К сожалению, ситуация с литературой по системам баз данных в нашей стране такова, что многие важные работы не только не переведены на русский язык, но зачастую не существует даже их русскоязычных обзоров. Подобная ситуация сложилась и с ARIES. Несмотря на массу англоязычных публикаций про алгоритмы этого семейства в крупнейших изданиях, посвященных тематике баз данных, повсеместное применение и признание ARIES, публикаций на русском языке фактически нет. Данная статья призвана восполнить этот пробел.
Семейство алгоритмов ARIES содержит алгоритмы восстановления систем, в которых поддерживается понятие транзакции. В настоящее время алгоритмы этого семейства являются крайне популярными и используются в целом ряде продуктов крупнейших производителей программного обеспечения. Так, например, ARIES используется в СУБД IBM DB2, Starburst и Lotus Domino/Notes. Из продуктов других компаний можно назвать ныне покойную объектно-ориентированную СУБД O2 (O2 Technology), Microsoft SQL Server и файловую систему NTFS.
Чем же вызвана такая популярность этого семейства алгоритмов? Дело в том, что алгоритмы ARIES оказались чрезвычайно гибкими. Не фиксируя почти никаких особенностей реализации, любой из алгоритмов предлагает разработчику массу вариантов для достижения тех или иных преимуществ.
Каждый из алгоритмов ARIES представляет собой собрание множества небольших подалгоритмов, которые сравнительно легко понять и реализовать. Помимо этого, алгоритмы этого семейства отличаются сильной "ветвистостью", то есть рассматриваются различные способы реализации того или иного эффекта, в зависимости от выбранных способов журнализации, буферизации, структур данных и так далее.
Вероятно, именно с этим свойством "ветвистости" связано то, что название оригинального алгоритма ARIES (Algorythm for Recovery and Isolation Exploiting Semantics) довольно быстро претерпело небольшие изменения. Первую букву названия стали расшифровывать не как Algorythm, а как Algorythms. Множество разновидностей оригинального алгоритма появилось почти сразу после его создания. На сегодняшний день можно выделить около десяти специализированных алгоритмов семейства ARIES, наиболее крупными из являются ARIES for Semi-Structured Data [1] (этот алгоритм был реализован в Lotus), ARIES/KVL и ARIES/IM [2]. Два последних алгоритма ориентированы на детальную разработку способов управления индексами. Они были в различной степени реализованы в СУБД DB2.
Бросив беглый взгляд на семейство алгоритмов ARIES, перейдем к его более детальному рассмотрению. Начнем с истории создания алгоритма.
1. Краткая история ARIES
В середине 80-х годов в исследовательском центре корпорации IBM Almaden начался проект под названием Starburst. Его целью было создание расширяемой реляционной СУБД. Именно тогда группа исследователей из числа разработчиков Starburst решила сосредоточить свое внимание на устройстве системы управления транзакциями. Они решили пересмотреть ряд предположений и выводов, к которым пришли разработчики знаменитой реляционной СУБД System R. Это желание привело к тому, что было потрачено много времени на изучение того, как работала система управления транзакциями в System R и некоторых других СУБД компании IBM. Исследования были настолько основательны, что был даже опубликован ряд статей, касающихся многих неизвестных до этого сторон работы System R. Вся эта деятельность позволила прийти к выводам о сильных и слабых местах в дизайне существовавших систем.
Например, выяснилось, что разработчики System R, хотя и убедились в том, что при восстановлении базы данных упреждающая журнализация (WAL - Write Ahead Log) работает лучше, чем механизм теневых страниц (Shadow Page Technique), не преуспели в разработке таких методов журнализации и восстановления, в которых поддерживались бы блокировки небольших объектов (например, блокировки кортежей) без потребности блокировки более крупного объекта (в то время, как блокируя кортеж, содержащийся в некоторой физической странице, мы хотели бы позволить системе беспрепятственно работать с другими кортежами этой страницы). Однако в некоторых существовавших продуктах IBM это свойство поддерживалось. Например, в иерархической СУБД IMS можно было производить блокировки самых различных объектов. Но при этом захват происходил не на логическом, а на физическом уровне (то есть блокировка закрывала доступ к конкретным сегментам памяти). Это приводило к тому, что реорганизация кортежей в странице должна была происходить в режиме, запрещающем операции над страницей.
Создатели ARIES решили объединить все лучшие разработки IBM в области управления транзакциями, журнализацией и восстановлением в единый алгоритм. Эта цель была ими во многом достигнута. Работа над базовым алгоритмом ARIES была завершена к середине 80-х годов. Первые публикации появились в начале 90-х.
Однако, это лишь первый этап развития ARIES. Второй этап включает в себя внедрение ARIES в индустрию и разработку расширений алгоритма, наиболее интересном из которых, по-видимому, являлся алгоритм ARIES for Semi-Structured Data. Это расширение было выполнено под руководством Мохана в рамках проекта Dominotes. Целью этого проекта была разработка способа восстановления на основе журнализации для Lotus Domino/Notes. Выяснилось, что, несмотря на существенные особенности модели полуструктурированных данных, ARIES удалось сравнительно легко адаптировать и внедрить в уже существовавший продукт.
Алгоритм оказался столь удобен и прост, что его многочисленные варианты используются сейчас в большинстве систем, поддерживающих транзакции. Как уже отмечалось, ARIES используется в файловой системе NTFS, MS SQL Server, IBM DB2, O2 и многих других системах.
Разработкой алгоритма занималась группа исследователей, но главным вдохновителем и идеологом ARIES был Мохан (C. Mohan). Пусть читателя не удивляет столь необычное имя. Дело в том, что Мохан происходит из той части Индии, где нет такого понятия как фамилия. Поэтому все его работы подписаны именно так. Мохан является автором большинства статей про ARIES. В 1999 году за работу над ARIES он получил награду "10 Years Award" на самой крупной международной конференции, посвященной тематике СУБД, - VLDB (доклад, сделанный по этому поводу, был опубликован в виде статьи [3]). Эта награда вручается автору наиболее важного доклада из тех, что были сделаны на VLDB за последние 10 лет. Создание ARIES привело также к созданию нового структурного подразделения IBM - Института технологий баз данных (Data Base Technology Institute - DBTI). Эта организация позволила исследователям IBM более тесно сотрудничать с разработчиками и клиентами фирмы. Это, в свою очередь, привело к более четкому осознанию проблем, стоящих перед сообществом баз данных.
Сегодня ссылки на статьи по ARIES можно найти в самых известных учебниках по системам баз данных. Семейство алгоритмов изучают во многих университетах США, в некоторых из которых были разработаны специальные системы для демонстрации свойств ARIES (в качестве примера можно привести систему Mars, разработанную в университете Cornell). Так что ARIES смело можно назвать хрестоматийным алгоритмом.
Теперь обратимся к описанию самого алгоритма ARIES. Здесь мы будем рассматривать лишь основной алгоритм ARIES [4], на базе которого были созданы все расширения. Мы также будем говорить об ARIES в контексте баз данных, хотя область его применения не ограничивается СУБД.
2. Журнализация и теневой механизм
Итак, чтобы обеспечить возможность восстановления данных в случае сбоя, ARIES предусматривает запись в журнал данные обо всех производимых транзакциями те действиях, которые могут изменить состояние базы данных. Журнал становится источником информации, необходимой для определения корректности завершения работы транзакций при разнообразных сбоях, а также при восстановлении поврежденных или потерянных данных. В ARIES используется широко известный метод упреждающей журнализации (WAL). При использовании этого способа ведения журнала записи о некоторой операции над базой данных попадают на энергонезависимый носитель (далее мы будем полагать, что в этой роли выступает жесткий диск) раньше, чем в базу вносятся изменения, произведенные этой операцией.
Альтернативной техникой, используемой для восстановления в случае сбоев, является механизм теневых страниц. Основное отличие систем, использующих теневые страницы, от систем, где для восстановления используется только журнал, заключается в том, что последние записывают изменения, внесенные в страницу базы данных в то же место, где располагалась предыдущая версия данных. При использовании же теневых страниц, измененная версия страницы данных записывается на другое место диска. В случае сбоя можно восстановить базу данных на основе старой (теневой) версии страницы и журнала. Как видно, идея, стоящая за теневым механизмом, проста и легко поддается реализации. Однако по ряду причин техника восстановления на основе теневых страниц, несмотря на всю свою простоту, считается хуже, чем восстановление с использованием упреждающей журнализации. Более детально этот вопрос рассмотрен в [5].
Для того, чтобы продолжить изложение алгоритма, требуется рассмотреть ряд структур данных, используемых в ARIES. Начнем со структуры записи журнала.
3. Структура записей журнала
Поскольку в ARIES на журнал возлагается вся ответственность за восстановление данных, записи журнала являются достаточно сложными и содержат массу информации. Эти записи имеют различную структуру в зависимости от журнализуемого действия. Например, запись, помещаемая при обычной работе транзакции, несколько отличается от записи, помещаемой в случае ее частичного или полного отката. Для обозначения записей последнего типа будем использовать термин CLR (Compensation Log Record). Ниже перечисляются некоторые поля записи журнала, которые используются далее при описании ARIES. Конечно, приводимая структура записи не является единственно возможной. Она максимально упрощена для удобства изложения основных идей алгоритма.
Поле LSN (Log Sequence Number) содержит номер записи журнала. Для простоты изложения будем считать, что это значение постоянно увеличивается (т.е. номера не используются повторно). Будем также полагать, что сам журнал представляет собой бесконечно увеличивающийся файл, хотя, конечно, на практике обычно используется группа файлов. В качестве LSN часто используется адрес первого байта записи журнала. Из этого следует, что хранить LSN в виде отдельного поля не обязательно.
Содержимое поля Type определяет тип того действия, которое описывает запись журнала. В этом поле могут встретиться такие значения, как "compensation" (для записи, соответствующей откату некоторого шага транзакции), "update" или "commit". Тип действия может быть и не связан с работой транзакций (например, записи могут относиться к работе менеджера буферизации)
Поле TransID содержит идентификатор транзакции, к которой относится запись журнала.
В поле PrevLSN хранится номер предыдущей записи, добавленной в журнал журнализуемой транзакцией. В первой записи, созданной транзакцией, это значение полагается равным нулю. Таким образом, все записи, которые описывают изменения, вносимые данной транзакцией, оказываются связанными в список. Это позволяет при необходимости отката пройти от конца транзакции к началу, пошаговым образом отменяя все действия, совершенные транзакцией.
Поле PageID присутствует только в записях, описывающих действия по изменению данных, таких как update или compensation. Поле содержит идентификатор изменяемой страницы данных.
Поле UndoNxtLSN присутствует только в CLR-записях (тех записях, которые журнализуют откаты транзакций). Оно содержит LSN следующей записи журнала, которую надо будет обработать при откате.
По этому поводу требуется некоторый комментарий. Существенной особенностью ARIES является то, что компенсационные записи (CLR), фиксирующие откаты транзакций, сами не допускают отката. В оригинальной работе про ARIES они называются redo-only records. Именно по этой причине такие записи содержат поле UndoNxtLSN. Это поле позволяет при откате обойти CLR, проследовав к той записи, на которую оно указывает. Обычно UndoNxtLSN содержит LSN записи, которая расположена в списке записей, описывающем действия данной транзакции, перед той записью, откат которой фиксирует CLR. Поскольку обычно требуется отменить не собственно откат (CLR) а несколько действий транзакции (может быть даже все), то таким образом устраняется потребность в лишней работе. В самом деле, зачем отменять откат (т.е. восстанавливать некоторое действие) если тут же будет отменено и само это действие, что вернет нас на исходные позиции. Однако поле UndoNxtLSN CLR-записи не всегда используется именно таким образом. Забегая вперед, заметим, что исключением является случай, который возникает при реализации аппарата Nested Top Actions (NTA).
Последнее поле, котором следует упомянуть, это поле Data. В зависимости от типа записи оно содержит информацию, необходимую при восстановлении или откате. Обычно это самое длинное поле записи журнала, содержащие информацию непосредственно из базы данных (например, это может быть образ объекта до и после его изменения).
После обсуждения структуры записей журнала, мы можем объяснить то, как в ARIES отслеживаются состояния страниц базы данных. Когда мы говорим о состоянии страницы БД, нас интересует, главным образом, попали ли в нее изменения, описанные в журнале. Чтобы обеспечить возможность выяснить это, в каждую страница помещается LSN (будем называть его page_LSN) записи, которая описывает последнее изменение, внесенное в эту страницу. Сравнивая page_LSN со значениями LSN записей журнала можно выяснить, были ли внесены изменения, описываемые данной записью журнала, в страницу или же нет.
Вся эта информация необходима во время восстановления после сбоя. Вообще говоря, ARIES довольно детально описывает процесс восстановления. Возможно, именно эффективный способ восстановления стал главным фактором популярности ARIES. Поэтому обратимся к устройству системы восстановления. Но перед этим нам нужно рассмотреть еще несколько структур данных, поддерживаемых во время работы СУБД по алгоритму ARIES.
4. Дополнительные структуры данных
Первой такой структурой является таблица транзакций (transaction table). Эта таблица содержит информацию обо всех незавершенных транзакциях, которые существуют в данный момент в системе. Таблица транзакций также используется при установке контрольных точек и восстановлении. Элемент таблицы содержит поля TransID (идентификатор транзакции) и LastLSN - LSN последней записи, помещенной в журнал этой транзакцией.
Кроме того, элемент таблицы транзакций содержит поля State и UndoNxtLSN. В первом поле хранится статус транзакции - prepared или unprepared. Рассматривается общий случай, когда данная транзакция может являться участницей некоей распределенной транзакции. Тогда то, что транзакция находится в состоянии prepared, означает, что она готова зафиксировать все требуемые изменения и ждет подтверждения от инициатора распределенной транзакции (составной частью которой она являлась), чтобы завершить работу. В тоже время такая транзакция должна сохранять ряд блокировок, чтобы быть в состоянии быстро откатиться в случае неудачного завершения распределенной транзакции. Статус unprepared характеризует то состояние, когда транзакция находится в процессе работы и еще не готова к завершению.
Как можно использовать такую информацию? Дело в том, что в случае сбоя транзакцию, находившуюся в этот момент в состоянии unprepared, скорее всего во время восстановления придется откатить. Но если транзакция находилась в момент сбоя в состоянии prepared, то может оказаться так, что она должна быть восстановлена и завершена. Это происходит в том случае, если инициатор транзакции все еще ждет от нашей БД завершения ее части распределенной транзакции.
Теперь вернемся к полю UndoNxtLSN. В этом поле элемента таблицы транзакций содержится LSN следующей записи журнала, которую необходимо обработать при откате. В случае, когда последняя запись не является CLR-записью, это значение совпадает с LastLSN. Если же последняя журнальная запись транзакции компенсационная, то это значение будет браться из одноименного поля CLR-записи.
Еще одним важным преимуществом ARIES является то, что алгоритм не накладывает фактически никаких ограничений на политику, используемую менеджером буферизации (кроме требования поддержки упреждающей журнализации). Вся необходимая для восстановления информация собирается на основе данных журнала. Но если конкретная политика буферизации неизвестна, во время восстановления потребуется некоторая дополнительная информация о состоянии страниц БД. Эта информация содержится в таблице "грязных" страниц (dirty pages table). Уточним, что имеется в виду. Страница буферного пула называется "грязной", если она содержит какие-либо изменения, еще не внесенные в тот вариант этой страницы, который располагается во внешней памяти. Чтобы отслеживать такие страницы, менеджер буферизации и поддерживает таблицу грязных страниц.
Каждый элемент этой таблицы содержит пару значений: PageID и RecLSN. PageID - это идентификатор страницы, а RecLSN - LSN, используемый при восстановлении. Зная это значение, мы можем установить, с какого LSN нужно просматривать журнал, чтобы восстановить страницу с данным PageID. В конкретной реализации таблица грязных страниц может быть организована с использованием хеширования.
5. Параллельная природа ARIES
ARIES был спроектирован для оптимальной работы в условиях параллельной среды, как в нормальном режиме, так и в режиме восстановления. Применительно к первому режиму это в первую очередь означает наличие развитой системы управления транзакциями.
В условиях одновременной работы множества транзакций необходимо позаботиться о том, чтобы данные оставались согласованными. Для этого нужно уделить особое внимание совместно доступным объектам БД. В большинстве СУБД в качестве средства контроля согласованности данных информации используются блокировки (locks). В ARIES наряду с ними также используется механизм легких семафоров (latches). Различие между ними главным образом функциональное. Блокировки используются для контроля логической согласованности данных, в то время как легкие семафоры являются средством контроля физической согласованности. Установка легкого семафора является гораздо более дешевой операцией, чем установка блокировки. Также легкие семафоры обычно удерживаются на гораздо меньших промежутках времени, нежели блокировки. Еще одно важное различие этих двух способов контроля согласованности данных информации заключается в том, что система обнаружения тупиков не получает информацию о работе легких семафоров. Т.е. их можно использовать лишь в том случае, когда имеется абсолютная уверенность в том, что они не станут причиной возникновения тупика.
Для обеспечения максимального использования возможностей параллельной работы во время восстановления ARIES позволяет восстанавливать каждую страницу базы данных в отдельности. Это свойство обеспечивается наличием на каждой странице поля PageLSN. Как уже говорилось, это поле содержит LSN записи журнала, которая описывает последнее изменение, внесенное в эту страницу. Таким образом, при восстановлении можно сразу определить, какие действия над этой страницей должны быть повторены. Поскольку ARIES на одной из первых стадий восстановления повторяет все действия, произведенные над БД к моменту сбоя, нужно просто применить к данной странице все изменения, для которых LSN которых в журнале больше, чем PageLSN.
6. Контрольные точки
Теперь перейдем к описанию устройства системы восстановления в ARIES.
Обычно различают три вида сбоев: сбой транзакции, при котором по каким-то причинам транзакция не может завершиться, и ее требуется откатить; сбой системы (мягкий сбой), при котором теряется содержимое буферов основной памяти, и требуется восстановить базу данных на основе журнальной информации; и наконец, жесткий сбой, при котором теряются один или несколько жестких дисков. В последнем случае восстановление происходит на основе архивной копии базы данных и журнала. Здесь мы будем рассматривать только восстановление после мягких сбоев.
Как и в большинстве случаев, восстановление в ARIES основывается на механизме контрольных точек. Контрольные точки нужны для того, чтобы уменьшить тот объем журнала, который нужно будет обработать при восстановлении. Во многих СУБД при установке контрольной точки существенно изменялся режим работы системы. Например, в System R для этого временно прекращалась инициация новых транзакций, система дожидалась завершения работы всех операций всех транзакций и выталкивала буфера основной памяти на диск.
Ясно, что это очень дорогой способ создания контрольных точек. Ведь система фактически становится недоступной для пользователей на существенный промежуток времени. В ARIES контрольные точки устанавливаются асинхронно, не приостанавливая работу СУБД. Более того, установка контрольной точки не требует сброса буферов памяти. Таким образом, пользователи системы не испытывают никаких неудобств, связанных с контрольными точками, которые, кстати говоря, надо устанавливать довольно часто.
Итак, что же представляет собой контрольная точка в ARIES? Это всего лишь множество специфических записей журнала. Создание контрольной точки начинается с добавления в журнал записи begin_chkpt, а завершается добавлением записи end_chkpt. Запись end_chkpt содержит копии таблицы транзакций и таблицы грязных страниц, в также некоторую добавочную информации. Для простоты будем полагать, что все эти сведения содержатся в одной записи. После того, как запись end_chkpt добавлена в журнал, LSN первой записи (begin_chkpt) заносится в специальное место, называемое главной записью (master record). Обычно контрольные точки устанавливаются в процессе нормальной работы, но в принципе возможны случаи, когда требуется установка контрольной точки во время восстановления. Это нужно в том случае, если ожидаются сбои во время работы системы восстановления. Тогда механизм контрольных точек позволит сохранить ту работу, которая была совершена на этом этапе. Как будет видно далее, установка контрольных точек в таком режиме фактически не будет отличаться от их установки при нормальной работе.
7. Схема восстановления
Процесс восстановления в разных системах выглядит похожим образом. Сначала проходит стадия анализа, во время которой на основе журнальной информации собираются сведения, необходимые для восстановления. В основном эта работа связана с определением тех транзакций, действия которых необходимо повторить, и тех, действия которых нужно отменить. После этого следуют стадии повторения и отмены. Обычно во время повторения в базу данных вносятся все изменения, которые были внесены в нее транзакциями, успевшими к моменту сбоя завершиться, а отмена соответственно заключается в том, чтобы отменить действия, совершенные транзакциями, нуждающимися в откате. В ARIES имеется некоторое отличие от этой схемы, а именно то, что на стадии повторения ARIES повторяет все действия, которые были отражены в журнале к моменту сбоя. То есть после этой стадии база данных находится в том же состоянии, в каком она была во время сбоя. После этого уже происходит откат всех незавершенных транзакций.
Опишем схему восстановления ARIES более детально. Для этого приведем псевдокод, описывающий процесс восстановления в виде процедуры.
restart (masteraddr)
{
restartanalysis (masteraddr, transtable, dirtypages, redoLSN);
restartredo (redoLSN, transtable, dirtypages);
Инициализировать системную таблицу грязных страниц данными из
таблицы dirtypages, созданной на двух первых этапах;
Удалить из этой таблицы все записи, соответствующие тем страницам, которые
были сброшены на диск;
restartundo (transtable);
Восстановить блокировки для транзакций, находившихся в состоянии prepared;
checkpoint ();
}
Сначала следует стадия анализа. На этой стадии, на основе записей последней контрольной точки воссоздаются таблицы транзакций и грязных страниц. Еще одно значение, получаемое на этой стадии, - redoLSN. Это номер записи журнала, начиная с которой будут повторяться действия над базой данных во время следующего этапа восстановления. Единственный тип записей, которые добавляются в журнал во время стадии анализа, - это записи о завершении откатов транзакций, которые уже завершили откат к моменту сбоя, но не успели зафиксировать этот факт в журнале.
Далее на стадии повторения просматривается журнал, и в таблицы, загруженные из записей контрольной точки, вносятся изменения. В конце этой стадии таблица транзакций и таблица грязных страниц фактически приходят в то состояние, в котором они находились на момент сбоя. После этого redoLSN вычисляется как минимум из RecLNS, содержащихся в таблице грязных страниц.
Вообще говоря, не обязательно требуется оформлять стадию анализа в качестве отдельного прохода. Поскольку в ARIES на стадии повторения в любом случае вносятся все недостающие изменения вне зависимости от того, придется ли их потом откатывать или нет, информация, собранная во время анализа, может потребоваться лишь на этапе отмены (undo). Таким образом, стадии повторения и анализа можно совместить.
После завершения этих двух этапов системная таблица грязных страниц мы инициализируется тем вариантом таблицы, который получился в результате проделанной работы. Далее из нее удаляются записи о тех страницах, которые уже попали во внешнюю память. Начиная с этого момента, таблица грязных страниц поддерживается менеджером буферизации в автоматическом режиме. И лишь после этого происходит стадия отката.
На этой стадии откатываются те транзакции, которые в существенной степени не успели завершиться к моменту сбоя. Откат всех таких транзакций происходит за один просмотр журнала. LSN следующей записи журнала, подлежащей откату, вычисляется как максимум из всех номеров записей, которые были созданы откатываемыми транзакциями. То есть откат действий этих транзакций происходит в обратном хронологическом порядке.
Выше была описана обычная схема восстановления. В ней восстановление происходит в режиме offline. Это означает, что пользователям СУБД придется дожидаться окончания процесса восстановления, прежде чем они смогут продолжить работу с базой данных. Поэтому вполне естественно стремление сократить промежуток времени после сбоя, в течение которого система недоступна. Для этого можно разделить все объекты базы данных на два класса в соответствии с их важностью. Объекты первого класса восстанавливаются в первую очередь, чтобы позволить СУБД инициировать новые транзакции для работы над ними как можно скорее. Восстановление же объектов второго класса можно несколько отложить во времени, поскольку они менее важны. Это свойство поддерживается во многих алгоритмах восстановления. ARIES также допускает модификацию, позволяющую реализовать такую схему восстановления. Более подробно этот вопрос освещен в [4].
8. Другие возможности ARIES
Рассмотрев работу системы восстановления, обратим внимание на ряд других интересных свойств ARIES. Из них, наверное, самое изящное и простое в исполнении, это поддержка Nested Top Actions (NTA). Объясним значение этого термина.
Иногда требуется зафиксировать некоторые изменения, произведенные транзакцией над базой данных, вне зависимости от того, каким образом она завершится. Такие изменения не будут отменены даже в случае отката всей транзакции. Для подобных действий также требуется соблюдение свойства атомарности.
В качестве примера рассмотрим транзакцию, в ходе которой требуется произвести расширение некоторого файла. После выполнения расширения другие транзакции также могут добавлять данные в новую область файла. Причем это может происходить еще до завершения первой транзакции. Поэтому в случае отката изначальной транзакции нельзя отменять действия по расширению файла, поскольку это может привести к потере данных. При этом для самого расширения требуется поддержка свойства атомарности. То есть в случае сбоя во время выполнения действий по расширению файла должны иметься возможность восстановить этот файл базы данных в первоначальном виде.
Традиционно, такого рода действия совершались путем запуска независимых транзакций, называемых заключительными действиями (top actions). При этом транзакция-инициатор ожидала завершения порожденной транзакции перед тем как продолжить работу. Однако этот путь связан с некоторыми неудобствами, главным из которых является уязвимость этого механизма по отношению к тупикам, вовлекающих в себя первую и вторую транзакции.
В ARIES используется концепция вложенных заключительных действий (nested top actions). Она позволяет обойтись без запуска независимых транзакций в рассматриваемых случаях. Вложенное заключительное действие представляет из себя последовательность действий транзакции, которая по завершению уже не подлежит отмене даже в случае отката объемлющей транзакции.
Технически организация NTA проходит в три этапа. На первом этапе запоминается LSN последней журнальной записи текущей транзакции. На втором - записывается информацию, необходимую для повторения и отката NTA. И на третьем шаге записывается фиктивная компенсационная запись (dummy CLR), поле UndoNxtLSN которой указывает на запись журнала, запомненную на первом шаге. В результате, при откате этой транзакции все действия NTA будут пропущены. При этом в случае сбоя, произошедшего до окончания NTA, все действия вложенного заключительного действия будут отменены в ходе восстановления.
Описывая процесс создания NTA, мы предполагаем, что все действия типа создания файла и внесения соответствующей системной информации фиксируются во внешней памяти до того, как в журнал попадает фиктивная компенсационная запись.
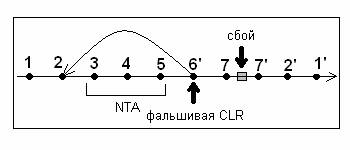
Приведенный ниже рисунок иллюстрирует схему работы NTA. На нем изображены журнальные записи, созданные одной транзакцией. Записи, номера которых помечены штрихом, являются компенсационными. При этом, если 1 - запись журнала, то 1' будет компенсационной для нее. Записи 3, 4 и 5 на рисунке образуют NTA. Как видно, компенсационная запись 6' не имеет пары. Это объясняется тем, что ее единственное назначение - фиксировать изменения, внесенные NTA. Далее на рисунке показано, какие действия будут отменены при откате транзакции после сбоя, произошедшего после завершения NTA. Все шаги, совершенные NTA, не будут отменены, поскольку поле UndoNXT фальшивой CLR 6' указывает на запись 2.