A.vector + B.vector
FROM A, B
WHERE A.row_number = B.row_number;
Заметим, что здесь операция "+" выполняется над массивами числовых типов и возвращает массив той же размерности, так что на выходе получается матрица той же размерености, что и у матриц-операндов. Если в СУБД не поддерживается операция сложения векторов, ее легко реализовать с использованием объектно-реляционных расширений и зарегистрировать как инфиксную операцию [19]. Для выполнения этого запроса оптимизатор запросов, вероятно, выберет метод соединения с хэшированием, который хорошо распараллеливается.
Умножение матрицы на вектор Av также выражается просто:
SELECT 1, array_accum(row_number, vector*v) FROM A;
Здесь снова операция "*" выполняется над массивами числовых значений, но в этом случае она возвращает одно числовое значение – скалярное произведение операндов: 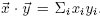 Ее также можно реализовать как определяемую пользователем функцию и зарегистрировать как инфиксную опрерацию с использованием языка запросов [19]. Пары (
Ее также можно реализовать как определяемую пользователем функцию и зарегистрировать как инфиксную опрерацию с использованием языка запросов [19]. Пары (row number, vector*v) представляют вектор как пары (индекс, значение). Чтобы вернуться к нашему построчному представлению мы выполняем преобразование к типу массиву в единственной результирующей строке на основе специальной агрегатной функции array accum(x,v), которая вычисляет значение одного элемента массива, сопоставляя с позицией x каждой строки операнда-матрицы значение вектора v.
В большинстве РСУБД имеются функции над последовательностями. В PostgreSQL и Greenplum команда generate series(1, 50) сгенерирует последовательность 1, 2, ..., 50. Один из способов вычисления транспонированной матрицы A´ для матрицы A размерности m×n можно выразить на SQL следующим образом (для n = 3):
SELECT S.col_number,
array_accum(A.row_number, A.vector[S.col_number])
FROM A, generate_series(1,3) AS S(col_number)
GROUP BY S.col_number;
К сожалению, если A хранит n-мерные вектора, то в операции группирования будут участвовать n копий таблицы A. Альтернативой является переход к другому представлению матриц, например, к разреженному представлеению вида (row number, column number, value). Преимущество такого подхода состоит в том, что в этом случае на SQL гораздо легче выразить операцию перемножения матриц AB:
SELECT A.row_number, B.column_number, SUM(A.value * B.value)
FROM A, B
WHERE A.column_number = B.row_number
GROUP BY A.row_number, B.column_number
Этот запрос очень эффективно выполняется над разреженными матрицами, если в них не сохраняются нулевые значения. Вообще говоря, хорошо известно, что никакое одно представление не удовлетворяет все потребности, и на практике приходится использовать смеси. При отсутствии должной абстракции это может привести к путанице, посколько для каждого представления нужно определять специальные операции. В SQL разные представления можно получить за счет соглашений об именовании (материализованных) производных таблиц, но выбор такой таблицы обычно производится аналитиком, поскольку традиционный оптимизатор запросов не знает об эквивалентности этих производных таблиц. Результаты исследования в этом направлении описаны в литературе по параллельным вычислениям [23], но их еще требуется интегрировать с механизмами оптимизации запросов и поддержки вычислений над данными большого объема.
Приведенные рассуждения применимы к операциям скалярного умножения, сложения векторов и умножения векторов/матриц, которые по своей сути являются однопроходными методами. Задача деления матриц в параллельно контексте не решена окончательным образом. Одно из неудобств SQL состоит в отсутствии удобного синтаксиса для организации итераций. Фундаментальные методы вычисления обратной матрицы предполагают два или большее число проходов по данным. Однако рекурсивные или итеративные процедуры могут выполняться во внешних процессах с минимальным объемом потока данных с основного узла. Например, в методе сопряженных градиентов, описываемом в п. 5.2.2, между итерациями запрашивается всего одно значение. Хотя деление матриц усложнено, мы можем разработать оставшуюся часть методов, описываемых в этой статье, на основе процедур псевдоинверсии (с учетом предупреждений, приводимых в учебниках по математики по поводу существования и сходимости).
Обширный набор (теперь распределенных) векторных объектов и операций над ними образует существительные и глаголы математических статистиков. В этом смысле функции действуют как высказывания. Мы продолжим рассмотрением знакомого примера, выраженного на этом языке.
5.1.1. Мера tf-idf и косинусная мера сходства
Введение векторных операций позволяет нам говорить о методах гораздо более компактно. Здесь мы рассматриваем конкретный пример: установление сходства документов – инструмент, общеупотребительный в Web-рекламе. Одна из областей использования – выявление подделок. Когда у многих разных рекламодателей имеются ссылки на очень похожие страницы, обычно, на самом деле, все они являются одной группой злоумышленников, и очень вероятно использование для оплаты украденых кредитных карт. Поэтому разумным подходом является обследование исходящих ссылок рекламодателей и поиск похожих документов.
Распространенная метрика сходства документов tf-idf включает три или четыре шага, которые все легко распределяются и хорошо сводятся к методам SQL. Во-первых, необходимо создать триплеты (document, term, count). Затем с использованием простых SQL-запросов с GROUP BY вычисляются маргиналы по document и term. После этого исходные триплеты можно расширить оценкой tf-idf по каждому измерению (т.е. для каждого слова результирующего словаря) путем соединения триплетов с маргиналами данного документа и отделения счетчика числа документов от счетчика числа терминов. На основе этого для каждых двух документов вычисляется косинусная мера сходства, и получается стандартная метрика "расстояния".
Более точно, хорошо известно, что для двух векторов весов терминов x и y косинусное сходство θ задается соотношением θ = 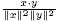 . Нетрудно сформулировать "простой" SQL-запрос, воспроизводящий это соотношение. Но аналитики с подготовкой в области статистики привыкли думать в другом стиле – этот подход (и пример с разреженными матрицами из п. 5.1) фокусируется на объединении в пары скалярных значений, а не на работе на более высоком уровне с векторами, представляющими "объекты целиком". Возможность выразить идеи, подобные tf-idf, в терминах линейной алгебры снижает барьер, мешающий статистикам создавать приложения над базами данных. Операция взятия скалярного произведения сводит вычисление косинусной меры tf-idf к очень естественному синтаксису (предполагается, что в матрице A каждому вектору документа соответствует одна строка):
. Нетрудно сформулировать "простой" SQL-запрос, воспроизводящий это соотношение. Но аналитики с подготовкой в области статистики привыкли думать в другом стиле – этот подход (и пример с разреженными матрицами из п. 5.1) фокусируется на объединении в пары скалярных значений, а не на работе на более высоком уровне с векторами, представляющими "объекты целиком". Возможность выразить идеи, подобные tf-idf, в терминах линейной алгебры снижает барьер, мешающий статистикам создавать приложения над базами данных. Операция взятия скалярного произведения сводит вычисление косинусной меры tf-idf к очень естественному синтаксису (предполагается, что в матрице A каждому вектору документа соответствует одна строка):
SELECT a1.row_id AS document_i, a2.row_id AS document_j,
(a1.row_v * a2.row_v) /
((a1.row_v * a1.row_v) * (a2.row_v * a2.row_v)) AS theta
FROM A AS a1, A AS a2
WHERE a1.row_id > a2.row_id
Для любого аналитика, привыкшего к скриптовой среде SAS или R, эта формулировка совершенно приемлема. Кроме того, работа по распределению объектов и определению операций выполняется DBA. Если объекты и операции становятся более сложными, возрастают преимушества наличия предопределенных операций. С практической точки зрения мы превращаем систему баз данных из простой системы выборки данных в интерактивную среду аналитического программирования.
5.2. Аналитические методы на основе матриц
В нашем случае основной интерес представляют крупные, плотно заполненные матрицы. Обычно мы имеем дело с матрицей расстояний
D, где
D(
i,
j) > 0 почти для всех (
i,
j). Также нас интересуют ковариационные матрицы Σ для сильно коррелирующих наборов данных.
5.2.1. Обычный метод наименьших квадратов
Мы начнем с обычного метода наименьших квадратов (Ordinary Least Squares, OLS) – классического метода подбора кривой для данных, обычно с использованием полиномиальной функции. В Web-рекламе одним из стандартных приложений этого метода является моделирование сезонных тенденций. При наличии нескольких простых определенных пользователями функций над векторами аналитики могут естественным образом выражать OLS на SQL.
В нашем случае мы находим стастистическую оценку β*, наилучшем образом удовлетворяющую соотношение Y = Xβ. Здесь X = n × k – это набор фиксированных (независимых) переменных, и Y – набор из n наблюдений (зависимых переменных), которые мы хотим промоделировать посредством функции X с параметром β.
Как отмечается в [3],

можно подсчитать путем вычисления A = X′X и b = X′y как суммирования. В параллельной базе данных это можно выполнить путем параллельного вычисления локальных A и b в каждом разделе базы данных с последующим слиянием промежуточных результатов в заключительном последовательном вычислении.
В результате будут получены квадратная матрица и вектор. Заключительное вычисление производится путем обращения небольшой матрицы A и ее умножения на вектор для получения коэффициентов β*.
Кроме того, попутно может быть произведено вычисление коэффициента смешанной корреляции R2:
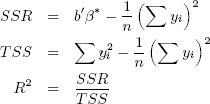
В следующем SQL-запросе мы вычисляем коэффициенты β*, а также компоненты коэффициента смешанной корреляции:
CREATE VIEW ols AS
SELECT pseudo_inverse(A) * b as beta_star,
(transpose(b) * (pseudo_inverse(A) * b)
- sum_y2/count) -- SSR
/ (sum_yy - sumy2/n) -- TSS
as r_squared
FROM (
SELECT sum(transpose(d.vector) * d.vector) as A,
sum(d.vector * y) as b,
sum(y)^2 as sum_y2, sum(y^2) as sum_yy,
count(*) as n
FROM design d
) ols_aggs;
Отметим использование определяемой пользователем функции для транспонирования вектора и определяемых пользователем агрегатов для суммирования объектов (многомерного) массива. Массив A – это небольшой массив, размещаемый в основной памяти, с которым мы обращаемся, как с одним объектом; функция pseudo-inverse реализует известное из учебников псевдообращение матрицы методом Мура-Пенроуза (Moore-Penrose).
Все указанные вычисления можно эффективно произвести за один проход по данным. Для удобства мы инкапсулировали это еще в двух определяемых пользователями функциях:
SELECT ols_coef(d.y, d.vector), ols_r2(d.y, d.vector)
FROM design d;
До выполнения реализации этой функциональности внутри СУБД один из заказчиков Greenplum имел привычку вычислять OLS путем экспорта данных и их импорта в R, и этот процесс занимал несколько часов. Они сообщали о значительном повышении производительности после перехода к вычислению внутри СУБД. Основным преимуществом является параллельное выполнение анализа неподалеку от данных с их минимальным перемещением.
5.2.2. Сопряженные градиенты
Здесь мы обсуждаем параллельную по данным реализацию метода сопряженных градиентов (Conjugate Gradiant) для решения системы линейных уравнений. Мы можем использовать это для реализации машины опорных векторов (Support Vector Machines, SVM) – современного метода бинарной классификации. Бинарные классификаторы являются распространенным средством в области размещения рекламы, используемым для превращения мгогомерных характеристик пользователей в простые булевские метки типа "является любителем автомашин", которые можно объединять в
диаграммы любителей (enthusiast chart). Кроме того, что метод сопряженных градиентов служит строительным блоком для SVM, он позволяет оптимизировать большой класс функций, которые можно аппроксимировать рядами Тейлора второго порядка.
Для математика решение матричного уравнения Ax = b не представляет труда, если оно существует: x = A-1b. Как отмечалось в подразделе 5.1, мы не можем считать, что в состоянии найти A-1. Если матрица A является (n × n)-симметричной и положительно определенной (symmetric and positive definite, SPD), то мы можем использовать метод сопряженных градиентов. Для применения этого метода не требуется ни df(y), ни A-1, и он сходится не более чем за n итераций. Общее описание метода проводится в [17]. Здесь мы кратко описываем решение уравнения Ax = b как точки экстремума f(x) = ½x´Ax + b´x + c. Грубо говоря, у нас имеется некоторая оценка 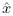 нашего решения x*. Поскольку – это всего лишь оценка,
нашего решения x*. Поскольку – это всего лишь оценка, 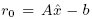 является ненулевым. Вычитание этой ошибки r0 из оценки позволяет нам сгенерировать ряд
является ненулевым. Вычитание этой ошибки r0 из оценки позволяет нам сгенерировать ряд  ортогональных векторов. Решением будет x* = Σiαipi для αi, определяемого ниже. Вычисления завершаются в точке
ортогональных векторов. Решением будет x* = Σiαipi для αi, определяемого ниже. Вычисления завершаются в точке 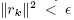 для соответствующего ε. Имеется несколько вариантов этого алгоритма; мы написали свой вариант в матричной нотации.
для соответствующего ε. Имеется несколько вариантов этого алгоритма; мы написали свой вариант в матричной нотации.
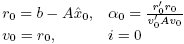
Начнем итерацию по i.
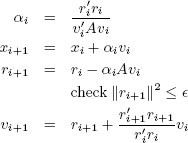
При включении этого метода в базу данных мы сохраняли (vi, xi, ri, αi) как строку и вставляли на каждом проходе строку i+1. Для этого потребовалось определить функции update_alpha(r_i, p_i, A), update_ x(x_i, alpha_i, v_i), update_r(x_i, alpha_i, v_i, A) и update_v(r_i, alpha_ i, v_i, A). Хотя вызовы функций были избыточными (например, update_v() также запускается для обновления ri+1), это позволяло нам вставлять на каждом шаге одну полную строку. Затем перед продолжением вычислений внешний управляющий процесс проверял значение ri. После достижения точки сходимости x* вычисляется элементарным образом.
Наличие метода сопряженных градиентов позволяет реализовать более сложные методы типа SVM. В своей основе метод SVM направлен на максимизацию расстояния между заданным множеством точек и подходящей гиперплоскостью. Это расстояние выражается длиной нормальных векторов 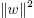 . В большинстве методов в качестве индикаторов c используются целые числа {0, 1}, так что проблема выражается следующим образом:
. В большинстве методов в качестве индикаторов c используются целые числа {0, 1}, так что проблема выражается следующим образом:
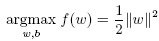 при условии c´w - b ≥ 0.
при условии c´w - b ≥ 0.
Этот метод применяется для решения более общей проблемы функций высокой размерности в приближении рядом Тейлора fx0(x) ≈ f(x0 + df(x)(x - x0) + ½(x - x0)´d2f(x)(x - x0). При хорошем начальном приближении для x* и распространенном предположении о непрерывности f(·) мы знаем, что матрица будет SPD поблизости от x*. Подробности см. в [17].
Назад Содержание Вперёд




 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС