Темой апрельского номера в этом году являются вычисления над данными большого объема (Data-Intensive Computing). Имеются приглашенные редакторы, представившие объемную вводную заметку. Теме номера посвящены пять из шести основных статей. Заметка приглашенных редакторов, в роли которых на этот раз выступают Ян Гортон, Пол Гринфилд, Алекс Залай и Рой Вильямс (Ian Gorton, Pacific Northwest National Laboratory, Paul Greenfield, Commonwealth Scientific and Industrial Research Organisation, Alex Szalay, Johns Hopkins University, Roy Williams, Caltech), называется «Вычисления над данными большого объема в 21-м веке» («Data-Intensive Computing in the 21st Century»).
В 1998 г. на Седьмом симпозиуме IEEE по высокопроизводительным распределенным вычислениям (7th IEEE Symposium on High-Performance Distributed Computing) Вильям Джонсон (William Johnston) представил доклад, в котором описывалась эволюция вычислений над большими объемами данных в предыдущие десять лет. Достижения, отмечавшиеся в этом докладе, соответствовали уровню технологии тех лет, но они производят скромное впечатление по сравнению с масштабом проблем, с которыми теперь повседневно сталкиваются исследователи при разработке приложений, ориентированных на обработку больших объемов данных.
Позднее в публикациях ряда других исследователей описывалась масштабность тех проблем вычислений над данными большого объема, с которыми сталкивается сегодня сообщество электронной науки (e-science) или столкнется в ближайшем будущем. Эти описания лавины данных, которые должны обрабатываться будущими приложениями в прикладных областях, простирающихся от науки до бизнес-информатики, служат убедительным доводом в пользу проведения исследований и разработок, направленных на создание масштабируемых аппаратных и программных решений проблем вычислений над данными большого объема. Хотя пределом возможностей сегодняшних приложений, ориентированных на обработку больших объемов данных, являются петабайтные наборы и гигабайтные потоки данных, нет сомнений, что еще через десять лет исследователи будут с нежностью вспоминать о проблемах этого масштаба и беспокоиться о трудностях, которые будут возникать при разработке приложений на порядок большего масштаба.
По существу, при создании подобных приложений приходится сталкиваться с двумя основными проблемами: (1) управление и обработка экспоненциально возрастающих объемов данных, которые часто поступают в реальном времени в виде потоков данных от массивов сенсоров или приборов, или генерируются в ходе имитационного моделирования; (2) существенное сокращение времени анализа данных, чтобы исследователи имели возможность своевременного принятия решений.
Несомненно, проблемы обработки больших объемов данных и супервычислений перекрываются. Для классификации пространства приложений в соответствии с потребностью решения этих проблем можно использовать следующую простую диаграмму.
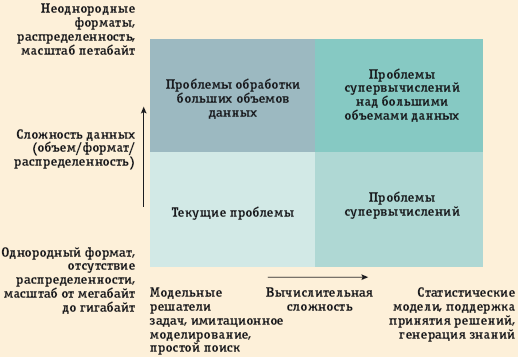
Приложения, ориентированные исключительно на обработку больших объемов данных, имеют дело с наборами данных объемом от нескольких терабайт до петабайта. Как правило, эти данные поступают в нескольких разных форматах и часто распределены между несколькими местоположениями. Обработка подобных наборов данных обычно происходит в режиме многошагового аналитического конвейера, включающего стадии преобразования и интеграции данных. Требования к вычислениям обычно почти линейно возрастают при росте объема данных, и вычисления часто поддаются простому распараллеливанию. К основным исследовательским проблемам относятся управление данными, методы фильтрации и интеграции данных, эффективная поддержка запросов и распределенности данных.
Для приложений, ориентированных на суперобработку больших объемов данных, характерны потребность в обработке сверхбольших наборов данных и возрастающая вычислительная сложность. Требования к вычислениям нелинейно возрастают при росте объемов данных; для обеспечения правильного вида данных требуется применение сложных методов поиска и интеграции. Ключевыми исследовательскими проблемами являются разработка новых алгоритмов, генерация сигнатур данных и создание специализированных вычислительных платформ, включающих аппаратные ускорители.
Исследования в области вычислений над данными большого объема охватывают проблемы, относящиеся к двум верхним квадратам приведенной диаграммы. К числу приложений, которым свойственны соответствующие характеристики, относятся следующие.
Астрономия. Большой обзорный телескоп (Large Synoptic Survey Telescope, LSST) каждый год будет генерировать несколько петабайт новых изображений и каталожных данных. Радиотелескоп Square Kilometer Array (SKA) будет производить около 200 гигабайт необработанных данных в секунду, и для получения подробных радиокарт звездного неба потребуются вычислительные средства петафлопной (а может быть, и экзафлопной) производительности. Для обработки такого объема данных и приведению их к виду, полезному для научного сообщества, требуется решить ряд серьезных проблем.
Компьютерная безопасность. Для предупреждения компьютерных атак, их распознавания и реагирования на них требуются системы обнаружения вторжений, обрабатывающие сетевые пакеты на скоростях в гигабиты в секунду. В идеале такие системы должны обеспечивать выдачу предупреждений о возможной атаке за секунды или хотя бы минуты, чтобы операторы могли успеть защититься от атак, когда они действительно произойдут.
Социальный компьютинг. На таких сайтах, как Internet Archive и MySpace, хранится контент огромного объема, которым необходимо управлять, обеспечивать возможности поиска и доставки результатов пользователям Internet в течение секунд. Инфраструктура и алгоритмы, требуемые для сайтов такого масштаба, представляют собой актуальную и нетривиальную проблему.
Прорывные технологии, требующиеся для решения многих важных проблем вычислений над данными большого размера, могут быть созданы только путем совместных усилий специалистов в нескольких областях, включая компьютерную науку, инженерию и математику. В частности, для решения этих проблем необходимо получить следующее:
• новые алгоритмы, пригодные для обеспечения поиска в огромных наборах данных и их обработки;
• новые технологии управления метаданными, позволяющие работать со сложными, неоднородными и распределенными источниками данных;
• прогресс в области высокопроизводительных вычислительных систем, обеспечивающих единообразный высокоскоростной доступ к многотерабайтным структурам данных;
• специализированные гибридные архитектуры межкомпонентных соединений, позволяющие обрабатывать и отфильтровывать многогигабайтные потоки данных, поступающие из высокоскоростных сетей и научных приборов и симуляторов;
• высокопроизводительные и высоконадежные распределенные файловые системы, способные работать с данными петабайтного масштаба;
• новые подходы к обеспечению мобильности программного обеспечения, позволяющие выполнять алгоритмы в тех узлах, в которых располагаются данные, если перемещение необработанных данных в другие обрабатывающие узлы оказывается слишком дорогостоящим;
• гибкие и высокоэффективные технологии системной интеграции, которые обеспечивают возможность быстрой интеграции программных компонентов, выполняемых на разных компьютерных платформах, для образования аналитических конвейеров;
• методы генерации сигнатур данных для сокращения объема данных и убыстрения их обработки.
Первая «регулярная» статья тематической подборки написана Йонгом Ксю, Веем Ваном, Ингджаем Ли, Джай Гуанг, Линийан Бай, Инг Ванг и Джианвеном Айем (Yong Xue, Wei Wan, Yingjie Li, Jie Guang, Linyian Bai, Ying Wang, Jianwen Ai, State Key Laboratory of Remote Sensing Science) и называется «Количественная выборка геофизических параметров с использованием спутниковых данных» («Quantitative Retrieval of Geophysical Parameters Using Satellite Data»).
Спутниковое дистанционное зондирование обеспечивает своевременную и глобальную информацию и поэтому является эффективным способом мониторинга состояния аэрозолей, что считается важным для исследования влияния радиационного воздействия аэрозолей на изменение климата. Надежные мониторы дистанционного зондирования атмосферы основываются на физических или статистических моделях, имеющих параметры, для которых должна обеспечиваться количественная выборка. Однако количественная выборка – это приложение, требующее обработки больших объемов данных. В результате долговременных широкодиапазонных наблюдений, производимых с высокой степенью разрешения, каждый день генерируется несколько терабайт данных. Для переработки таких гигантских объемов мультисенсорных динамических данных требуется решение нескольких вычислительных проблем.
В качестве типичного примера можно рассмотреть видеоспектрорадиометр со средней разрешающей способностью MODIS (moderate resolution imaging spectroradiometer), который используется датчиками Системы наблюдения Земли (Earth Observing System) для ограничения потребностей в вычислениях и хранении данных, поскольку данные, получаемые от этой системы, широко используются исследователями для изучения атмосферы в глобальном масштабе. Тем не менее, для обработки данных с целью получения количественных параметров аэрозолей за один день требуются 30 частиц изображений MODIS, общий объем которых составляет 13 гигабайт при полном покрытии основной поверхности территории Китая. За 30 дней общие требования к объему памяти, нужной для хранения этих данных, превышают 4 терабайта. Этот пример показывает, что для выборки повседневной и своевременной информации из спутниковых данных требуются новые вычислительные мощности.
Кроме того, в приложениях выборки количественных параметров из данных дистанционного зондирования обычно требуются обработка данных и обратные вычисления. Задачи, выполняемые в потоке обработки данных, могут обладать существенно разной сложностью, разными требованиями к пересылке данных и временем выполнения, что приводит к наличию смешанной рабочей нагрузки с чередованием массивно параллельных задач, для выполнения которых необходимо наличие высокой пропускной способности, и коротких задач, для которых нужно обеспечивать быстрое время ответа.
В Институте приложений дистанционного зондирования (Institute of Remote Sensing Applications, IRSA) Китайской академии наук разработана инфраструктура RSIN (remote sensing information service grid node), поддерживающая выполнение приложений количественной выборки из данных дистанционного зондирования путем применения grid-вычислений. Эта цель достигнута за счет использования многоуровневой архитектуры, в которой на каждом уровне добавляются функциональные возможности, что позволяет получить надежный сервис с низкими эксплуатационными расходами.
RSIN содержит множество агентов. Каждое приложение запускает некоторый набор агентов, отвечающих за отслеживание ресурсов и управление ими, сбор статистики и планирование задач. Коды алгоритма сохраняются в RSIM в виде модулей. Модуль обработки данных занимается предварительной обработкой «сырых» данных, полученных со спутника, в то время как модуль модели обеспечивает реальную выборку количественных параметров. Для представления результирующих данных, администрирования и пользовательского доступа к системе в RSIN поддерживается графический интерфейс.
Оресте Вилла, Диниэле Паоло Скарпацца и Фабрицио Петрини (Oreste Villa, Politecnico di Milano, Daniele Paolo Scarpazza, Fabrizio Petrini, IBM T.J. Watson Research Center) представили статью «Ускорение поиска строк в реальном времени за счет использования многоядерных процессоров» («Accelerating Real-Time String Searching with Multicore Processors»).
Объем цифровых данных, которые производятся и распространяются в мире, возрастает взрывообразно. Важными проблемами становятся обеспечение доступа к данным и поиска в этой расширяющейся цифровой вселенной, а также ее защита от вирусов, вредоносных и шпионских программ, спама и попыток преднамеренного вторжения.
Системы обнаружения сетевых атак (intrusion detection system, IDS) больше не могут отфильтровывать нежелательный трафик с использованием только информации заголовков пакетов, поскольку угрозы часто нацеливаются на прикладной уровень; следовательно, в IDS должна использоваться глубокая проверка пакетов (deep packet inspection, DPI), включающая сопоставление информационного содержимого пакетов с базой данных сигнатур угроз. Однако при постоянно возрастающем числе угроз и повышающейся скорости каналов становится все сложнее выполнять DPI в реальном времени без воздействия на пропускную способность и время задержки наблюдаемой сети.
Имеется ряд алгоритмов, направленных на удовлетворение потребности в поиске и фильтрации информации. Эти алгоритмы лежат в основе поисковых машин, IDS, средств обнаружения вирусов, фильтров спама и систем мониторинга контента. Быстрые реализации поиска строк традиционно основываются на использовании специализированных аппаратных средств, таких как программируемые вентильные матрицы (field-programmable gate array, FPGA) и процессоры со специализированными системами команд (application-specific instruction-set processor), но появление многоядерных архитектур, подобных Cell Broadband Engine (CBE) компании IBM, добавляет в эту игру новых важных игроков.
Предыдущие исследования в области DPI, главным образом, фокусировались на скорости: достижении предельно высокой скорости обработки с использованием, как правило, небольшого словаря, включающего несколько тысяч ключевых слов. Позднее важным стало и второе измерение – размер словаря. Современная технология не позволяет создавать реализации с использованием словарей размером в сотни тысяч паттернов. Основной проблемой научного сообщества является обеспечение скорости доступа сканирования текстов, достигнутой при применении небольших словарей, при работе с гораздо большими наборами данных.
В 2007 г. авторы статьи представили параллельный алгоритм для CBE, основанный на детерминированном конечном автомате, который обеспечил пропускную способность поиска, превышающую 5 гигабайт в секунду в расчете на один синергический процессорный элемент (synergistic processing element, SPE). В совокупности восемь SPE, входившие в состав CBE, обеспечили пропускную способность в 40 гигабайт в секунду при использовании словаря из 200 паттернов и в 5 гигабайт в секунду при работе со словарем из 1500 паттернов. Хотя эта пропускная способность очень велика, ее можно достичь только при использовании небольших словарей, что делает данное решение бесполезным для многих приложений.
Позднее это решение было расширено возможностью использования более крупных словарей, для хранения которых применялась вся доступная основная память (1 гигабайт). Поскольку при доступе к основной памяти CBE возникают более длительные задержки, чем при работе с локальной памятью каждого SPE, основное внимание уделялось планированию обменов с основной памятью для повышения пропускной способности и сокращения времени ответа. С этой целью разрабатана стратегия параллелизации алгоритма поиска строк Ахо-Корасика (Aho-Corasick), которая позволяет добиться эффективности, сопоставимой с эффективностью известных алгоритмов, работающих с небольшими словарями, но использует сложную подсистему управления памятью CBE для эффективного управления большими словарями. Это показывает, что многоядерные процессоры являются жизнеспособной альтернативой специализированных решений и FPGA.
Следующую статью «Семантические запросы к большим биомедицинским наборам изображений» («Semantic Querying in Large Biomedical Image Datasets») написали Виджай Кумар, Сиварамакришнан Нараянан, Тахсин Курк, Джан Конг, Метин Гуркан и Джоэл Сальц (Vijay S. Kumar, Sivaramakrishnan Narayanan, Tahsin Kurc, Jun Kong, Metin N. Gurcan, Joel H. Saltz, Ohio State University).
Электронная микроскопия открывает новые возможности для изучения тканевых характеристик заболевания на клеточном уровне. Традиционно эксперт визуально исследует изображения ткани, классифицирует изображения и участки изображений и ставит диагноз. Этот процесс занимает много времени и сильно зависит от эксперта или воздействия на него других специалистов, что является стимулом к разработке компьютеризованных прогностических решений. Из-за огромного размера наборов изображений получение из них нужной информации является процессом, требующим эффективной системной поддержки.
Например, нейробластомы бывают периферийными нейробластическими опухолями и гораздо более распространенными внечерепными, солидными злокачественными опухолями, наносящими огоромный вред здоровью детей. У малолетних детей эта форма рака встречается чаще всего, и по этой причине были инициированы исследования по идентификации ее патологических характеристик и разработка компьютерных алгоритмов классификации, позволяющих использовать цифровые микроскопические изображения при получении характеристик и классификации тканей.
Мощный микроскоп может быстро получить из образца ткани изображение объемом 10-30 гигабайт. Клинические врачи обычно получают для изучаемого объекта несколько изображений, чтобы проводить продольные исследования или исследовать изменения на основе нескольких уровней ткани. Объем такого набора изображений достигает сотен гигабайт и даже терабайт.
Процесс прогнозирования нейробластомы с использованием цифровых микроскопических препаратов, по существу, является потоком работ, включающим последовательность шагов: сегментация изображения, выделение, выбор, извлечение, классификация признаков и аннотирование изображения и его участков. Выполнение этого потока работ над большим набором изображений может занять несколько часов (в некоторых случаях даже дней), что мешает эффективному компьютеризованному прогнозированию на основе анализа изображений.
При анализе изображений может обеспечиваться семантическая информация в виде аннотаций и классификаций. Например, случаи нейробластомы могут классифицироваться по типу ткани в разные гистологии на основе таких признаков, как нейробластическая дифференциация (подтипы недифференцированной, плохо дифференцированной и дифференцированной ткани) и наличие или отсутствие развития шванновских стром (ткань, бедная стромой, и ткань, богатая стромой).
Схема классификации может организовываться иерархическим образом. Во многих проектах исследователи стремятся к построению семантической базы данных на основе результатов анализа для поддержки более эффективной организации и агрегации информации об изображениях и интеграции этой информации с другими типами данных, такими как клинические и молекулярные данные, для проведения дальнейшего анализа. Крупномасштабные исследования в области семантической интеграции неоднородных данных на основе использования grid-технологий выполняются в проектах Biomedical Informatics Grid (caBIG), Cardiovascular Research Grid (CVRG), Biomedical Informatics Research Network (BIRN).
Авторы статьи предлагают свое решение двух проблем: аналитическая обработка крупных цифровых изображений и поддержка семантических запросов над большими наборами изображений. Это решение обеспечивается в контексте интегрированной архитектуры.
Авторами статьи «Аппаратные технологии для высокопроизводительных вычислений над большими объемами данных» («Hardware Technologies for High-Performance Data-Intensive Computing») являются Мая Гокхейл, Джонатан Кохен, Энди Ю, В. Маркус Миллер, Арпит Джакоб, Крейг Алмер и Роджер Пирс (Maya Gokhale, Jonathan Cohen, Andy Yoo, W. Marcus Miller (deceased), Lawrence Livermore National Laboratory, Arpith Jacob, Washington University in St. Louis, Craig Ulmer, Sandia National Laboratories, Roger Pearce, Texas A&M University).
Поскольку объемы научных и социальных данных продолжают расти, исследователи из множества прикладных областей сталкиваются с проблемами, связанными с хранением, индексированием, выборкой необработанных данных и синтезом на их основе практически полезной информации. В области вычислений с интенсивной обработкой данных большого объема, в которой комбинируются методы компьютерной науки, статистики и прикладной математики, разрабатываются и оптимизируются алгоритмы и системы, тесно взаимодействующие с данными большого объема.
Научные приложения, пишущие в большие наборы данных и читающие из них, часто выполняются недостаточно эффективно и плохо масштабируются на сегодняшних компьютерных системах. Многие приложения с интенсивной обработкой данных выполняются под управлением данных, из-за чего для них плохо работают аппаратные средства предсказания условных переходов и спекуляции. Эти приложения хорошо подходят для потокового доступа к данным, и они не могут эффективно использовать иерархию кэшей процессора. Возможности таких приложений к обработке больших наборов данных мешает громадная разница в пропускной способности дисковых подсистем, основной памяти и центральных процессоров.
Новые технологии могут на порядок улучшить производительность алгоритмов, ориентированных на работу с данными большого объема, по сравнению с текущим состоянием дел с приемлемыми временными расходами на разработку. Сопроцессоры, такие как графические процессорные модули (graphics processor units, GPU) и FPGA, могут значительно ускорить выполнение приложений некоторых классов, в которых доминируют вычисления под управлением данных. Кроме того, эти сопроцессоры взаимодействуют с внутрикристальной основной памятью, а не с традиционным кэшем.
С целью смягчения коэффициента 1:10, который отражает различие пропускной способности дисков и основной памяти, изучалась возможность построения системы ввода-вывода, построенной на основе большого параллельного массива твердотельных запоминающих устройств. Хотя такие массивы ввода-вывода содержат те же микросхемы, что и устройства USB, они обеспечивают существенно более высокую пропускную способностью и меньшую задержку, чем эти устройства, за счет параллельного доступа к массиву устройств.
Для количественной оценки достоинств этих технологий был создан небольшой набор тестов с интенсивной обработкой данных, основанный на приложениях из областей анализа данных и науки. Тесты работают с данными трех типов: научные изображения, неструктурированный текст и семантические графы, представляющие сети связей. Полученные результаты показывают, что при расширении возможностей потребительских процессоров этими технологиями эффективность приложений существенно возрастает.
Последняя статья тематической подборки называется «ProDA: сквозная, основанная на вейвлетах OLAP-система для крупных наборов данных» («ProDA: An End-to-End Wavelet-Based OLAP System for Massive Datasets») и написана Кирусом Шахаби, Мердадом Джахангири и Фарнушем Банаи-Кашани (Cyrus Shahabi, Mehrdad Jahangiri, Farnoush Banaei-Kashani, University of Southern California).
Последние достижения в технологиях зондирования и сбора информации позволяют накапливать крупные наборы данных, в деталях представляющих сложные события и сущности реального мира. Имея доступ к таким наборам данных, ученые и системные аналитики больше не обязаны прибегать к моделированию и симуляции при анализе событий реального мира. Предпочтительным подходом становятся наблюдения и проверка гипотез путем аналитического исследования представительных наборов данных, в которых зафиксировано соответствующее событие. Для применения этого подхода требуются интеллектуальные решения по поводу хранения данных, обеспечения доступа к ним и поддержки аналитических запросов, а также инструментальные средства, содействующие удобному и эффективному исследованию этих громадных наборов данных. Это одновременно предоставляет благоприятную возможность сообществу баз данных и ставит перед ним сложную проблему , см. также).
Разработчики умышленно оптимизируют традиционные СУБД для выполнения транзакционных, а не аналитических запросов. Эти СУБД поддерживают только несколько базовых видов аналитических запросов, причем не с оптимальной эффективностью. Поэтому предоставляемые этими СУБД возможности не являются достаточными для анализа крупных наборов данных. На практике при исследовании данных распространено использование средств обработки аналитических запросов, поддерживаемых в приложениях электронных таблиц, таких как Microsoft Excel и Lotus 1-2-3. Однако ограничением является то, что эти приложения не могут справляться с большими наборами данных. Приходится хранить исходные наборы данных на сервере баз данных и выбирать для локальной обработки с применением приложений электронных таблиц на стороне клиента сокращенные поднаборы данных (путем взятия образцов, агрегации или классификации данных).
Этот неудобный и трудоемкий процесс создания вторичного набора данных может привести к потере важной детальной информации. При использовании этого подхода аналитики будут склоняться к тому, чтобы подтверждать на основе выбранных данных свои собственные предположения, а не стремиться к обнаружению в исходных данных скрытых неожиданных фактов. Кроме того, поскольку анализ в основном производиться на стороне клиента, возрастают накладные расходы на пересылку данных, не используется возможность совместного использования ресурсов сервера, и на стороне клиента требуются значительные вычислительные возможности.
Средства оперативной аналитической обработки (online analytical processing, OLAP) направлены на снятие ограничений традиционных баз данных и приложений электронных таблиц. В отличие от традиционных СУБД OLAP-системы поддерживают сложные аналитические запросы. В отличие от приложений электронных таблиц, средства OLAP могут работать с очень большими наборами данных. Кроме того, OLAP-системы могут обрабатывать пользовательские запросы в оперативном режиме, что, вероятно, является обязательным условием эффективной поддержки запросов, используемых в целях исследования данных. Однако современные средства OLAP при обеспечении оперативной обработки запросов активно используют предварительно вычисляемые частичные результаты запросов. Поэтому в действительности они могут поддерживать оперативную обработку лишь ограниченного набора заранее определенных (а не произвольных) запросов.
За последние пять лет авторы спроектировали, разработали и довели до работоспособного состояния сквозную аналитическую систему ProDA (progressive data analysis system), которая позволяет эффективно анализировать большие наборы данных. ProDA – это клиент-серверная система с трехуровневой архитектурой. На нижнем уровне системы поддерживается хранение данных, на среднем уровне обрабатываются запросы. В совокупности эти два уровня составляют серверную часть ProDA. В клиентской части ProDA располагается уровень визуализации, обеспечивающий формулировку запросов и представление их результатов.
В качестве средства OLAP ProDA поддерживает широкий набор аналитических запросов над большими наборами данных. По сравнению с традиционными средствами OLAP, в ProDA обеспечиваются расширенные и усовершенствованные возможности оперативного выполнения аналитических запросов за счет применения собственной технологии, основанной на использовании вейвлетов .
Более точно, в ProDA поддерживаются более сложные аналитические запросы, включая все семейство полиномиальных агрегатных запросов и класс графовых запросов (plot query), которые раньше не поддерживались в OLAP-системах. Кроме того, в отличие от традиционных средств OLAP, в ProDA поддерживаются произвольные оперативные запросы. Для обеспечения эффективного оперативного выполнения произвольных запросов, во-первых, аналитические запросы выполняются не в клиентских приложениях, а на стороне сервера, поблизости от данных. Во-вторых, используются замечательные свойства вейвлетных преобразований, позволяющих точно аппроксимировать результаты запросов при минимальном числе доступов к исходным данным. Новшество состоит в том, что преобразуются и запросы, и данные. Свойство переменной разрешающей способности вейвлетных преобразований позволяет аппроксимировать результаты запросов либо с заданной точностью, либо с заданным временем выполнения запроса.
Вне тематической подборки опубликована статья «Использование сопоставления строк для глубокой проверки пакетов» («Using String Matching for Deep Packet Inspection»), авторами которой являются По-Чинг Лин, Йинг-Дар Лин, Юань-Ченг Лай и Церн-Хью Ли (Po-Ching Lin, Ying-Dar Lin, Yuan-Cheng Lai, National Taiwan University of Science and Technology, Tsern-Huei Lee, National Chiao Tung University).
Классические алгоритмы сопоставления строк оказались полезными для глубокой проверки сетевых пакетов (deep packet inspection, DPI) с целью обнаружения вторжений, для поиска вирусов и для фильтрации Internet-контента. Однако для успешного применения необходимо усовершенствовать эти алгоритмы, добившись их эффективности при работе с многогигабайтными данными и масштабируемости при использовании больших объемов сигнатур.
До 2001 г. исследователей в области обработки пакетов более всего интересовали методы сопоставления по наиболее длинному префиксу (longest-prefix matching) в таблицах маршрутизации марштрутизаторов Internet и классификации пакетов по нескольким полям (multifield packet classification) заголовка пакетов для брандмауэров и приложений поддержки качества обслуживания. Однако теперь наибольший интерес представляют DPI для разных видов сигнатур.
В приложениях обнаружения вторжений, поиска вирусов, фильтрации контента, управления мгновенными сообщениями и идентификации однорангового трафика (peer-to-peer identification) для проверки может использоваться сопоставление строк. Для ускорения этой проверки, сокращения области хранения паттернов и эффективной обработки регулярных выражений выполнено много работы как в области разработки алгоритмов, так и в направлении аппаратных реализаций.
Анализ последних публикаций, доступных в электронных библиотеках IEEE Xplore и ACM DL, показывает, что исследователи раньше в большей степени интересовались чистыми алгоритмами, пригодными в теоретических целях или в приложениях общего назначения. Позднее они стали проявлять больший интерес к алгоритмам, применимым для DPI. Аналогично, в ответ на требования повышенной скорости обработки исследователи фокусируются на аппаратных реализациях на основе специализированных интегральных схем (application-specific integrated circuit, ASIC) и программируемых вентильных матриц (field-programmable gate array, FPGA), а также на возможностях использования параллельных микропроцессоров. С 2004 г. в изданиях ACM и IEEE были опубликованы 34 статьи по тематике ASIC и FPGA, в то время как за все 1990-е годы было опубликовано всего девять статей на эту тему, и девять же статей были опубликованы в промежутке в 2000 по 2003 гг. По поводу мультипроцессоров с 2004 г. было опубликовано 10 статей, столько же, что и за все 1990-е годы, а в период с 2000 по 2003 гг. на эту тему появились всего три статьи.
В данной статье приводится обзор последних достижений в области сопоставления строк.

 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС

