Стремительное разрастание Всемирной паутины и связанное с этим увеличение объема трафика продолжают беспокоить специалистов. Web-серверы стали не только хранилищем текстовой и графической информации, но и местом гигантских залежей видео- и аудиоматериалов, а также средством проведения масштабных коммерческих операций. На первый план выходит задача обслуживания запросов за гарантированное время, что неизбежно требует усовершенствованных технических, алгоритмических и программных средств построения распределенных Web-серверов.

Согласно данным компании Nortel Networks, число пользователей систем электронной коммерции возрастет с 142 млн. в 1999 году до 500 млн. в 2003-м, а суммарный финансовый оборот составит в 2003 году свыше 1 трлн. долл. При таком росте Сети главной заботой Web-разработчиков становится необходимость вовремя обслужить запрос клиента. Поиск решения приводит к идее распределенного Web-сервера.
Web-кластеры стали объектом пристального изучения ИТ-менеджеров, инженеров-сетевиков, математиков. Об этом свидетельствует нарастающий из года в год поток публикаций, появление экспериментальных систем в университетах и научных центрах, интенсивно развивающийся рынок так называемых аспределителей нагрузкиispatcher, load balancer), формирование терминологии. Однако на русском языке вышло крайне мало публикаций [1], а немногие переводные написаны, как правило, специалистами по менеджменту и носят рекламно-публицистический характер. Между тем, организация распределенного Web-сервера остаточно сложная задача, требующая детальной проработки ряда вопросов:
- анализа сетевого трафика и ожидаемой загрузки сервера;
- выбора архитектуры распределенной системы;
- маршрутизации пакетов внутри системы;
- функциональности распределителей нагрузки;
- дисциплины обслуживания запросов и выбора сервера;
- распределения хранимой информации.
Потоки данных в WWW
На протяжении нескольких десятилетий при анализе моделей, возникающих в теории вычислительных систем, исследователи привыкли считать входные потоки пуассоновскими, а распределения длин заявок кспоненциальными. Такие предположения позволяют строить марковский процесс и получать аналитические результаты, которые носят если и не предсказательный, то хотя бы объясняющий характер. Разумеется, когда в первой половине 90-х годов специалисты занялись моделированием столь сложной структуры, как Всемирная паутина, не мог не возникнуть вопрос, насколько эти предположения близки к реальности. Основополагающей явилась работа [9], авторы которой показали, что потоки в Web описываются не пуассоновскими, а иными законами распределения тяжелым хвостомeavy-tailed) или степенными.
Такие распределения описываются зависимостью Pr(X>x)~x-a, 0<a<2, Pr(X>x) ероятность превышения случайной величиной аданного числа Для подобного распределения характерно бесконечное значение дисперсии, а при a<1 бесконечное математическое ожидание. Кроме того, оказывается, что большая часть загрузки приходится на очень малую часть (<1%) линныхнтервалов.
Типичными примерами распределения с яжелым хвостомвляются распределения Парето и Вейбулла. Приведем оценки параметра a для некоторых характеристик, подчиняющихся распределению Парето (меньшее значение параметра соответствует большей выраженности свойств случайной величины):
- размеры файлов, передаваемых по протоколу HTTP: 1,1<a<1,3;
- размеры файлов, передаваемых по протоколу FTP: 0,9<a<1,1.
Авторы работы [5] собрали статистику по множеству запрашиваемых файлов (могут запрашиваться многократно), множеству передаваемых с сервера файлов (не обнаруженные в кэше и повторные файлы), множеству уникальных файлов. На ее основании был сделан вывод, что размеры файлов в каждом из множеств хорошо описываются распределением Парето. Более полная классификация статистических данных приведена в [2], где введено понятие инвариантов, т.е. характеристик, отражающих особенности некоторой целостной совокупности данных в Web:
- доля успешных обращений составляет 88%, остальное - отсутствие документа на сервере или прав доступа к нему;
- HTML-файлы и графические файлы составляют от 90% до 100%;
- средний размер передачи - 21 Кбайт;
- список файлов без повторов - менее 3% от общего числа передаваемых файлов;
- распределение размера файла - Парето, 0,4<a<0,63;
- концентрация ссылок - на 10% файлов приходится до 90% запросов, которые составляют 90% трафика;
- география - обращения из 10% от общего числа доменов составляют свыше 75% всех обращений.
Неравномерность распределения показателей загрузки можно почерпнуть и из собственного опыта. Например, за июнь 2002 года с официального Web-сервера администрации Сургута было осуществлено 73740 запросов страниц; если их упорядочить по убыванию числа посещений, то получится список без повторов из 6616 HTML-файлов, причем 36194 запросов приходится на первые 61 файл. Таким образом, в этом случае менее чем на 1% файлов приходится свыше 50% запросов.
Так называемое ремя обдумыванияhinking time) ромежуток между получением ответа и новым запросом акже распределено по закону Парето. Это же распределение применимо к количеству гипертекстовых ссылок, ведущих на данную страницу (inbound) и со страницы (outbound).
DNS
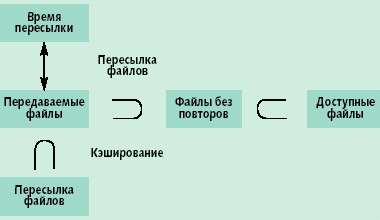
Один из наиболее простых способов разделения нагрузки между несколькими серверами состоит в использовании циклической дисциплины Round-Robbin DNS (RR-DNS).
|
|
Рис. 1. Распределение нагрузки с помощью Round-Robbin DNS
|
Этот способ не требует наличия выделенного распределителя нагрузки, функцию которого выполняет DNS-сервер. Сервер, обслуживающий зону, в которой расположен кластер, циклически производит разрешение одного и того же доменного имени на различные IP-адреса, соответствующие хостам из кластера. Данный подход достаточно хорошо изучен и наряду с главным достоинством, простотой, обладает рядом очевидных недостатков [4].
- RR-DNS не учитывает текущие характеристики серверов (загрузка, доступность, время отклика) и не может динамически подстроиться к меняющемуся состоянию системы.
- Наличие промежуточных кэширующих DNS-серверов, которые обслуживают запрос на разрешение доменного имени и возвращают предыдущий IP-адрес, а не измененный RR-DNS, подрывает саму идею разделения нагрузки, приводя к дисбалансу. Действительно, при этом в течение длительного времени последовательности запросов могут направляться на один и тот же сервер.
Бороться со вторым недостатком можно путем настройки управляющего параметра TTL (Time-to-Live), задающего время изниаписи в DNS-кэше. Установка TTL равным нулю исключает эффект кэширования, но тогда DNS-сервер может стать узким местом сетевого трафика. В [10] показано, что без кэширования время разрешения доменного имени становится на два порядка выше. Можно подстраивать TTL для каждой записи с учетом частоты запросов, но далеко не очевидно как это делать с максимальным эффектом. Замечен еще один недостаток DNS-подхода еявное предположение, что клиент и его локальный name-сервер расположены поблизости. Однако это не всегда так. Поэтому временная задержка на name-сервере не всегда правильно отражает задержку клиента. DNS-подход в условиях большой загрузки и разнообразия типов запросов сам по себе не может гарантировать решения проблемы балансировки; для этого нужны более тонкие дисциплины.
Дисциплины с распределителями нагрузки
Главную роль в Web-кластере, играет распределитель нагрузки, принимающий решение о дальнейшем движении каждого запроса. При этом весь Web-кластер представлен для внешнего наблюдателя только одним IP-адресом иртуальным IP (VIP). Кратко упомянем о механизмах маршрутизации пакетов внутри Web-кластера [1, 3, 4]:
- Однонаправленная маршрутизация (one-way routing). Распределитель нагрузки подменяет в пакетах собственный IP-адрес IP-адресом выбранного сервера. Ответ сервера возвращается клиенту напрямую, без участия распределителя нагрузки. Web-сервер заменяет свой IP-адрес на VIP, чтобы ответ исходил из адреса, на который был послан запрос. Это позволяет разгрузить распределитель нагрузки (выходной поток значительно превышает входной), но требует изменений в коде операционной системы сервера, поскольку подмена IP-адреса происходит на уровне TCP/IP.
- Двунаправленная маршрутизация (two-way routing). Выходной поток от сервера идет через распределитель нагрузки, который в этом случае выполняет обе подстановки адреса. При таком подходе распределитель нагрузки становится узким местом сети.
- Маршрутизация через распределитель нагрузки (packet forwarding by the dispatcher). Подход реализован в IBM Network Dispatcher [7]. Пересылка пакетов серверу происходит на уровне MAC-адреса, без изменения заголовка IP-пакета, для которого в данном случае не нужно перевычислять контрольные суммы. Распределитель нагрузки и серверы должны находиться в одном сетевом сегменте.
Серийно выпускаемые устройства используют, как правило, простые дисциплины обслуживания, а в экспериментальных устройствах применяются методы моделирования. Однако в любом случае должны соблюдаться следующие требования: приемлемая вычислительная сложность; совместимость с протоколами и стандартами Web; доступность распределителю нагрузки всей необходимой для принятия решения информации.
Применяемые алгоритмы диспетчеризации можно разделить на статические и динамические. В последнем случае распределитель нагрузки осуществляет периодический мониторинг серверов, входящих в кластер и выбирает для направления запроса наилучший из них. В статических алгоритмах состояние серверов не отслеживается. Выбор алгоритмов зависит от многих факторов. Повышенная нтеллектуальностьинамических алгоритмов влечет накладные расходы, связанные со сбором информации с хостов, однако выбор дисциплины обслуживания во многом зависит не только от характера трафика, но и от функциональности распределителя нагрузки. Принято классифицировать их на устройства уровня 4 и уровня 7 (рис. 2).

|
|
Рис. 2. Различия в порядке обмена информацией между клиентом, распределителем нагрузки и Web-кластером для уровней 4 и 7 (SYN апрос на соединение, ACK одтверждение соединения)
|
Распределитель нагрузки уровня 4 анализирует пакеты только на уровне TCP/IP, не доходя до уровня приложения, не принимая во внимание HTTP-запрос при перенаправлении пакета на сервер. Такой механизм называют лепым к содержаниюontent-blind) или емедленным связываниемmmediate binding). Распределитель нагрузки уровня 7 принимает решение о маршрутизации запроса только при получении HTTP-пакета. При этом, проведя анализ URL, такие устройства могут учесть тип запроса, оценить его трудоемкость и определить, на каком сервере находится нужный ресурс. Этот механизм называют утким к содержаниюontent-aware) или тложенным связываниемelayed binding) [8]; его поддерживают многие коммерческие продукты [3]. Разумеется, дисциплины второго типа следует отнести к динамическим. С другой стороны, применение уровня 7 оправданно, если его возможности используются дисциплиной обслуживания, поэтому вполне естественно, что статические дисциплины реализуют только распределители нагрузки уровня 4, а динамические ак те, так и другие.
К статическим дисциплинам относятся Random и Round Robbin. В Random сервер выбирается случайным образом с помощью равномерного распределения. Дисциплина Round Robbin реализует принцип циклического перебора, который в чистом виде выглядит так: i-ая по счету заявка поступает на сервер с номером, равным остатку от деления i на N, где N оличество серверов.
Для любой динамической дисциплины возникает задача выбора управляющих параметров, которая не всегда может быть решена точно. В качестве критерия эффективности обычно принимают два показателя:
- время пребывания заявки на сервере (waiting time);
- замедление (slowdown), т.е. отношение времени пребывания к длине заявки (во сколько раз замедляется обслуживание запроса из-за наличия очереди).
Наиболее естественными динамическими дисциплинами являются:
- Least Loaded (LL) - выбор сервера по критерию наименьшей загрузки его ресурсов (процессор, память, диск, количество очередей сообщений);
- Least Connected (LC) - выбор сервера по критерию наименьшего числа текущих открытых TCP/IP-соединений;
- Fast Response (FR) - выбор сервера по критерию самого быстрого ответа на тестовый запрос от распределителя нагрузки;
- Weighted Round Robbin (WRR) - при циклическом переборе каждому серверу, в отличие от статической дисциплины RR, передается подряд не один запрос, а несколько, в соответствии с весом сервера, пропорциональным, скажем, его текущей загрузке [7].
Все эти дисциплины лепы к содержанию не требуют анализа HTTP-запроса. В сравнительном исследовании дисциплин WRR, LC и LL по среднему времени ответа и загрузке серверов лучше всего показала себя дисциплина LL. При низкой и средней загрузке WRR ведет себя гораздо хуже динамических дисциплин, а время ожидания для LC в среднем в 6 раз больше, чем для LL. С ростом нагрузки производительности сходятся, причем показатели LC стремятся к показателям LL гораздо быстрее, чем WRR. Неудивительно, что, раз LL оказалась лучше, то легче реализовать LC, поскольку для LL требуется более интенсивный обмен служебной информацией между распределителем нагрузки и серверами. Из этого анализа следует, что вопрос о том, какая из перечисленных динамических дисциплин наиболее эффективна, имеет скорее теоретическое значение. На практике же этот выбор не оказывает сколько-нибудь определяющего влияния на производительность Web-кластера.
Универсальный подход к использованию динамических дисциплин типа content-blind реализован в IBM Network Dispatcher [7]. Авторы ввели понятие ндекса загрузкиad Metrics Index (LMI) и разделили показатели качества работы системы на три класса.
- Input - вычисляются локально в РН, например, количество соединений, установленных с сервером за последние t единиц времени.
- Host - вычисляются на каждом сервере, например, загрузка сервера.
- Forward - вычисляются путем сетевого взаимодействия распределителя нагрузки с сервером. Эти характеристики доставляют специальные скрипты-агенты, например, подача HTTP-запроса "GET /" и измерение времени ответа.
Далее, по вектору LMI для каждого сервера вычисляются значения функции WCF (Weight Computation Function), и выбирается сервер с наибольшим значением. Программное обеспечение диспетчера состоит из трех компонентов visor, Manager и Executor. Первый компонент опрашивает серверы и собранную информацию передает на второй для вычисления WCF; третий производит маршрутизацию пакетов. Открытыми остаются вопросы динамического подстраивания весов для WCF, а также оптимального значения периодичности обновления LMI.
Параметр LMI весьма важен. Дело в том, что информация о состоянии серверов при интенсивном входном потоке может быстро устареть и оказаться не просто бесполезной, но и вредной для распределителя нагрузки. Известен так называемый ффект стадакогда аилучшемуа данный момент серверу подряд пересылается много запросов и он быстро становится худшим адолго до следующего сбора информации о состоянии, когда можно будет что-то изменить. Методам предотвращения такой ситуации посвящено немало работ. Некоторые из них пытаются учесть озрастнформации о загрузке серверов. Если информация свежая, следует использовать динамическую дисциплину, иначе татическую. Допустим, после опроса состояния N серверов упорядочены по возрастанию числа активных соединений, и сервер для поступающих запросов выбирается среди первых k случайным образом. Очевидно, что k=1 соответствует динамической дисциплине LC, k=N татической дисциплине Random. Период T между двумя последовательными опросами состояния делится на N интервалов, и на j-ом интервале нагрузка делится между первыми j серверами. По мере старения информации происходит постепенный переход от полностью динамической дисциплины к полностью статической.
Для всех рассмотренных дисциплин решение принимается только на основании информации от сервера, но и информация клиента тоже может учитываться. Это характерно при поддержке свойства client affinity, под которым понимается последовательное направление запросов от одного клиента одному и тому же серверу [3]. Такой прием во многих случаях позволяет повысить производительность и функциональность системы.
Перейдем теперь к рассмотрению дисциплин, относящихся к классу content-aware. Наиболее простой из них является Cache Affinity [3], в соответствии с которой файлы распределяются между серверами с помощью хэш-функции. Ту же функцию использует и распределитель нагрузки, обеспечивая адресность обращений. Однако во-первых, такая дисциплина пригодна лишь для статического содержимого, во-вторых, игнорирует балансировку загрузки.
Рассмотрим алгоритмы, так или иначе принимающие во внимание трудоемкость и ресурсоемкость запроса. При этом предположение о статистических свойствах длин поступающих запросов приводит к уточнению традиционных представлений о балансировке нагрузки. Некоторые исследователи отмечают, что стремление равномерно загрузить серверы не соответствует структуре потоков в Internet, и можно использовать дисциплину SITA-V (Size Interval Tasks Assignment-Variable), согласно которой егкиеадачи посылаются на хост с меньшей загрузкой, а яжелые большей. Так как при степенном распределении егкихадач больше, а яжелыхеньше, эффективность метода возрастает с уменьшением параметра a. Случается, что среднее замедление снижается более чем в 100 раз по сравнению с дисциплиной равномерной загрузки, однако среднее время ожидания при этом возрастает. Кроме того, вычисление точек разбиения длин заявок на интервалы, позволяющие отличить егкиеадачи от яжелыхносит оценочный характер.
Следующим шагом стала работа [6], где была рассмотрена дисциплина SITA-E (здесь E т equal). Ее отличие от SITA-V заключается в том, что в ней для точек разбиения предложена точная формула: если требуется разделить входной поток заявок между N серверами, N-1 точек находятся из интегрального соотношения, выражающего условие равенства интервалов длин заявок, взвешенных по вероятности в соответствии с плотностью распределения. Заявки, длины которых лежат в пределах i-го интервала, направляются на i-ый сервер.
Оценка эффективности метода основывалась на сравнении дисциплин FCFS (ервым пришел ервым обслужени PS (азделение процессораВ FCFS обслуживается только одна заявка, а остальные ждут в очереди; в PS очереди как таковой нет, поскольку ресурс процессора делится на все присутствующие в системе заявки в режиме квантования времени. Математический анализ дисциплины PS значительно сложнее анализа FCFS, но насколько эти усилия оправданы? Авторы [6] приходят к интересному выводу: в случае применения в распределителе нагрузке алгоритма SITA-E, казалось бы, досконально изученная дисциплина FCFS вдвое превосходит PS по времени ответа и замедлению. Системы пакетной обработки всегда были эффективнее с точки зрения использования ресурсов, чем системы разделения времени: на переключение тратятся системные ресурсы.
В дальнейших исследованиях алгоритма SITA-E каждый сервер обрабатывал запросы в соответствии с FCFS, длина заявки предполагается известной распределителю нагрузки. Был проведен сравнительный анализ трех дисциплин: Round Robbin, Random и Dynamic Least Work Remaining (в последнем случае запрос передается серверу с минимальной остаточной работой, близко к LC) и сделан вывод: ни одна из дисциплин не является наилучшей во всех случаях. Когда дисперсия не очень велика, динамическая дисциплина лучше остальных, но ее эффективность падает с приближением дисперсии к данным реальных измерений трафика.
Еще более математически насыщенным стал алгоритм балансировки ETAQA, для которого распределение Парето было представлено в виде суммы экспоненциальных случайных величин (т.е. приближено гиперэкспоненциальным распределением с порядком k), и предложен метод расчета количества серверов, обслуживающих каждую экспоненциальную фазу.
Однако построенные модели и сделанные выводы оказались больше интересны для математиков, чем для практиков. Причина в том, что трудно заранее точно определить длину заявки. Если к статическим запросам эти модели еще можно как-то приложить, то к динамическим SITA-E вряд ли будет уместен. В одной из работ авторы SITA-E предложили алгоритм TAGS (Task Assignment Based on Guessing Size), хорошо работающий для потоков заявок с большой дисперсией и неизвестной заранее длиной заявки, которая определяется динамически. Сначала она поступает на обслуживание на первый сервер. Если s1 единиц времени оказалось недостаточно для завершения обслуживания, процесс прерывается, и заявка ставится в очередь ко второму серверу, где ее обслуживание начинается с начала и т.д. TAGS, таким образом, достигает приблизительно тех же целей, что и SITA-E, но без априорной информации о длине заявки. Для реализации этой дисциплины не требуется анализа HTTP-заголовка и наличия распределителя нагрузки. Однако непонятно, сколько необходимо серверов, чтобы снизить среднее замедление до заданного уровня. Неясно и то, как оптимально выбрать последовательности si.
В ряде работ делается общий вывод: эффект от использования динамических алгоритмов сказывается лишь в том случае, когда время обработки большинства запросов на три или более порядков выше времени обработки простых запросов к HTML-страницам. Иначе, при быстродействии современных компьютеров разница в производительности почти не ощущается, и сложные алгоритмы, требующие накладных расходов на реализацию, не нужны.
В другом исследовании предложена дисциплина MC-RR (Multi Class Round Robbin) для устройств уровня 7. Ее цель лучшить разделение нагрузки для Web-кластеров, выполняющих статические и динамические запросы. Все возможные запросы разделены по ожидаемому влиянию на сеть, процессор и диск: статические и егкиеинамические; с высокой нагрузкой на диск; с высокой нагрузкой на процессор; с высокой нагрузкой на диск и процессор. Заявки первого класса характерны для систем Web-публикаций, остальные ля обработки Web-транзакций и мультимедийных Web-приложений. Внутри каждого класса заявки обслуживаются согласно дисциплине RR. Основная идея алгоритма состоит в том, что распределитель нагрузки хотя и не может точно вычислить длину заявки, но может определить ее класс. С небольшими модификациями метод MC-RR известен также как CAP (Client-Aware Policy).
Существует и принципиально иной подход, не учитывающий ни длину заявки, ни загрузку серверов. Выбор сервера делается на основании домена клиента, а не текущей загрузки серверов, более того, попытка учесть в алгоритме серверную информацию часто ведет к ухудшению производительности. Поэтому домены делятся на классы по интенсивности потоков запросов из них, и к каждому классу отдельно применяется Round Robbin. Цель редотвратить концентрацию запросов из орячихоменов на одном сервере. Учитывается также число назначений каждому серверу из каждого домена, однако сбор характеристик с серверов может ухудшить производительность, поэтому предложено учитывать их состояние при реализации оменныхисциплин в усеченной форме, например, исключить из текущего рассмотрения серверы, приславшие сигнал о перегрузке. При получении же диспетчером сигнала о реактивации, сервер, пославший его, вновь включается в кластер.
Приведенный перечень дисциплин обслуживания, ориентированных на распределитель нагрузки, конечно, далек от полноты. Так, ничего не было сказано про использование кэша. Например, в ряде работ имеется обоснование применения кэша для хранения результатов CGI-запросов.
Дисциплины без распределителя нагрузки
При отсутствии распределителя нагрузки IP-адрес каждого сервера видим извне, и назначение сервера для обработки поступившего запроса происходит на уровне RR-DNS, однако выбранный сервер может принять решение о перемещении запроса. Рассмотрим возможные механизмы маршрутизации.
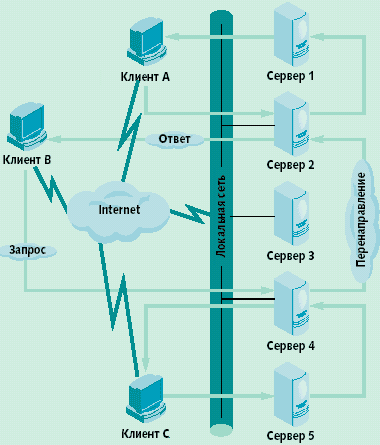
- Триангуляция. Работает на уровне TCP/IP. Первый из серверов, установивший соединение, решает, обслуживать этот запрос самому или переслать его другому серверу. В последнем случае новый сервер распознает, что пакет был перенаправлен, и отвечает непосредственно клиенту. Последующие пакеты этого TCP-соединения продолжают поступать на первый сервер и перенаправляться. Клиент и два сервера образуют треугольник, что и объясняет название метода (рис. 3).
- HTTP-перенаправление. Работает на уровне HTTP. Первоначально выбранный сервер возвращает клиенту новый URL и код ответа 301, предлагающий запросить искомый ресурс по новому URL. Просмотрщик устанавливает новое TCP-соединение с другим сервером. Это увеличивает "сетевую" часть времени задержки ответа, но во многих случаях может быть компенсировано более быстрой обработкой запроса на новом сервере, особенно, если первый перегружен. Просмотрщики, однако делают этот механизм видимым для пользователя, меняя поле ввода URL, что может ввести пользователя в недоумение.
|
|
Рис. 3. Перенаправление запросов с использованием механизма триангуляции
|
Преимущества выбора дисциплины обслуживания без распределителя нагрузки (децентрализованная архитектура) могут заключаться в том, что устраняется потенциально узкое место в системе, и выход из строя любого сервера не приводит к ее остановке. Вместе с тем, по объему функциональных возможностей децентрализованная система, конечно, не может сравниться с тем, что обеспечивает, например, Cisco Director или IBM Network Dispatcher.
Размещение информации
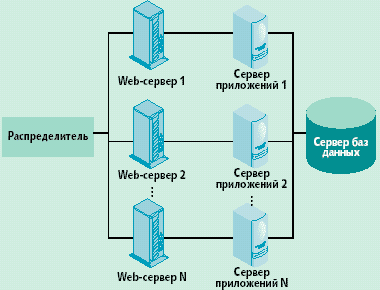
Эффективность функционирования распределенного Web-сервера во многом зависит и от того, каким образом внутри него размещена информация. Проблема размещения данных порождает интересные задачи дискретной оптимизации, при этом различают размещение файлов и видов служб. В первом случае на полярных позициях находятся полное дублирование всей информации на каждом сервере и полное разделение, когда все множество файлов делится на N непересекающихся подмножеств. Первое решение неэкономично, второе ненадежно и не гарантирует балансировки загрузки дни файлы более популярны, чем другие. Наилучшим решением обычно является дублирование одного множества файлов и разделение другого. В этой связи возникают задачи оптимального разбиения содержимого сервера на подмножества и выбора количества копий. Наконец, существуют алгоритмы, предусматривающие динамическую миграцию документов между хостами. Что же касается генерации и распределения динамического содержимого, то эффективность планирования работ во многом определяется бизнес-логикой и технологиями разработки Web-приложений. Общих тенденций здесь немного. Исследования, посвященные планированию Web-приложений, в основном направлены на модификацию многозвенных Web-кластеров (рис. 4). Здесь серверы приложений реализуют бизнес-логику и выступают в качестве связующего звена между Web-сервером и сервером баз данных.
|
|
Рис. 4. Схема многозвенного кластера для обслуживания Web-транзакций
|
Заключение
Научные основы оптимального выбора дисциплины обслуживания еще далеко не сложились, причем это в равной степени относится и к другим задачам, связанным с Web-кластерами. Когда речь идет о моделировании Internet-систем, каждое решение имеет довольно узкую область применимости, границы которой быстро могут стать еще уже, поскольку сегодняшняя Сеть е то же самое, что Сеть завтрашняя. Разнообразие подходов, методов, оценок требует систематизации, первой попыткой которой была работа [3]. Возможно, когда-нибудь появится общая теория, сводящая разрозненные решения в единое целое. Но пока вопросов гораздо больше, чем ответов.
Литература
- Либман Л. Философия распределения нагрузки. - Журнал сетевых решений LAN, 2000.
- Arlitt M.F., Williamson C.L. Web Server Workload Characterization: The Search for Invariants. - In Proceedings of the ACM SIGMETRICS '96 Conference, Philadelphia, PA, 1996. Apr.
- Cardellini V., Casalicchio E., Colajanni M., Yu P.S. The State of the Art in Locally Distributed Web-server Systems. - IBM Research Report, RC22209 (W0110-048), 2001, October.
- Cardellini V., Colajanni M., Yu P.S. High-Performance Web-server Systems. - IEEE, Internet Computing, 1999, May-June.
- Crovella M. E., Taqqu M.S., Bestavros A. Heavy-Tailed Probability Distributions in the World Wide Web. - In A Practical Guide To Heavy Tails, chapter 1, Chapman & Hall, New York.
- Harchol-Balter M., Crovella M., Murta C. To queue or not to queue?: When FCFS is better than PS in a distributed system. - Technical Report, CS Department, Boston University, Number 1997-017, 1997 October 31.
- Hunt G., Goldszmidt G., King R., Mukherjee R. Network Dispatcher: a connection router for scalable Internet service. - Computer Networks and ISDN Systems, Vol. 30, 1998.
- Hunt G., Nahum E., Tracey J. Enabling content-based load distribution for scalable services. - Technical report, IBM T.J. Watson Research Center, May 1997.
- Paxson V., Floyd S. Wide-area Traffic: The Failure of Poisson Modeling. - IEEE/ACM Transactions on Networking, 1995 June.
- Shaikh A., Tewari R., Agrawal M. On the Effectiveness of DNS-based Server Selection. - Proceedings of IEEE INFOCOM '01, Anchorage, Alaska, 2001 April.
Илья Труб (root@surgu.wsnet.ru) аведующий лабораторией сетевых технологий Сургутского государственного университета.



 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС