2010 г.
SQL/MapReduce: практический подход к поддержке самоописываемых, полиморфных и параллелизуемых функций, определяемых пользователями
Эрик Фридман, Питер Павловски и Джон Кислевич
Перевод: Сергей Кузнецов
Оригинал: Eric Friedman, Peter Pawlowski, John Cieslewicz. SQL/MapReduce: A practical approach to self-describing,
polymorphic, and parallelizable userdefined
functions. Proceedings of the 35th VLDB Conference, August 24-28, 2009, Lyon, France
От переводчика
В качестве предисловия, комментария и послесловия к этой статье я написал небольшую заметку «SQL и MapReduce: новые возможности или латание старых дыр?». Возможно, ее первую часть стоит прочитать до чтения перевода.
Содержание
- Аннотация
- 1. Введение
- 1.1. SQL/MapReduce
- 1.2 Формирование данных о пользовательских сессиях на основе журнальных файлов Web-сайтов
- 2. Родственные работы
- 3. Синтаксис и функциональные возможности
- 3.1 Синтаксис запросов
- 3.1.1 Разделение
- 3.1.2 Сортировка
- 3.1.3 Разделы специальных архумеентов
- 3.1.4 Использование как отношения
- 3.2 Модель выполнения
- 3.3 Интерфейс программирования
- 3.3.1 Контракт времени выполнения
- 3.3.2 Функции для обработки данных
- 3.3.3 Функции-комбинаторы
- 3.3.4 Скользящие агрегаты
- 3.4 Инсталляция SQL/MR-функции
- 3.5 Инсталлируемые файлы и временные каталоги
- 4. Архитектура системы
- 4.1 Общие сведения о СУБД nCluster
- 4.2 SQL/MR в nCluster
- 4.2.1 Планирование запросов
- 4.2.2 Выполнение запросов
- 5. Приложения
- 5.1 Счетчик слов
- 5.2 Анализ неструктурированных данных
- 5.3 Параллельные загрузка и трансформация
- 5.4 Приблизительные процентили
- 6. Экспериментальные результаты
- 6.1 Анализ данных о посещаемости Web-сайтов
- 6.2 Поиск корзин просмотров страниц
- 7. Заключение
- Благодарности
- 8. Литература
Аннотация
Функции, определяемые пользователями (user-defined function, UDF), – это мощный механизм, позволяющий пользователям расширять функциональные возможности систем баз данных. Несмотря на всю полезность существующих механизмов UDF, в них имеются многочисленные ограничения, включающие требование объявления входной и результирующей схем во время инсталляции и недостаточную возможность распараллеливания выполнения. Мы представляем новый подход к реализации UDF, называемый SQL/MapReduce (SQL/MR) и позволяющий преодолеть многие из этих ограничений. Мы используем идеи парадигмы программирования MapReduce для обеспечения пользователей простым API, с использованием которого они могут реализовать UDF на предпочитаемом ими языке. Кроме того, наш подход обеспечивает максимальную гибкость, поскольку схема результата UDF специфицируется самой функцией во время формирования плана выполнения запроса. Это означает, что SQL/MR-функция является полиморфной. Она может обрабатывать произвольные входные данные, поскольку ее поведение, как и результирующая схема, динамически определяется на основе информации, доступной во время формирования плана выполнения запроса, такой как входная схема функции и специальные параметры, задаваемые пользователями. Это также способствует повторному использованию, поскольку одна и та же SQL/MR-функция может применяться с различными входными схемами и задаваемыми пользователями параметрами.
В этой статье мы описываем побудительные мотивы этого нового подхода к поддержке UDF, а также его реализацию в системе nCluster компании Aster Data Systems. Мы демонстрируем, что в контексте массивно-параллельных систем баз данных без совместно используемых ресурсов эта модель способствует возможности сильно масштабируемых вычислений внутри системы баз данных. Мы также приводим примеры новых приложений, получающих приемущества от использования этой новой инфраструктуры UDF.
1. Введение
Анализ данных постоянно возрастающего объема находится в центре повседневной деятельности и формирования прибыли многих предприятий. Сегодня даже у небольших предприятий накапливаются терабайты данных. Эффективный анализ этих данных может быть ключом к их будущему успеху.
В реляционных СУБД SQL представляется как декларативный язык для манипулирования данными. Однако средства обработки запросов этих СУБД часто не справляются с такой задачей. Аналитики полагают, что SQL слишком сильно ограничивает типы запросов, которые им требуются для извлечения смысла из данных, а те, кто в меньшей степени знаком с декларативным SQL, желают иметь возможность запрашивать данные с использованием более привычных для них процедурных языков. Наконец, в реализациях реляционных СУБД присутствуют несовершенные оптимизаторы запросов, иногда выбирающие неудачные варианты выполнения запросов и не учитывающие варианты оптимизации, специфичные для конкретных прикладных областей. При работе с крупными данными эти неудачные варианты выбора часто обходятся очень дорого, приводя к тому, что выполнение запросов завершается аварийным образом (например, из-за исчерпания рабочей области памяти) или длится недопустимо долгое время, потребляя ценные ресурсы.
Для преодоления этих проблем во многих реляционных СУБД поддерживаются определяемые пользователями функции (User-Defined Function, UDF), в виде которых разработчик может реализовывать задачи с использованием процедурного языка. К сожалению, традиционная инфраструктура UDF разрабатывалась в расчете на один экземпляр базы данных, а параллелизм, если и добавлялся, то задним числом. Это является все более существенным недостатком, поскольку при возрастающих объемах данных требуется применять параллельный подход к обработке и управлению данными с использованием сотен серверов баз данных.
В этой статье мы представляем SQL/MapReduce (SQL/MR), новую инфраструктуру UDF, которая параллельна по своей природе и предназначена для естественного параллельного вычисления процедурных функций на сотнях серверов, работающих вместе как единая реляционная СУБД. Описывается эффективная реализация инфраструктуры SQL/MR в массивно-параллельной реляционной СУБД nCluster компании Aster Data Systems (рис. 1). Представлены примеры приложений, которые стали возможными после появления SQL/MR. Описываемые экспериментальные результаты демонстрируют выигрыш в эффективности, обеспечиваемый SQL/MR по сравнению с "чистым" SQL.
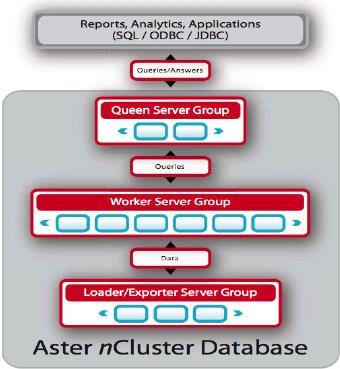
Рис. 1. Общая схема организиции системы баз данных nCluster. Координация системы и запросов производится королевскими (queen) узлами. Данные сохраняются в рабочих (worker) узлах, в которых также производится параллельная обработка запросов. Загрузка данных ускоряется с использованием дополнительных узлов загрузки (loader).
Инфраструктура программирования MapReduce Джеффри Дина (Jeffrey Dean) и Санджая Генавата (Sanjay Ghemawat) [7] делает возможным параллельное вычисление на сотнях серверов. Эта инфраструктура разработана в расчете на использование аппаратных средств массового спроса, и в ней делается упор на отказоустойчивость, что позволяет вычислять задачи, даже если некоторые вызовы завершились аварийно. Инфрастуктура предполагает наличие распределенной файловой системы, в файлах которой находятся обрабатываемые данные, и инфраструктура обеспечивает параллелизацию вычислений над этими данными.
Мощность инфраструктуры программирования MapReduce усиливается в контексте массивно-параллельной SQL-ориентированной СУБД. Комбинация SQL/MR является исключительно эффективной:
- она позволяет SQL эффективно выполнять реляционные операции, оставляя процедурным функциями нереляционные задачи и оптимизации, специфичные для прикладной области;
- она обеспечивает согласованность вычислений, гарантируя, что функции имеют дело с согласованным состоянием данных;
- она позволяет оценочному оптимизатору принимать решения о способе выполнения запроса на основе статистики данных, а не на интуиции "времени создания запросов";
- и она дает возможность конечным пользователям компоновать собственные запросы с использованием высокоуровневых средств BI.
Мы разрабатывали SQL/MR как инфрастуктуру UDF следующего поколения, в которой функции являются:
- самоописываемыми и динамически полиморфными – это значит, что входная схема SQL/MR-функции определяется неявным образом во время обработки запроса, и выходная схема определяется программным образом самой функцией во время выполнения запроса;
- естественным образом параллелизуемыми – как для многоядерных машин, так и для массивно-параллельных кластеров;
- поддающимися композиции, поскольку мы определяем их поведение на входе и выходе таким образом, что внешне они подобны подзапросам SQL (и, следовательно, с вызовом функции можно обращаться, как с таблицей);
- эквивалентными подзапросам, что позволяет системе применять обычную оценочную оптимизацию запросов на основе статистики и методы динамической реорганизации запросов.
В нашей реализации инфрастуктуры SQL/MR:
- функции могут организовывать структуры в своей собственной памяти и в файлах;
- легко добавляются библиотеки сторонних поставщиков, которые можно использовать для снижения трудозатрат на реализацию функций;
- при этом процессы выполнения функций содержатся в изолированной программной среде, что значительно уменьшает вероятность повреждения системы из-за неправильной работы функции.
Наша модель совместима с множеством языков программирования, включая управляемые языки (managed language, Java, C#), традиционные языки (C, C++) и скриптовые языки (Python,
Ruby).
Эти особенности позволяют реализовывать SQL/MR-функции, как истинно библиотечные функции, работающие над произвольными входными данными; конкретное поведение функций определяется во время обработки запросов, в контексте которых они используются. Это позволяет экспертам разрабатывать мощные функции, которые могут затем использоваться другими людьми в иных контекстах без изменения кода. Инфраструктура SQL/MR и ее реализация делают систему nCluster компании Aster Data дружественной по отношению к приложениям.
Оставшаяся часть статьи организована следующим образом. В разд. 2 обсуждаются близкие по тематике работы. В разд. 3 и 4 рассматриваются синтаксис SQL/MR и реализация инфраструктуры. В разд. 5 демонстрируются некоторые примеры SQL/MR-функций. Экспериментальные результаты, демонстрирующие масштабируемость и производительность SQL/MR-функций, представлены в разд. 6. Разд. 6 содержит заключительные замечания.
1.1 SQL/MapReduce
SQL/MR позволяет пользователям писать собственные функции на любом языке программирования и вставлять их вызовы в запросы, в которых во всех остальных отношениях используются традиционные функциональные возможности SQL. SQL/MR-функция определяется в манере, похожей на способ определения функций map и reduce в среде MapReduce, но в случае SQL/MR эти функции выполняются в контексте базы данных.
Во многих отношениях инфраструктура SQL/MR обеспечивает большие возможности, чем традиционные механизмы UDF. Наиболее важно то, что по умолчанию SQL/MR-функции являются параллельными. Как будет показано в разд. 3, модель исполнения SQL/MR-функций (обеспечиваемая их API, на особенности которого повлиял подход MapReduce) является параллельной по своей сути. Запросы выполняются параллельно на крупных кластерах, что обеспечивает линейную масштабируемость системы при возрастании объема данных. Мы продемонстрируем это в разд. 6. SQL/MR-функции также являются динамически полиморфными и самоописываемыми. На практике это означает, что входные схемы SQL/MR-функций определяются неявно во время обработки запросов, а результирующие схемы определяются программным образом самими функциями во время выполнения запроса. Кроме того, в вызов SQL/MR-функции во время выполнения запроса могут быть включены разделы специальных аргументов, обеспечивающих дополнительный динамический контроль над поведением функции и схемой. Эти особенности позволяют реализовывать SQL/MR-функции как истинно библиотечные функции, работающие над произвольными входными данными; конкретное поведение функций определяется во время обработки запросов, в контексте которых они используются. Сложный аналитический код может разрабатываться экспертами и затем использоваться другими людьми в иных потоках работ без каких-либо изменений. Детали синтаксиса SQL/MR и реализация инфраструктуры описываются в разд. 3 и 4.
Мы продемонстрируем некоторые преимущества SQL/MR на примере формирования данных о пользовательских сессиях на основе журнальных файлов Web-сайтов (clickstream sessionization). Большее число примеров можно найти в разд. 5 и 6.
1.2 Формирование данных о пользовательских сессиях на основе журнальных файлов Web-сайтов
При анализе посещений пользователями Web-сайтов распространенной аналитической задачей является разделение посещений ("кликов") данного пользователя на сессии. Сессия – это некоторый период активности пользователя на Web-сайте. В сессию включаются все клики пользователя, произведенные им в заданный период времени. На рис. 2 демонстрируется разбиение на сессии таблицы кликов. Эта простая таблица кликов содержит только временную метку (timestamp) клика и идентификатор пользователя (userid), ассоциированный с данным кликом. В результирующей таблице (рис. 2b), которая для наглядности разделена по userid, каждая пара кликов, время между которыми меньше 60 секунд, считается входящей в одну и ту же сессию.
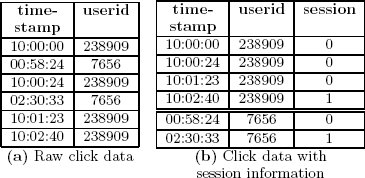
Рис. 2. Пример разбиения кликов на сессии: в таблице (a) содержатся необработанные данные о кликах, а в таблице (b) клики сгруппированы по userid, и в строки добавлен номер сессии; сессии формируются на основе временного интервала в 60 секунд.
Разбиение на сессии можно выполнить с использованием SQL, но SQL/MR позволяет упростить это действие и повысить его эффективность. В SQL/MR-функции для этого разбиения требуется только один проход по таблице кликов, в то время как при выполнении SQL-запроса потребуется дорогостоящее соединение этой таблицы с ней же самой. Кроме того, динамический полиморфизм SQL/MR-функции позволяет повторно использовать ее для вычисления информации о сессиях над таблицами с любой схемой. Таким образом, SQL/MR-функция для разбиения на сессии становится повторно используемой библиотечной подпрограммой, которую может использовать любой аналитик.
Сначала мы покажем использование SQL/MR-функции sessionize в запросе над таблицей кликов с рис. 2, а потом опишем реализацию самой функции.

Рис. 3. Использование в запросе вызова SQL/MR -функции sessionize.
На рис. 3 показано использование SQL/MR-функции sessionize в запросе над таблицей кликов. Мы производим разделение таблицы по userid, чтобы сгруппировать клики каждого пользователя. Затем каждый раздел упорядочивается по временным меткам. Имеются два раздела специальных аргументов: TIMECOLUMN и TIMEOUT. Во время инициализации раздел аргумента TIMECOLUMN указывает, какой атрибут входной таблицы будет анализироваться для определения принадлежности к сессии. Также сохраняется и значение аргумента TIMEOUT, так что оно может использоваться во время выполнения для определения того, не обнаружена ли граница какой-либо сессии. Во время инициализации SQL/MR функция sessionize также определяет свою результирующую схему, как схему входной таблицы, к которой добавлен атрибут session целого типа. Такое поведение позволяет использовать SQL/MR-функцию sessionize при любой схеме входной таблицы. Для достижения еще большей гибкости можно было бы добавить третий собственный раздел аргумента OUTPUTALIAS. Тогда во время выполнения пользователь мог бы указать имя нового столбца таблицы сессий.
Реализация SQL/MR-функции sessionize очень проста. Она реализуется как функция над разделами, при вызове которой входная таблица разделяется по значениям атрибута, определяющего, чьи сессии мы хотим выявлять, например, userid. Внутри каждого раздела входные данные должны быть упорядочены по значениям атрибута, определяющего границы сессий, например, ts. Для каждого обработанного раздела счетчик сессий инициализируется нулем. За один проход по каждому разделу SQL/MR-функция sessionize сравнивает значения TIMECOLUMN соседних кортежей для определения того, не превышает ли разность этих значений заданное значение TIMEOUT. Если не превышает, то для обоих кортежей в номер сессии заносится текущее значение счетчика сессий, иначе счетчик сессий увеличивается на единицу, и номеру сессии кортежа с большим значением TIMECOLUMN присваивается новое значение счетчика. Исходный код этой функции показан в подразделе 3.3, в котором описывается интерфейс программирования SQL/MR.
2. Родственные работы
Определяемые пользователями функции и процедуры – это давнишние средства СУБД, позволяющие расширять их функциональные возможности. Подобно тому, как определяемые пользователями типы (user-defined type, UDT) позволяют приспособить к потребностям пользователей то, что сохраняется в базе данных (см., например, [19]), определяемые пользователями функции дают возможность индивидуализировать то, как в системе баз данных обрабатываются данные [18, 11, 6, 20, 21, 22, 4, 12]. Оптимизации способов выполнения запросов к базе данных, содержащих вызовы UDF, посвящались серьезные исследования; см., например, [6, 11, 10]. Но большая этих работ выполнялась в контексте одного экземпляра базы данных, и в них почти не затрагивались аспекты параллельного выполнения UDF в параллельной СУБД без совместно используемых ресурсов.
Проводились некоторые исследования, посвященные определяемым пользователями агрегатам, скалярным функциям [14] и табличным операциям [15]. Традиционные определяемые пользователями агрегаты могут выполняться параллельно при наличии определяемых пользователями локальной и глобальной функций завершения вычислений (finalize function) [14]. Тогда частичные агрегаты вычисляются параллельно, а затем глобально завершается вычисление общего агрегата. Параллельные скалярные функции без состояния параллелизуются тривиально. Для другого класса скалярных функций, таких как "скользящее среднее" (moving average), требуется поддержка некоторого состояния, но если пользователь явно указывает способ разделения, то система может разделить данные и выполнить вычисление параллельно [14]. В качестве следующего шага в [15] предлагаются определяемые пользователями табличные операции, в которых, аналогично аргументам и результатам SQL/MR-функций, отношениями являются и аргументы, и результаты. При определении табличных операций пользователь должен статически предоставить системе стратегию разделения, чтобы сделать возможным параллелизм и проинформировать систему о том, как можно использовать соответствующую операцию. При определении SQL/MR-функций явный или статический выбор способа разделения или использования функции не требуется – эта информация определяется во время обработки запроса на основе контекста использования SQL/MR-функции.
Идея табличной функции присутствует и в SQL, и определяемые пользователями табличные функции поддерживаются в большинстве комерческих СУБД (см., например, [12], [18], [16]). В Oracle и Microsoft SQL Server, кроме того, поддерживаются параметры-таблицы. Модель программирования, применяемая в этих системах по умолчанию, является не параллельной, так что функции пишутся в предположении, что они получат все входные данные. В некоторых реализациях допускается явная параллелизация функций. Например, у табличных операций в Oracle имеется раздел PARALLEL ENABLE, обрабатываемый во время создания функции и означающий, что параллелизация допускается, а также определяющий, каким образом входные строки следует разделять между параллельно выполняемыми потоками управления. В отличие от этого, в модели программирования для SQL/MR по умолчанию предполагается параллельное выполнение функций. Кроме того, в SQL/MR раздел PARTITION BY, определяющий способ группировки входных строк, является семантической частью запроса (а не опцией времени создания функции), так что для изменения способа группировки входных данных функцию переопределять не требуется.
В некоторых системах обеспечивается поддержка полиморфных (зависимых от контекта) результирующих схем функций. Этот подход является более гибким, чем традиционный подход к определению UDF, при котором схемы параметров и результата функции задаются во время ее создания. Например, в Oracle имеется родовой (generic) тип данных ANYDATASET, который можно использовать во время создания функции, чтобы отложить принятие решения о конкретном типе данных; во время обработки запроса функция должна будет указать системе, каков этот конкретный тип. Эта идея используется и в системе обработки данных компании Microsoft SCOPE [5], в частности, для поддержки извлечения структурированных данных из плоских файлов. В SQL/MR-функциях этот подход полностью перенимается и расширяется; в них отсутствует потребность в конфигурировании во время создания, допускается полиморфизм входной схемы, а также допускается использование разделов специальных аргументов (подробности см. в разд. 3) функции, обрабатываемых во время выполнения запросов. Эти возможности индивидуализации времени выполнения запросов позволяют SQL/MR-функциям работать над различными входными данными; эти функции больше похожи на библиотечные функции общего назначения, а не на традиционные UDF.
В последнее время возрастает интерес к инфраструктурам распределенной параллельной обработки данных. К числу примеров относятся MapReduce компании Google [7], Dryad компании Microsoft [13], и проект с открытыми исходными текстами Hadoop [1]. Эти инфраструктуры обеспечивают мощные средства параллельной обработки данных, поскольку от пользователей требуется всего лишь реализация строго определенных процедурных методов. После этого инфраструктура управляет параллельным выполнением этих методов в крупных кластерах серверов. Основное преимущество таких систем состоит в том, что разработчикам требуется писать лишь простые процедурные методы, которые затем применяются параллельно с использованием строго определенной процедуры разделения и агрегации данных. Недостаток этих инфраструктур заключается в том, что разработчикам часто приходится писать код для выполнения задач, которые могут быть легко выражены на SQL или другом языке запросов. В частности, ограничивается повторное использование кода для непредвиденных запросов, поскольку отсутствует язык более высокого уровня, чем процедурный код.
Для MapReduce-подобных инфраструктур предлагались и системы более высокого уровня, включая Pig [17], Hive [2] и SCOPE [5]. Во всех них комбинировалась высокоуровневая, декларативная природа SQL с низкоуровневыми, процедурными, параллельными возможностями среды MapReduce. Хотя разработчики Hive и SCOPE пытаются добиться совместимости или хотя бы близости с SQL для его интеграции с кодом MapReduce, в этих системах предлагается значительно измененный синтаксис SQL. Например, в добавление к обычном разделу SELECT в SCOPE появляются разделы PROCESS, REDUCE и COMBINE. В отличие от этого, в SQL/MR вводится лишь небольшое число новых синтаксических конструкций и семантических правил, обеспечивающих использование вызовов параллельных функций в качестве таблиц. В целом эти языки являются хорошим развитием подхода MapReduce, поскольку в этой среде появляется некоторая разновидность декларативных языков. В подходе же SQL/MR возможности массивно-параллельной SQL-ориентированной СУБД расширяются на основе использования модели программирования MapReduce. Этот подход позволяет использовать в SQL/MR-функциях структуры данных, определяемые в реляционных базах данных на основе схем, и допускает применение оценочных оптимизиторов, в которых применяются реляционная алгебра и стастистика данных для перезаписи запросов.
Содержание Вперёд




 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС