|

2010 г.
Адаптивные системы и модели времени выполнения
Сергей Кузнецов
Обзор октябрьского 2009 г. номера журнала Computer (IEEE Computer Society, V. 42, No 10, Октябрь, 2009).
Авторская редакция.
Также обзор опубликован в журнале "Открытые системы"
Темой октябрьского номера в этом году является использование моделей во время выполнения программ («models@run.time»). Этой теме посвящены пять больших статей и развернутая вводная заметка приглашенных редакторов, которыми на этот раз являются Гордон Блейр, Нелли Бенкомо и Роберт Франс (Gordon Blair, Lancaster University, Nelly Bencomo, Robert B. France, Colorado State University). Редакторская заметка так и называется «Models@run.time».
От современных критически важных программных систем часто требуется надежная адаптация к изменениям среды их исполнения. Критическая значимость таких систем зачастую не позволяет адаптировать их в режиме офлайн. При возможности требуется адаптация их поведения во время исполнения с отсутствием или минимизацией вмешательства человека.
Исследования в области адаптивных (self-adaptive) систем привели к ряду важных результатов, однако многие проблемы остались нерешенными. Одна из наиболее сложных проблем касается сложности, которая порождается обилием информации, связанной с процессом выполнения программ. Перспективным подходом, позволяющим справиться со сложностью сред выполнения, является разработка механизмов, основанных на использовании моделей программного обеспечения. Этот подход называется использованием моделей во время выполнения программ (models@run.time). Исследования в этом направлении направлены на применение в средах выполнения программ моделей, получаемых при использовании подхода управляемой моделями инженерии (model-driven engineering, MDE).
В MDE модель представляет собой абстракцию, или упрощенное представление системы, создаваемое для специальных целей. Например, технологически независимые модели программного обеспечения описывают приложения с использованием понятий, абстрагирующих имеющиеся компьютерные технологии. В сообществе models@run.time применяется аналогичное понятие модели, и ищутся пути применения моделей во время выполнения программ.
Полезно сопоставить это направление исследований с работами прошлых лет в области рефлексии. Специалисты этой области стремятся к выработке представлений систем, являющихся их «автопортретами» (self-representation) и причинно-следственно связанных с ними. Другими словами, модель должна постоянно и точно представлять текущее состояние и поведение системы. При изменении системы должна изменяться модель, и наоборот, изменение модели должно приводить к изменению системы.
Одна из основных задач направления models@run.time состоит в нахождении соответствующих «автопортретов». Существенно, что такие представления должны быть причинно-следственно связаны с системами. Для адаптивных систем это важно по двум причинам:
- на основе модели должно быть возможно получить актуальную и точную информацию о системе, позволяющую принимать решения о ее последующей адаптации;
- если модель причинно-следственно связана с системой, то адаптацию можно производить на уровне модели, а не системы.
Из этого можно было бы заключить, что models@run.time является синонимом рефлексии, но это неверно. В области рефлексии пытаются найти модели, внутренне связанные с моделью вычислений. Обычно эти модели основываются на пространствах решений и часто представляются на низком уровне абстракции, где, например, раскрывается процесс передачи сообщений, и поддерживаются метаоперации, такие как перехват сообщений.
В походе models@run.time ищутся модели, представляемые на гораздо более абстрактном уровне, в частности, причинно-следственные модели, относящиеся к пространству задач. Еще одним отличием является то, что такие модели должны быть внутренне привязаны к моделям, производимым в качестве артефактов процесса MDE, и поэтому они должны ассоциироваться с соответствующими методологиями инженерии программного обеспечения. Этот важный симбиоз с пользой применяется в области распределенных систем, где имеется подобная строгая связь между разработкой с применением распределенных объектов, например, в архитектуре Corba, и ассоциированными объектно-ориентированными методологиями инженерии программного обеспечения, основанными на UML.
Тем самым, подход models@run.time основывается на рефлексии, но ориентирован на перемещение работы из пространства решений в пространство задач, что аналогично тому влиянию, которое оказывают на MDE методологии инженерии программного обеспечения. Это приводит к следующему определению: model@run.time – это цельное представление системы, ассоциируемое с ней причинно-следственными связями, в котором акцентируются структура, поведение и цели этой системы с точки зрения пространства задач.
Модели этапа разработки (производимые в процессе MDE) – это модели программного обеспечения на уровнях абстракции выше уровня кода; эти модели обычно отражают смысл разработки программного обеспечения. Примерами являются модели сценариев использования, архитектурные модели и модели развертывания. Эти модели ассоциируются с сущностями, с которыми приходится иметь дело в цикле разработки программного обеспечения. В отличие от этого, в моделях времени выполнения обеспечиваются абстракции процесса исполнения программного обеспечения, и разные заинтересованные лица могут использовать их разными способами.
Как и в случае традиционных моделей этапа разработки, в моделях времени выполнения поддерживаются рассуждения. Эти модели также могут использоваться для поддержки динамического мониторинга состояния систем и управления ими в процессе выполнения. Кроме того, в модели времени выполнения потенциально могут поддерживаться средства семантической интеграции разнородных компонентов программного обеспечения в области систем систем (system of systems), например, динамически адаптивные метамодели. Модели времени выполнения могут помочь при автоматической генерации реализационных артефактов, помещаемых в систему во время ее выполнения (иногда даже самой этой системой).
В более отдаленной перспективе можно предвидеть использование моделей времени выполнения для устранения ошибок разработки или для внедрения в работающие системы новых проектных решений. Для этого могут потребоваться существенно более сложные механизмы. С другой стороны, эти механизмы смогут поддерживать непредвиденные изменения, представляющие одну из основных проблем адаптивных систем.
Потенциальная поддержка models@run.time для эволюционной разработки программного обеспечения может стереть границу между моделями этапа разработки и времени выполнения. С этой точки зрения, модель времени выполнения может представляться как «живая» модель этапа разработки, делающая возможными динамическую эволюцию и реализацию программных разработок.
Модели времени выполнения могут поддерживать принятие решений об адаптации людьми, например, администраторами систем, с применением адаптационных агентов. Имеется тенденция ко все большей автоматизации принятия решений по поводу адаптации систем, что демонстрируется стремлением к самоуправляемому компьютингу, где агенты могут научиться соответствующим стратегиям эффективного управления системами. Подход models@run.time вносит важный вклад в развитие этой технологии, обеспечивая метаинформацию для автономного принятия решений.
Наконец, полезно обратить внимание на особенности современных процессоров, включая многоядерные архитектуры, производительность которых позволяет одновременно поддерживать много разных абстракций. Например, в сообществе виртуализации отмечается, что на таких процессорах могут сосуществовать до сотни виртуальных машин с потенциально разными операционными системами. Таким же образом эта технология может позволить одновременно выполнять системы и модели систем без чрезмерного неблагоприятного влияния на производительность системы в целом.
Моделью может служить любое полезное представление системы, и неудивительно, что для поддержки models@run.time изыскиваются самые разнообразные методы. К числу основных вариантов выбора относится следующее:
- Структурные и поведенческие модели. В сообществе рефлексии в моделях отражается либо структура систем, либо их более динамичные поведенческие аспекты. В структурных моделях основное внимание уделяется конструкции системы, например, если говорить в терминах объектов, связям наследования и путям вызовов, компонентам и их связям и т.д. В отличие от этого, в поведенческих моделях отражается то, как выполняется система в терминах потоков событий, путей обработки событий и т.д.
- Процедурные и декларативные модели. В процедурных моделях фиксируются реальные структуры или поведение системы (ее «гайки и болты»). Декларативные модели могут строиться, например, на основе целей системы. Естественно, что ориентация моделей на пространство задач делает более предпочтительными декларативные модели.
- Формальные и неформальные модели. Некоторые модели создаются под влиянием вычислительной математики, другие порождаются на основе анализа моделей программирования или абстракций предметной области. Преимуществом формальных моделей является возможная поддержка автоматических рассуждений о состоянии систем, но, в то же время, они не позволяют достаточно простым образом фиксировать или выражать требуемые понятия предметной области.
На практике для моделирования различных аспектов систем, вероятно, потребуется сосуществование нескольких моделей разных стилей.
Публикации этого номера журнала и многие другие показывают, что текущие исследования в направлении models@run.time фокусируются на структурах программного обеспечения и их процедурном представлении. Например, во многих случаях подходящим базисом для построения моделей времени выполнения считается архитектура программного обеспечения.
Авторы заметки полагают, что модели времени выполнения способны на большее. Они считают, что можно было бы поднять уровень абстракции этих моделей до уровня требований. Например, интересной и перспективной темой исследований являются механизмы отслеживания соблюдения требований и целей программных систем во время их выполнения.
Эту тему принято называть рефлексией требований. Для достижения подобной возможности модель требований к системе должна поддерживаться при ее выполнении, т.е. быть моделью времени выполнения. Понятно, что в этом случае гораздо труднее поддерживать причинно-следственные связи между моделью и выполняемой системой, но, по мнению авторов, это является важнейшей исследовательской проблемой, решение которой потенциально принесет громадную пользу.
Среди других проблем авторы выделяют следующее:
- Насколько отличаются современные технологии, используемые в процессе разработки программного обеспечения, от методов синтеза, требуемых при использовании моделей времени выполнения? Пригодны ли эти технологии для синтеза динамических моделей?
- Насколько методы и стандарты определения семантики пригодны для автоматической интерпретации во время выполнения?
- Как можно добиться обратимого преобразования моделей для синхронизации модели времени выполнения с выполняемой системой, а также моделей этапа разработки с моделями времени выполнения?
- Какие модели времени выполнения годятся для представления сверхкрупномасштабных систем, учитывая их внутреннюю сложность и наличие неопределенности?
- Какие последствия имеет подход models@run.time для инженерии программного обеспечения, и может ли он стимулировать радикальный пересмотр понятий разработки программного обеспечения?
- Могут ли модели времени выполнения обеспечить поддержку анализа программного обеспечения в стиле «что, если» и предоставить возможность непредвиденных изменений?
Эти вопросы обозначают всего лишь несколько отправных точек в исследованиях этой увлекательной темы, которые могут привести к результатам, чрезвычайно полезным для инженерии программного обеспечения.
Первая регулярная статья тематической подборки называется «Использование основанных на моделях трасс в качестве моделей времени выполнения» («Using Model-Based Traces as Runtime Models»). Ее написал Шахар Маоц (Shahar Maoz, Weizmann Institute of Science).
В трассах, основанных на моделях, информация о выполнении системы сохраняется с использованием абстракций тех моделей, которые использовались при разработке системы. Эти трассы включают обильную семантическую информацию о системах, для которых они генерировались, о моделях, на основе которых они выводились, и о связях между системами и моделями, раскрывающихся во время выполнения. С использованием трасс, основанных на моделях, специалисты могут во время выполнения системы отслеживать модели этапа ее разработки, такие как диаграммы последовательностей, диаграммы классов и диаграммы состояний.
Метрики и операции трасс, основанных на моделях, можно использовать как инструменты для получения подробных сведений о структуре и поведении выполняемой системы на уровне абстракции, соответствующем моделям этой системы этапа разработки. Если придерживаться классификации моделей на модели этапа разработки и модели времени выполнения, то трассу выполнения системы можно считать моделью времени выполнения системы, для которой она генерировалась. В трассе сохраняется информация о выполнении системы на некотором уровне детализации; следовательно, ее можно рассматривать как некоторое абстрактное представление – артефакт, моделирующий некоторые аспекты системы. Как и любая другая модель, трасса выполнения представляет информацию о системе с некоторой точки зрения, и в ней опускается другая информация.
Трассу как модель следует формально описывать с использованием некоторого языка моделирования с правильно определенными синтаксисом и семантикой. При наличии точного синтаксиса специалисты могут проверять правильность построения, или синтаксическую корректность трассы. Семантику трассы можно определять на двух уровнях: на уровне ее представления конкретного прогона системы, на основе которого она генерировалась, и, в более общем смысле, на уровне представления набора систем (и набора их прогонов), для которого генерировалась трасса. При наличии семантики специалисты могут проверять, согласуется ли синтаксически корректная трасса с конкретным прогоном (является ли данное представление корректным?), или, в более общем смысле, является ли данная трасса реализуемой, т.е. существует ли система (и некоторый ее прогон), для которого данная трасса генерировалась.
Трассы исследуются и изучаются с использованием различных метрик и операций. Они могут подвергаться различным преобразованиям, обладать текстовым и графическим представлением и сравниваться с другими трассами. В целом, свойства трасс как моделей обеспечивают возможность получения детальной информации о структуре и поведении моделируемой системы, информации, которая может способствовать решению ряда задач инженерии программного обеспечения (тестирования, понимания, развития программных систем и т.п.).
Статью «Самоуправляемый компьютинг на основе повторного использования моделей изменчивости во время выполнения: пример интеллектуального дома» («Autonomic Computing through Reuse of Variability Models at Runtime: The Case of Smart Homes») представили Карлос Цетина, Пау Гинер, Жоан Фонс и Виценте Пелечано (Carlos Cetina, Pau Giner, Joan Fons, Vicente Pelechano, Polytechnic University of Valencia, Spain).
Понятие самоуправляемого компьютинга (Autonomic Computing, AC) предполагает создание компьютерных сред, развивающихся без потребности во вмешательстве человека. Система, обладающая возможностями самоуправления, сама инсталлирует, конфигурирует, настраивает и обслуживает свои компоненты во время работы. Основной проблемой AC является определение соответствующих абстракций и моделей для понимания самоуправляемого поведения, его контролирования и разработки. В ряде исследований удалось получить результаты, обеспечивающие основные возможности самоуправления, такие как самоконфигурирование с использованием укрепляющего обучения (reinforcement learning) и самоадаптация с использованием основанных на сетях Петри и адаптивных моделей. Однако практическое применение этих возможностей чрезмерно усложняет результирующие системы и методы их производства.
Отличаясь от предыдущих исследований и, в то же время, дополняя их, работа авторов фокусируется на средах массового производства, используемых, например, при создании автомашин или домов, где основным ограничением является стоимость производства. Сокращение стоимости производства возможно за счет ограничения уровня индивидуализации продуктов – например, при покупке автомобиля можно выбрать желаемый цвет, но только из ограниченной палитры. В указанных областях такой компромисс является допустимым, поскольку необходимо удовлетворить средние запросы, а не индивидуальные потребности каждого заказчика.
В областях массового производства весьма полезными оказываются модели изменчивости (Variability Model), позволяющие максимизировать повторное использование компонентов при разработке набора схожих программных систем (семейства систем). Поскольку общие части систем (компоненты, модели, средства разработки, документация и т.д.) отчетливо опознаются, в начале каждой новой разработки можно выявить возможности повторного использования.
Работа авторов показывает, что самоуправляемого поведения можно достичь за счет использования моделей изменчивости во время выполнения. Таким образом, работа по моделированию системы, проделанная во время разработки, оказывается не только полезной для производства этой системы, но также обеспечивает семантическую основу для поддержки самоуправляемого поведения во время выполнения. Использование моделей изменчивости во время выполнения обеспечивает новые возможности самоуправления за счет повторного использования результатов работы, выполненной на этапе разработки.
В предлагаемом подходе существенны два аспекта:
- Повторное использование знаний этапа разработки для обеспечения самоуправляемости. Знания, зафиксированные в моделях изменчивости, повторно используются для описания вариантов возможного развития системы. При изменении контекста система сама обращается к этим моделям для определения необходимых изменений в своей архитектуре.
- Повторное использование существующих технологий управления моделями во время выполнения. Во время выполнения используются модели этапа разработки без каких-либо изменений, т.е. во время выполнения применяется то же представление, что и на этапе разработки: стандарт XML Metadata Interchange. Это позволяет избежать потребности в технологических мостах за счет применения одной и той же технологии манипулирования моделями, представленными в формате XML.
Для реализации операций управления моделями авторы разработали механизм Model-Based Reconfiguration Engine (MoRE). Эти операции позволяют определить, как следует изменяться системе, и какие механизмы следует использовать для соответствующего изменения архитектуры. Таким образом, знания, зафиксированные в моделях изменчивости, используются в качестве политик, управляющих автономной эволюцией системы во время выполнения.
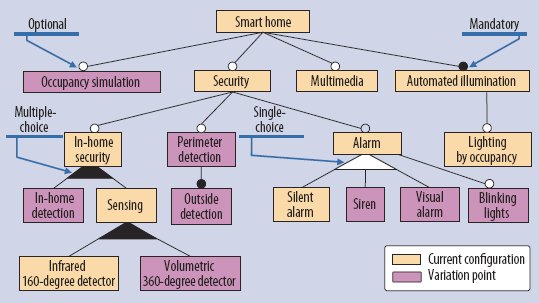
Модель элементов интеллектуального дома. Элементы иерархически связаны в древовидную структуру связями изменчивости
Разработанный авторами подход применялся в области интеллектуальных домов (www.autonomic-homes.com). Эта прикладная область хорошо подходит для применения методов моделирования изменчивости, поскольку между разными системами имеется большое сходство. Кроме того, возможности AC могут помочь преодолеть некоторые ограничения этой области, такие как минимальная поддержка эволюции при появлении новых технологий. Выполненные исследования демонстрируют применимость этого подхода для интеллектуальных домов, в особенности, для обеспечения возможностей самовосстановления и самоконфигурирования.
Авторами статьи «Применение подхода models@run.time для поддержки динамической адаптации» («Models@run.time to Support Dynamic Adaptation») являются Брис Морин, Оливер Бараис, Жан-Марк Жезекель, Франк Флюрель и Арнор Солберг (Brice Morin, INRIA, Olivier Barais, Jean-Marc J?z?quel, INRIA and IRISA, University of Rennes, Franck Fleurey, Arnor Solberg, arnor.solberg@sintef.no, SINTEF ICT).
Современное общество все более зависит от программных систем, развернутых в крупных компаниях, банках, аэропортах и т.д. Эти системы должны быть доступны в режиме 24/7 и должны адаптироваться к изменениям условий среды и требований. Такие динамически адаптивные системы (Dynamically Adaptive System, DAS) обладают изменчивостью, уровень которой зависит от потребностей пользователей и изменений контекста во время выполнения. Специалисты могут разрабатывать DAS путем определения нескольких точек изменчивости. В зависимости от контекста система динамически выбирает варианты, пригодные для реализации этих точек изменчивости. Эти варианты могут обеспечивать улучшенное качество обслуживания (Quality of Service, QoS), предоставлять новые сервисы, которые не имели смысла в предыдущем контексте, или исключать некоторые сервисы, которые более не являются полезными.
Категория DAS весьма обширна и включает как небольшие встраиваемые системы, так и крупные системы систем, как системы, управляемые человеком, так и полностью самоуправляемые системы. Можно представлять DAS, как динамическую линейку программных продуктов (Dynamic Software Product Line, DSPL), в которой изменчивость проявляется во время выполнения. Аналогично традиционным SPL, число возможных конфигураций в DSPL комбинаторно возрастает в зависимости от числа точек изменчивости и вариантов. В SPL продукты производятся в соответствии с решениями людей и являются полностью независимыми. В отличие от этого, в DSPL должно поддерживаться управление путями миграции между возможными конфигурациями.
Таким образом, конфигурации, производимые в DSPL, являются чрезвычайно зависимыми: система должна во время выполнения изменить свою текущую конфигурацию на некоторую новую конфигурацию через некоторый безопасный путь миграции (переход). Эти переходы инициируются несколькими стимулами: изменением контекста, предпочтениями пользователей и т.д. В DSPL должны поддерживаться средства описания логики адаптации.
На абстрактном уровне выполнение DSPL можно представить в виде сильно связанной машины состояний, в которой состояниями являются возможные конфигурации системы, а переходами – пути миграции. Полная спецификация этой машины состояний дает возможность разработчикам производить масштабную симуляцию, валидацию и тестирование динамической изменчивости системы до ее реальной реализации. Методы MDE обеспечивают возможность полностью сгенерировать код адаптивных систем на основе спецификации машины состояний.
Однако у этого подхода имеются два серьезных недостатка, связанных с управлением адаптацией и эволюцией:
- Комбинаторный взрыв числа артефактов. Даже если разработчик определяет машину состояний на высоком уровне абстракции, быстро растет число конфигураций и переходов, которые требуется описать. Например, при объединении элементов одной динамической системы управления связями с заказчиками (Dynamic Customer Relationship Management, DCRM) получилось 92160 конфигураций, что привело к 92160 ? 92159 = 8493373,440 возможных переходов. Проблемой может быстро стать валидация этих артефактов: число конфигураций комбинаторно возрастает в зависимости от числа вариантов, и это становится серьезной проблемой при работе с большими системами, включающими большое число точек изменчивости.
- Эволюция адаптивных систем. После развертывания и запуска адаптивной системы она может развиваться на основе новых потребностей пользователей, обнаружения и устранения ограничений или дефектов безопасности. Эволюция адаптивной системы влечет динамическое изменение машины состояний адаптации: добавление и удаление состояний и переходов. Было бы непрактично применять классический подход MDE для генерации всего кода приложения из высокоуровневых спецификаций: систему пришлось бы останавливать и выводить из эксплуатации до тех пор, пока не стало бы возможно развернуть и запустить новую систему (основанную на модифицированной машине состояний). Во многих случаях это недопустимо.
В проекте EU-ICT DiVA (Dynamic Variability in complex, Adaptive systems; www.ict-diva.eu), выполняемом авторами статьи, эти недостатки устраняются за счет использования программных моделей как во время выполнения, так и на этапе разработки адаптивных систем. Авторы опираются на четыре метамодели, поддерживаемые средствами разработки, включая графические и текстовые редакторы, валидаторы и симуляторы, для поддержки моделирования DSPL на этапе разработки. Модели, основанные на этих метамоделях, представляют собой основные данные, с которыми имеет дело инфраструктура времени выполнения, ответственная за динамическую адаптацию компонентных приложений. Эти модели обеспечивают высокоуровневую основу для эффективных рассуждений о значимых аспектах системы и ее окружения, а также предоставляют достаточно подробную информацию для полной автоматизации процесса динамической адаптации. Оказывается возможным изменять спецификации системы в любое время, как до ее первого развертывания, так и во время выполнения.
Следующую статью – «Использование архитектурных моделей для управления адаптацией во время выполнения и ее визуализации» («Using Architectural Models to Manage and Visualize Runtime Adaptation») – представили Джон Джеоргас, Андрэ ван дер Хоек и Ричард Тейлор (John C. Georgas, Northern Arizona University, Andr? van der Hoek, Richard N. Taylor, University of California, Irvine).
Наш мир наполнен адаптивными системами, т.е. системами, которые постоянно отслеживают и изменяют свое поведение в зависимости от того, насколько хорошо оно соответствует операционным целям в текущей среде выполнения. Такие системы обычно представляют собой некоторую комбинацию аппаратных и программных средств, функционирующую под контролем людей. Например, робот, предназначенный для оказания помощи при стихийных бедствиях, частично в удаленном режиме управляется людьми при поиске оставшихся в живых, но он также автономно модифицирует стратегии расхода ресурсов для максимального продления своего времени жизни. Аналогично, атомная электростанция в основном автономно динамически адаптируется, но постоянно контролируется и регулируется людьми.
Все чаще программные приложения разрабатываются как саморегулирующиеся адаптивные системы, т.е. они не только изменяют свое видимое извне поведение при изменении условий своего выполнения, но и производят это в автономном режиме. Хотя имеется много проблем, связанных с проектированием и реализацией этих программных систем, адаптируемых во время выполнения, данная статья посвящается проблеме поддержки когнитивного контроля над их адаптацией.
Не программные адаптивные системы обычно включают специальные механизмы мониторинга и управления, обеспечивающие оператору полную информацию о состоянии, поведении и эволюции системы. Рассмотрим, например, систему управления дорожным движением. Размеры интервалов времени, в которые разрешен выезд на основную дорогу, или через которые переключаются светофоры, обычно являются предопределенными и устанавливаются в соответствии с дорожными условиями и существующим трафиком. Однако это автономное поведение дополняется центром управления, в котором обеспечивается глобальное представление состояния дорожного движения, и операторы которого могут корректировать поведение системы.
В настоящее время эквивалентные механизмы управления программными системами, адаптирующимися во время выполнения, просто отсутствуют. Традиционные механизмы мониторинга и анализа поведения программ оказываются не в состоянии:
- устанавливать, как конфигурация системы влияет на ее поведение в текущем контексте;
- производить анализ исторической информации о структуре и поведении системы;
- поддерживать упреждающее управление поведением системы оператором-человеком.
В результате непрерывный контроль поведения адаптивных программных систем оказывается почти невозможным, затруднено определение причин отказов систем, и даже понимание адаптивного поведения системы, при котором достигаются поставленные цели, возможно только на интуитивном уровне.
Для обеспечения этих возможностей авторы разрабатывают концепцию центра оперативного управления, позволяющего людям понимать программные системы, адаптирующиеся во время выполнения, и управлять ими. При использовании подхода архитектурного управления конфигурациями во время выполнения (Architectural Runtime Configuration Management, ARCM) создается модель, в которой фиксируются конфигурации адаптивной системы и соответствующее поведение, и эта информация представляется в виде исторического графа конфигураций. За счет дополнения этой модели метаданными о процессе адаптации (например, сколько раз использовалась данная конфигурация, или какое время сохранялась эта конфигурация системы) ARCM создает историческую перспективу этого процесса. Операторы могут использовать эту история для понимания поведения системы. Разработчики могут пользоваться ей для совершенствования процесса адаптации. Кроме того, ARCM дает возможность активного управления, позволяющую операторам вручную отменять любую адаптацию и вынуждать систему перейти к любой из уже зафиксированных конфигураций.
Последняя статья тематической подборки называется «Отражения смысла: поддержка моделей времени выполнения, пригодных для проверки» («Mirrors of Meaning: Supporting Inspectable Runtime Models») и написана Тони Герлуфсе, Мадсом Ингструпом и Джеспером Волффом Олсеном (Tony Gjerlufse, Mads Ingstrup, Jesper Wolff Olsen, Aarhus University).
В последние 15 лет появились технологии, ведущие к повсеместному использованию компьютеров. Компьютеры используются в самых разнообразных областях человеческой деятельности. Однако люди чаще всего говорят не о пользе этих технологий, а о том, насколько они ненадежны и несовершенны.
Люди часто обнаруживают аспекты своего взаимодействия с компьютерными устройствами, которые являются непонятными, затрудняющими достижения требуемых целей. Вполне разумные ожидания людей часто оказываются недостижимыми без каких-либо видимых причин. Компьютерным специалистам подобные проблемы могут казаться рутинными, очень легко придти к выводу, что большая часть людей просто не понимает их (и не нуждается в понимании).
Однако при более внимательном рассмотрении становится ясно, что это не так. Часто с теми же проблемами сталкиваются сами специалисты. Начнем, например, с того, как мы действуем при аварийных отказах систем. В большинстве случаев причины отказа просто не выясняются, а выполняется некоторая известная процедура, такая как перезапуск или повторная установка системы в зависимости от серьезности ситуации. В действительности, обнаружение причин неверного поведения системы и выполнение действий, препятствующих повторному возникновению такого поведения, производится только на этапе отладки программ.
Когда возникает аварийный отказ системы, нам часто непонятно, что происходит, кроме как на очень высоком уровне, например, «система повисает каждый раз, когда пытаешься вставить рисунок». Мы не можем сделать внутреннюю работу системы видимой и пригодной для проверки. В результате достаточно полное понимание поведения системы и цепочек причинно следственных связей, приводящих к ее сбою, оказывается нереальным и даже недостижимым. Возможность изучения состояния и поведения программ, а также выполнения экспериментов обеспечивается только инструментальными средствами отладки.
Представим себе, как бы изменилась эта ситуация, если бы программное обеспечение создавалось таким образом, что можно было бы получать данные о его состоянии, структуре и поведении, причем эти данные были бы доступны не только разработчикам, но и пользователям. В последние пять лет авторы изучали способы разработки программных систем, обеспечивающие понимание их выполнения.
Разработчикам предлагается понятным и структурированным образом создавать и раскрывать модель системы времени выполнения, что позволяет им производить системы, пригодные для проверки. Этот подход опирается на то интуитивное ощущение, что за счет поддержки средств изучения системы во время ее выполнения на уровне деталей, требуемых разработчикам, система обеспечит возможности, достаточные и для ее пользователей. Основная используемая модель времени выполнения служит для создания специализированных представлений системы. Для обеспечения возможностей изучения системы во время ее выполнения к архитектуре программного обеспечения и модели программирования выставляются следующие требования:
- пользователи должны иметь возможность понимать работающую систему на уровнях, соответствующих конкретным ситуациям;
- должны поддерживаться разные категории пользователей, от разработчиков до конечных пользователей;
- должен иметься набор более или менее стандартных инструментальных средств визуального представления системы;
- должны поддерживаться разные уровни абстракции и конкретности.
С точки зрения разработки должно выполняться следующее:
- понимание системы во время выполнения должно обеспечиваться ее разработчиками;
- программирование должно быть несложным и должно приносить разработчикам преимущества, по крайней мере, пропорциональные требуемым дополнительным усилиям; модель программирования должна быть достаточно привлекательной, чтобы разработчики ее приняли;
- получаемые системы должны обладать разумной производительностью, быть жизнеспособными и опираться на известные принципы и методы инженерии программного обеспечения;
- эти системы должны быть открытыми и расширяемыми.
Предлагаемый авторами подход опирается на рефлективную структуру данных, называемую H-графом (H-graph, иерархический граф); на ней же основана модель программирования. Не менее важно то, что та же структура данных частично может служить основой модели программирования рефлективного программного обеспечения в целом. Внутри этой модели программирования H-графы обеспечивают основную структуризацию разрабатываемых систем и механизм хранения данных. Модель программирования приблизительно указывает разработчикам способы использования H-графов, которые, в свою очередь, на основе самоанализа обеспечивают основную модель времени выполнения, делающую систему пригодной для проверки.
Вне тематической подборки опубликованы две большие статьи. Кеннет Хосте и Ливен Экхаут (Kenneth Hoste, Lieven Eeckhout, Ghent University) написали статью «Методология анализа показателей производительности коммерческих процессоров» («A Methodology for Analyzing Commercial Processor Performance Numbers»).
Консорциумы и корпорации, производящие эталонное тестирование, публикуют показатели производительности коммерческих компьютерных систем на основе стандартизированных в индустрии эталонных тестовых наборов. Например, Корпорация по оценке производительности вычислительных систем (Standard Performance Evaluation Corporation, SPEC; www.spec.org) предоставляет данные о производительности на основе эталонных тестовых наборов из различных прикладных областей. Эти тестовые наборы имитируют рабочие нагрузки с большим объемом вычислений, Java, графики, Web-серверов, почтовых серверов и сетевых файловых систем. Информация, получаемая на основе этих тестовых испытаний, представляет ценность для сравнения коммерческих машин от разных производителей, с разными процессорами, на разных приложениях при наличии разных видов рабочей нагрузки. Однако избыток данных затрудняет анализ.
Для облегчения анализа этих крупных наборов данных авторы разработали методологию и инфраструктуру анализа показателей производительности с использованием подхода анализа основных компонентов, который позволяет сократить размерность наборов данных. Для иллюстрации мощности предложенной методологии она использовалась для анализа набора данных SPEC CPU2000, включающего показатели производительности, полученные для более чем 1000 машин на 26 эталонных тестовых наборах. Результаты такого статистического анализа визуализируются с применением соответствующего интерактивного инструментального средства, обеспечивающего быструю и интуитивно понятную навигацию по крупным наборам данных о производительности.
Наконец, последняя большая статья октябрьского номера написана Ахмедом Аббаси и Хсинчуном Ченом (Ahmed Abbasi, abbasi@uwm.edu, University of Wisconsin-Milwaukee, Hsinchun Chen, hchen@eller.arizona.edu, University of Arizona.) и называется «Сравнение инструментальных средств для обнаружения поддельных Web-сайтов» («A Comparison of Tools for Detecting Fake Websites»).
Поддельные Web-сайты – это фиктивные, искажающие информацию сайты, которые представляются в виде настоящих поставщиков информации, товаров или услуг и используются для получения незаконных доходов за счет обмана поисковых машин или привлечения доверчивых пользователей Internet. Мошенники создают поддельные сайты нескольких типов, включая Web-спам, искусственно сфабрикованные (concocted) и мистифицирующие (spoof) сайты.

Примеры Web-страниц для трех категорий поддельных Web-сайтов: (a) Web-спам, (b) искусственно сфабрикованный сайт, (c) мистифицирующий сайт
Сайты с Web-спамом направлены на обман поисковых машин для поднятия своего рейтинга. Эти Web-сайты, основанные на методах спама по отношению и контенту, и к ссылкам, применяются в хакерской оптимизации поисковых машин, в результате которой спам-сайты с высоким рейтингом удается продать с большей прибылью. Например, за спам-сайт из области мобильных телефонов, показанный на рисунке слева, просили 350 долларов.
Искусственно сфабрикованные Web-сайты выглядят, как настоящие коммерческие сущности. В центре рисунка показан такой сайт подложного инвестиционного банка Troy Inc. Назначение таких сайтов состоит в обмане доверчивых пользователей, у которых собираются деньги, после чего сайт исчезает. Подобные сайты обычно выглядят как сайты реальных финансовых, торговых и других компаний.
В отличие от этого, мистифицирующие сайты является имитацией реальных коммерческих сайтов и направлены на обман их доверчивых клиентов. Целью таких сайтов является похищение идентификационной информации пользователей за счет того, что их принуждают зарегистрироваться. К числу наиболее часто подделываемых сайтов относятся eBay, PayPal и сайты различных банков.
Поскольку в обнаружении спам-сайтов достигнут значительный прогресс (см. обзор октябрьского номера журнала Computer за 2005 г., в своей статье авторы концентрируются на проблемах обнаружения искусственно сфабрикованных и мистифицирующих сайтов.
Поддельные сайты часто выглядят вполне профессионально, и их трудно распознать по внешнему виду. В ответ на возрастающий уровень осведомленности пользователей злоумышленники становятся все более изощренными, и имеющиеся средства безопасности не справляются со все возрастающей сложностью поддельных сайтов. Возникает потребность в более развитых методах выявления поддельных Web-сайтов. У предложенных ранее инструментов имеется несколько недостатков. Большая их часть включает справочные системы, основанные исключительно на собираемых по информации от пользователей черных списках URL поддельных сайтов. В немногих системах используются упреждающие методы классификации, основанные на упрощенных эвристиках. Кроме того, наибольшее внимание уделяется средствам выявления мистифицирующих сайтов, а искусственно фабрикуемым сайтам уделяется недостаточное внимание, хотя они получают все большую распространенность.
Остается неясным, насколько эффективными были бы существующие инструментальные средства при обнаружении искусственно сфабрикованных Web-сайтов. Поскольку такие сайты не просто имитируют популярные коммерческие Web-сайты, для их успешной идентификации требуется привлечение большего числа методов. Для решения этой проблемы авторы предлагают классифицирующую систему на основе применения метода опорных векторов (Support Vector Machine, SVM), позволяющую выявлять поддельные Web-сайты. Для достижения более высокой эффективности в динамической гибридной системе этот классификатор используется совместно со справочным механизмом.
|
|

 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС
